郊区的通勤用减法聚类和简称ANFIS模型
这个例子展示了如何生成模型汽车旅行的数量之间的关系从一个地区,该地区的人口使用减法聚类和简称ANFIS调优。
负载流量数据
这个示例使用人口和旅行100流量分析的数据区在纽卡斯尔县,特拉华州。数据集包含五个人口因素作为输入变量:人口数量的住宅单位,车辆所有权,中等家庭收入和就业总人数。数据包含一个输出变量数量的汽车旅行。
负荷训练和验证数据。
负载trafficData
75数据集包含100数据点,训练和25进行验证。的训练输入数据(datain)和验证输入数据(valdatain)各有5个列表示输入变量。训练输出数据(dataout)和验证输出数据(valdataout)各有一列表示的输出变量。
情节的训练数据。
h =图;h.Position (3) = 1.5 * h.Position (3);次要情节(1、2、1)情节(datain)传说(“人口”,“住宅”,“车辆所有权”,…“中等收入”,“就业总人数”,“位置”,“西北”)标题(输入变量的)包含(的数据点次要情节(1、2、2)情节(dataout)传说(“旅行”)标题(“输出变量”)包含(的数据点)
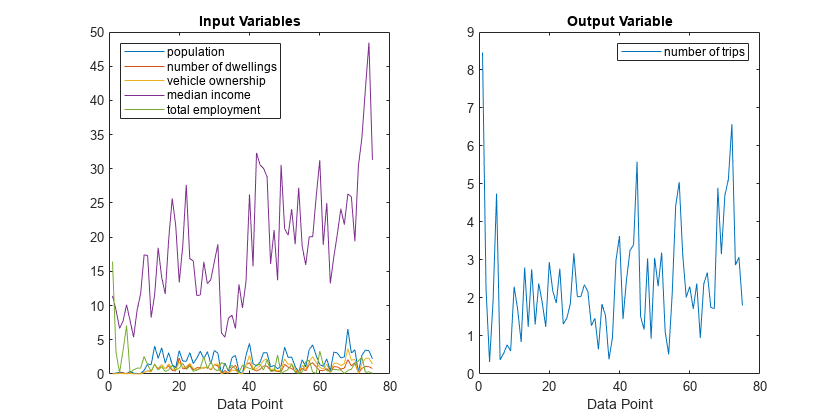
集群的数据
减法聚类算法是一种快速一次走刀估算集群和集群中心的数量在一个数据集。集群使用减法聚类训练数据,使用subclust函数。
[C, S] = subclust ([datain dataout], 0.5);
对于这个示例,使用一个集群范围的影响0.5。这个值表示的范围影响集群的当你考虑到数据空间作为一个单位超立方体。指定一个小簇半径通常产生许多小集群的数据,产生一个金融中间人与许多规则。指定一个大型集群半径通常产生一些大型集群的数据和结果更少的规则。
每一行的C包含集群中心的位置确定的聚类算法。在这种情况下,该算法发现三个集群的数据。
C
C =3×61.8770 0.7630 0.9170 18.7500 1.5650 2.1830 0.3980 0.1510 0.1320 8.1590 0.6250 0.6480 3.1160 1.1930 1.4870 19.7330 0.6030 2.3850
情节的训练数据的集群中心两个输入变量。
图绘制(datain (:, 5), dataout (: 1),“。”C (:, 5), C (:, 6),“r *”)传说(“数据”,“集群中心”,“位置”,“东南”)包含(“就业总人数”)ylabel (“旅行”)标题(“数据和集群中心”)
中的值年代显示的范围影响集群的每个数据中心维度。所有集群中心有相同的组年代值。
年代
S =1×61.1621 0.4117 0.6555 7.6139 2.8931 1.4395
使用数据生成模糊推理系统集群
使用genfis函数来生成一个模糊推理系统(FIS)利用减法聚类的数据。
使用聚类方法找到的一个重要优势是合成规则更适合输入数据比在FIS生成的聚类。这个裁剪减少规则的总数输入数据时具有很高的维度。
首先,创建一个genfisOptions选项设置减法聚类,指定相同的集群影响范围值。
fisOpt = genfisOptions (“SubtractiveClustering”,…“ClusterInfluenceRange”,0.5);
使用训练数据生成FIS模型和指定的选项。
fis = genfis (datain dataout fisOpt);
基于输入和输出训练的尺寸数据,生成的FIS有五个输入和一个输出。genfis指定默认名称输入,输出,和成员函数。
生成的FIS对象是一个一阶Sugeno系统有三个规则。
showrule (fis,“格式”,“象征”)
