准备文本数据进行分析
这个例子展示了如何创建一个函数来清理和预处理文本数据以进行分析。
文本数据可能很大,并且可能包含大量的噪声,这对统计分析有负面影响。例如,文本数据可以包含以下内容:
例外情况,例如“新”和“新”
单词形式的变化,例如“walk”和“walking”
带有噪声的词,例如“the”和“of”
标点符号和特殊字符
HTML和XML标签
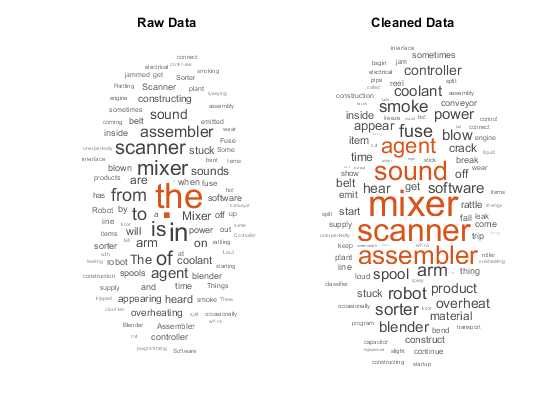
这些词云演示了应用于工厂报告的一些原始文本数据的词频分析,以及相同文本数据的预处理版本。

加载和提取文本数据
加载示例数据。该文件factoryReports.csv包含工厂报告,包括每个事件的文本描述和分类标签。
文件名=“factoryreports.csv”;data = readtable(文件名,“TextType”,'细绳');
从字段中提取文本数据描述,以及来自字段的标签数据类别.
textdata = data.description;标签= data.category;TextData(1:10)
ans =.10×1的字符串“物品偶尔会卡在扫描仪的线轴上。”“组装器的活塞发出响亮的咔嗒咔嗒和砰砰的声音。”“启动核电站时,电力会被切断。”“组装器里的电容器被炸了。”“搅拌机把保险丝弄坏了。”"爆破管道中施工剂正在喷洒冷却剂""搅拌机里的保险丝烧断了"“事情继续从腰带上滑落。”“从传送带上掉下来的东西。”扫描卷轴一旦分开,很快就会开始弯曲。
创建标记化的文档
创建一个标记化文档数组。
cleaneddocuments = tokenizeddocument(textdata);cleanedDocuments (1:10)
ans = 10×1 tokenizedDocument: 10 token:物品偶尔会卡在扫描仪卷轴中。11代币:响亮的咔嗒咔嗒声和砰砰声来自组装器的活塞。11代币:启动工厂时电源被切断。6代币:在组装器中炸电容器。5令牌:混合器触发了保险丝。10令牌:爆管中施工剂正在喷洒冷却剂。令牌:搅拌器中的保险丝熔断了。9代币:东西继续从腰带上掉下来。7代币:从传送带上掉落的物品。13令牌:扫描仪卷轴被分割,它很快就会开始弯曲。
为了改善lemmatization,将部分语音详细信息添加到文件中addPartOfSpeechDetails.使用addPartOfSpeech在删除停止单词和lemmatizing之前的功能。
cleaneddocuments = addpartofspeechdetails(cleaneddocuments);
像“a”、“and”、“to”和“the”这样的词(也就是停止词)会给数据增加干扰。删除使用的停止词列表Removestopwords.函数。使用Removestopwords.函数的normalizeWords函数。
cleanedDocuments = removeStopWords (cleanedDocuments);cleanedDocuments (1:10)
ans = 10×1令牌Document:7个令牌:偶尔抓住扫描仪线轴的物品。8个令牌:响亮的轰鸣声发出声音即将到来的装配器活塞。5令牌:削减电力起动厂。4令牌:油炸电容器汇编器。4个令牌:搅拌机绊倒的保险丝。7令牌:突发管构建试剂喷涂冷却剂。4令牌:保险丝吹搅拌机。6令牌:事情继续滚动皮带。5个令牌:落下物品输送带。8令牌:扫描仪卷轴拆分,很快开始曲线。
使用的单词释放normalizeWords.