ans =3 x132 char数组“1。(in1 = = in1cluster1) & (in2 = = in2cluster1) & (in3 = = in3cluster1) & (in4 = = in4cluster1) &(把= = in5cluster1) = >(着干活= out1cluster1) (1)“2。(in1 = = in1cluster2) & (in2 = = in2cluster2) & (in3 = = in3cluster2) & (in4 = = in4cluster2) &(把= = in5cluster2) = >(着干活= out1cluster2) (1)“3。(in1 = = in1cluster3) & (in2 = = in2cluster3) & (in3 = = in3cluster3) & (in4 = = in4cluster3) &(把= = in5cluster3) = >(着干活= out1cluster3) (1)
你可以概念化每个规则如下:如果输入FIS(人口、居住单位,车辆的数量,收入和就业)强烈属于他们的代表集群的隶属度函数,然后输出(旅行)必须属于同一集群。也就是说,每个规则简洁集群在输入空间映射到相同的集群在输出空间。
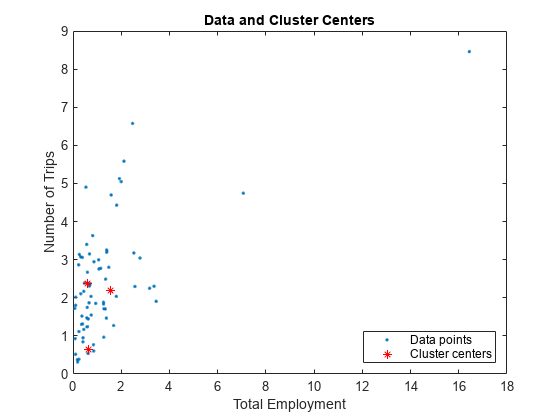
每个输入和输出变量有三个隶属度函数,它对应于确定的三个集群。输入和输出隶属度函数的参数推导基于集群中心和集群范围的影响力。作为一个例子,第一个输入变量的隶属度函数。
图plotmf (fis,“输入”,1)
评估初始FIS性能
训练输入值应用于模糊系统,找到对应的输出值。
datain fuzout = evalfis (fis);
计算均方误差(RMSE)的模糊系统的输出值与期望输出值。
trnRMSE =规范(fuzout-dataout) /√长度(fuzout))
trnRMSE = 0.5276
使用验证验证模糊系统的性能数据。
valdatain valfuzout = evalfis (fis);valRMSE =规范(valfuzout-valdataout) /√长度(valfuzout))
valRMSE = 0.6179
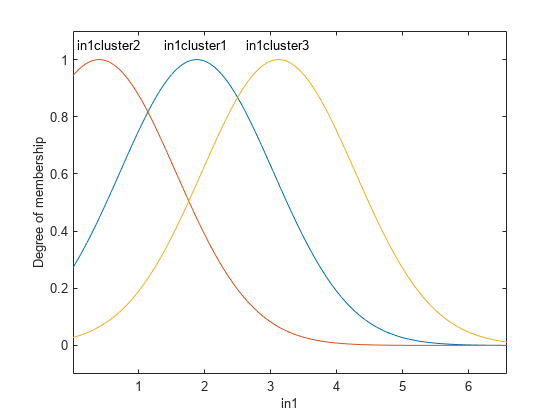
策划的输出模型对验证数据。
图绘制(valdataout)在情节(valfuzout“o”)举行从ylabel (“产值”)传说(“验证数据”,“FIS输出”,“位置”,“西北”)
情节表明,模型没有预测验证数据。
曲调FIS使用简称ANFIS
提高金融中间人的性能,您可以优化系统使用简称anfis函数。首先,试着用一个相对较短的训练时期(20世纪)没有使用验证数据,然后测试生成的FIS模型对验证数据。
选择= anfisOptions (“InitialFIS”金融中间人,…“EpochNumber”,20岁,…“InitialStepSize”,0.1);fis2 =简称anfis ([datain dataout],选择);
简称ANFIS信息的节点数量:44的线性参数:18号的非线性参数:30总数的参数:训练数据对48号:75数量的检查数据对:0模糊规则数量:3开始简称ANFIS训练……1 0.490585 0.499985 0.492996 0.513727 0.527607 - 2 3 4 5 6 0.492924步长减少到0.090000后时代7。7步长增加到0.099000 0.480813 0.48733 0.485036 8 9 10后时代。十0.451177 0.462516 0.475097 0.469759 11 12 13步长增加到0.108900后时代14。14 0.433904 0.447856 0.444356 15 16 17 18 0.433739步长增加到0.119790时代。18 0.420408 19 0.420512 20 0.420275数量达到指定的时代。简称ANFIS训练完成时代20。最小的训练RMSE = 0.420275
评估FIS的性能在训练数据和验证数据。
fuzout2 = evalfis (fis2, datain);trnRMSE2 =规范(fuzout2-dataout) /√长度(fuzout2))
trnRMSE2 = 0.4203
valfuzout2 = evalfis (fis2, valdatain);valRMSE2 =规范(valfuzout2-valdataout) /√长度(valfuzout2))
valRMSE2 = 0.5894
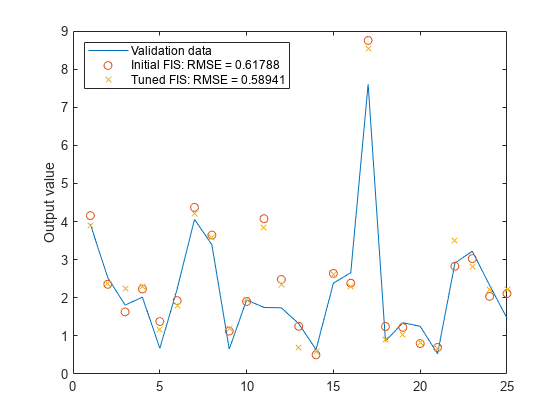
模型的性能显示实质性的改进对训练数据但仅略对验证数据。画出改进的模型对验证数据输出。
图绘制(valdataout)在情节(valfuzout“o”)情节(valfuzout2“x”)举行从ylabel (“产值”)传说(“验证数据”,…“初步FIS: RMSE = "+ num2str (valRMSE),…“调FIS: RMSE = "+ num2str (valRMSE2),…“位置”,“西北”)
检查简称ANFIS过度拟合的结果
当调优FIS,你可以检测过度拟合验证错误时开始增加在训练误差继续减少。
检查模型过度拟合,使用简称anfis验证数据训练模型200时代。首先通过修改现有的配置简称ANFIS训练选项anfisOptions选项。指定数量的时代和验证数据。由于培训时期的数量较大,抑制训练信息的显示在命令窗口。
opt.EpochNumber = 200;opt.ValidationData = [valdatain valdataout];opt.DisplayANFISInformation = 0;opt.DisplayErrorValues = 0;opt.DisplayStepSize = 0;opt.DisplayFinalResults = 0;
培养金融中间人。
[fis3, trnErr stepSize、fis4 valErr] =简称anfis ([datain dataout],选择);
在这里:
fis3是FIS对象当训练误差达到最小。fis4快照FIS对象当验证数据误差达到最小。stepSize是一个历史的训练步骤大小。trnErr是RMSE使用训练数据。valErr是RMSE使用每个训练时期的验证数据。
培训完成后,验证模型使用的培训和验证数据。
fuzout4 = evalfis (fis4 datain);trnRMSE4 =规范(fuzout4-dataout) /√长度(fuzout4))
trnRMSE4 = 0.3393
valfuzout4 = evalfis (fis4 valdatain);valRMSE4 =规范(valfuzout4-valdataout) /√长度(valfuzout4))
valRMSE4 = 0.5834
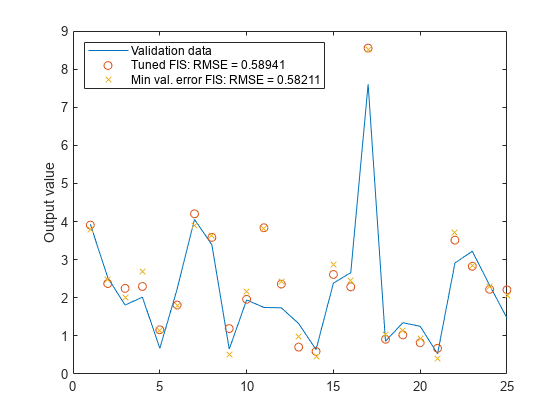
训练数据的错误是最低的迄今为止,验证数据的误差也比以前略低。这个结果表明可能的过度拟合,这发生在你训练数据的模糊系统,它不再很好地拟合验证数据。结果是一个普遍性的损失。
视图改进模型的输出。图模型对验证数据输出。
图绘制(valdataout)在情节(valfuzout2“o”)情节(valfuzout4“x”)举行从ylabel (“产值”)传说(“验证数据”,…“调FIS: RMSE = "+ num2str (valRMSE2),…“敏val.错误FIS: RMSE = "+ num2str (valRMSE4),…“位置”,“西北”)
接下来,情节训练误差trnErr。
图绘制(trnErr)标题(“训练误差”)包含(“数字时代”)ylabel (“错误”)
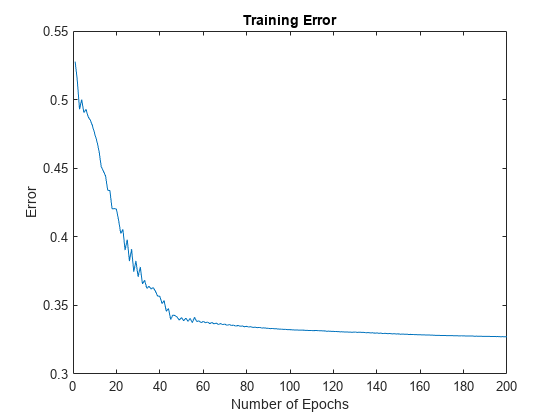
这图显示训练误差约为60时代。
画出验证错误valErr。
图绘制(valErr)标题(验证错误的)包含(“数字时代”)ylabel (“错误”)

情节表明验证数据误差的最小值出现在时代52。在这一点上,它甚至稍有增加简称anfis继续对训练数据的误差最小化。这种模式是过度拟合的标志。根据指定的错误宽容,策划验证错误还可以指示模型的泛化能力的测试数据。