cleaneddocuments = rangerizewords(cleaneddocuments,“风格”,“引理”);cleanedDocuments (1:10)
ans = 10×1令王形化document:7个令牌:物品偶尔会得到卡住扫描仪卷轴。8令牌:大声拨浪鼓声音来了装配器活塞。5令牌:切割电力启动厂。4个令牌:Fry电容器组件。4令牌:搅拌机跳闸保险丝。7令牌:突发管构建试剂喷雾冷却剂。4令牌:保险丝吹气器。6令牌:事情继续滚动皮带。5令牌:秋季物品输送带。8令牌:扫描仪卷轴拆分,很快开始曲线。
从文档中删除标点符号。
cleanedDocuments = erasePunctuation (cleanedDocuments);cleanedDocuments (1:10)
ans = 10×1 tokenizedDocument: 6令牌:项目偶尔卡住扫描仪线轴7令牌:大声喋喋不休的爆炸声音来汇编活塞4令牌:减少力量开始工厂3令牌:炒电容器汇编3令牌:搅拌机旅行保险丝6令牌:破裂管道建设剂喷雾冷却剂3令牌:保险丝打击搅拌机5令牌:东西继续滚落带4代代币:落下物品输送带6代代币:扫描仪卷轴分裂很快开始曲线
删除2个或更少字符的单词,以及15个或更大字符的单词。
cleanedDocuments = removeShortWords (cleanedDocuments 2);cleanedDocuments = removeLongWords (cleanedDocuments 15);cleanedDocuments (1:10)
ans = 10×1 tokenizedDocument: 6令牌:项目偶尔卡住扫描仪线轴7令牌:大声喋喋不休的爆炸声音来汇编活塞4令牌:减少力量开始工厂3令牌:炒电容器汇编3令牌:搅拌机旅行保险丝6令牌:破裂管道建设剂喷雾冷却剂3令牌:保险丝打击搅拌机5令牌:东西继续滚落带4代代币:落下物品输送带6代代币:扫描仪卷轴分裂很快开始曲线
创建袋式模型
创建一个单词袋式模型。
cleanedBag = bagOfWords (cleanedDocuments)
CleanedBag =具有属性的BagofWords:计数:[480×352双]词汇:[1×352字符串] num字:352 numfocuments:480
删除单词袋模型中不出现超过两次的单词。
cleanedBag = removeInfrequentWords (cleanedBag, 2)
CleanedBag =具有属性的Bagofwords:计数:[480×163双]词汇:[1×163字符串] num字:163 numfocuments:480
一些预处理步骤,如removeInfrequentWords在单词袋式模型中留下空的文件。在预处理后,确保在单词袋式模型中保留没有空的文档removeEmptyDocuments作为最后一步。
从单词袋式模型和相应的标签中删除空文档标签.
[CleanedBag,IDX] =删除贩子(CleanedBag);标签(IDX)= [];清洁袋
CleanedBag =具有属性的Bagofwords:计数:[480×163双]词汇:[1×163字符串] num字:163 numfocuments:480
创建预处理功能
创建一个执行预处理的函数很有用,以便以相同的方式准备不同的文本数据集合。例如,您可以使用功能,以便您可以使用与培训数据相同的步骤进行预处理新数据。
创建函数授权并预处理文本数据,以便它可以用于分析。功能PreprocessText.,执行以下步骤:
使用授权文本
tokenizedDocument.删除使用停止词的列表(如“and”,“of”和“the”)
Removestopwords..使用的单词释放
normalizeWords.使用擦除标点符号
侵蚀.删除使用2个或更少字符的单词
removeshortwords..使用15个或更多字符删除单词
removeLongWords.
使用示例预处理函数PreprocessText.准备文本数据。
newText =“分拣机发出很大的噪音。”;newdocuments = preprocesstext(newtext)
newdocuments = tokenizeddocument:6个令牌:分拣机响亮的噪音
与原始数据比较
将预处理的数据与原始数据进行比较。
rawDocuments = tokenizedDocument (textData);rawBag = bagOfWords (rawDocuments)
rawBag = bagOfWords with properties: Counts: [480×555 double] Vocabulary: [1×555 string] NumWords: 555 NumDocuments: 480
计算数据的减少量。
numwordscleaned = cleanedbag.numwords;numwordsraw = rawbag.numwords;RESEAST = 1 - numwordscleaned / numwordsraw
减少= 0.7063
使用Word云可视化两个单词的模型来比较原始数据和清除数据。
图形子图(1,2,1)WordCloud(RawBag);标题(“原始数据”次要情节(1、2、2)wordcloud (cleanedBag);标题(“清洁数据”)
预处理功能
功能PreprocessText.,按顺序执行以下步骤:
使用授权文本
tokenizedDocument.删除使用停止词的列表(如“and”,“of”和“the”)
Removestopwords..使用的单词释放
normalizeWords.使用擦除标点符号
侵蚀.删除使用2个或更少字符的单词
removeshortwords..使用15个或更多字符删除单词
removeLongWords.
功能文档= preprocessText(TextData)%标记文本。文档= tokenizeddocument(textdata);%删除停止单词列表,然后释放单词。改善%词源化,首先使用addpartfspeech details。文档= addpartofspeechdetails(文件);文档= Removestopwords(文件);文档= rangerizewords(文档,“风格”,“引理”);%擦除标点符号。文件=侵蚀(文件);%删除2个或更少字符的单词,以及15个或更多字符的单词%字符。文件= removeShortWords(文件,2);= removeLongWords文档(文档、15);结尾
另请参阅
addPartOfSpeechDetails|bagOfWords|侵蚀|normalizeWords|removeEmptyDocuments|removeInfrequentWords|removeLongWords|removeshortwords.|Removestopwords.|tokenizedDocument|wordcloud
相关的话题
您还可以从以下列表中选择一个网站:
