利用深度学习训练语音指令识别模型
这个例子展示了如何训练一个深度学习模型来检测音频中语音命令的存在。这个例子使用了语音命令数据集[1]训练卷积神经网络来识别一组命令。
若要使用预训练的语音命令识别系统,请参见基于深度学习的语音指令识别(音频工具箱).

要快速运行示例,请设置speedupExample来真正的.要运行已发布的完整示例,请设置speedupExample来假.
speedupExample = 假;
假;

为重现性设置随机种子。
rng默认的
加载数据
本示例使用谷歌语音命令数据集[1].下载并解压缩数据集。
downloadFolder = matlab.internal.examples.download万博1manbetxSupportFile(“音频”,“google_speech.zip”);dataFolder = tempdir;unzip(下载文件夹,数据文件夹)dataset = fullfile(数据文件夹,数据文件夹)“google_speech”);
增加的数据
该网络不仅应该能够识别不同的口语,还应该能够检测音频输入是静音还是背景噪音。
支撑函数万博1manbetx,augmentDataset,使用谷歌语音命令数据集后台文件夹中的长音频文件创建一秒段的背景噪声。该函数从每个背景噪声文件中创建相同数量的背景段,然后在训练文件夹和验证文件夹之间分割这些段。
augmentDataset(数据集)
Progress = 17 (%) Progress = 33 (%) Progress = 50 (%) Progress = 67 (%) Progress = 83 (%) Progress = 100 (%)
创建培训数据存储
创建一个audioDatastore(音频工具箱)它指向训练数据集。
ads = audioDatastore(fullfile(dataset,“训练”),...IncludeSubfolders = true,...FileExtensions =“wav”,...LabelSource =“foldernames”);
指定希望模型识别为命令的单词。将所有不是命令或背景噪音的文件标记为未知的.把不是命令的词标记为未知的创建一组单词,它近似于除命令之外的所有单词的分布。网络使用这个组来学习命令和所有其他单词之间的区别。
为了减少已知和未知单词之间的类不平衡,加快处理速度,在训练集中只包含一部分未知单词。
使用子集(音频工具箱)创建一个只包含命令、背景噪声和未知单词子集的数据存储。计算属于每个类别的例子的数量。
命令= category ([“是的”,“不”,《飞屋环游记》,“向下”,“左”,“正确”,“上”,“关闭”,“停止”,“走”]);背景=分类的(“背景”);isCommand = ismember(ads.Labels,commands);isBackground = ismember(ads.Labels,background);isUnknown = ~(isCommand|isBackground);includeffraction = 0.2;%要包含的未知数的百分比。idx = find(isUnknown);idx = idx(randperm(数字(idx),round((1- includeffraction)*sum(isUnknown))));isUnknown(idx) = false;ads.Labels(isUnknown) =分类的(“未知”);adsTrain =子集(ads,isCommand|isUnknown|isBackground);adsTrain。标签= remove (adsTrain.Labels);
创建验证数据存储
创建一个audioDatastore(音频工具箱)它指向验证数据集。遵循与创建训练数据存储相同的步骤。
ads = audioDatastore(fullfile(dataset,“确认”),...IncludeSubfolders = true,...FileExtensions =“wav”,...LabelSource =“foldernames”);isCommand = ismember(ads.Labels,commands);isBackground = ismember(ads.Labels,background);isUnknown = ~(isCommand|isBackground);includeffraction = 0.2;%要包含的未知数的百分比。idx = find(isUnknown);idx = idx(randperm(数字(idx),round((1- includeffraction)*sum(isUnknown))));isUnknown(idx) = false;ads.Labels(isUnknown) =分类的(“未知”);adsValidation =子集(ads,isCommand|isUnknown|isBackground);adsValidation。标签= removecats(adsValidation.Labels);
可视化训练和验证标签分布。
图(单位=“归一化”,Position=[0.2,0.2,0.5,0.5]) tiledlayout(2,1) nexttile直方图(adsTrain.Labels) title(“培训标签发放”) ylabel (“观察次数”网格)在nexttile直方图(adsValidation.Labels)“验证标签分发”) ylabel (“观察次数”网格)在

如果需要,可以通过减少数据集来加快示例的速度。
如果speedupExample numUniqueLabels = numel(unique(adsTrain.Labels));% #好< UNRCH >将数据集减少20倍adsTrain = splitEachLabel(adsTrain,round(numel(adsTrain. files) / numUniqueLabels / 20));adsValidation = splitEachLabel(adsValidation,round(numel(adsValidation. files) / numUniqueLabels / 20));结束
为培训准备数据
为了为卷积神经网络的有效训练准备数据,将语音波形转换为基于听觉的频谱图。
为了加快处理速度,您可以将特征提取分布到多个worker上。如果可以访问并行计算工具箱™,则启动并行池。
如果useparallelpool && ~speedupExample useParallel = true;gcp;其他的useParallel = false;结束
使用“本地”配置文件启动并行池(parpool)…连接到并行池(工人数:6)。
提取的特征
定义从音频输入中提取听觉谱图的参数。segmentDuration是每个演讲剪辑的持续时间,以秒为单位。frameDuration是用于频谱计算的每帧的持续时间。hopDuration是每个频谱之间的时间步长。numBands是听觉谱图中滤波器的数量。
Fs = 16e3;%数据集的已知抽样率。segmentDuration = 1;frameDuration = 0.025;hopDuration = 0.010;FFTLength = 512;numBands = 50;segmentSamples = round(segmentDuration*fs);frameSamples = round(frameDuration*fs);hopSamples = round(hopDuration*fs);overlapSamples = framessamples - hopSamples;
创建一个audioFeatureExtractor(音频工具箱)对象执行特征提取。
afe = audioFeatureExtractor(...SampleRate = fs,...FFTLength = FFTLength,...窗口=损害(frameSamples,“周期”),...OverlapLength = overlapSamples,...barkSpectrum = true);setExtractorParameters (afe“barkSpectrum”NumBands = NumBands WindowNormalization = false);
定义一系列变换(音频工具箱)在audioDatastore(音频工具箱)要将音频填充到一致的长度,请提取特征,然后应用对数。

transform1 = transform(adsTrain,@(x)[零(地板((segmentSamples-size(x,1))/2),1);x;零(ceil((segmentSamples-size(x,1))/2),1)]);Transform2 = transform(transform1,@(x)extract(afe,x));Transform3 = transform(transform2,@(x){log10(x+1e-6)});
使用readall(音频工具箱)函数从数据存储中读取所有数据。在读取每个文件时,将在返回数据之前通过转换传递该文件。
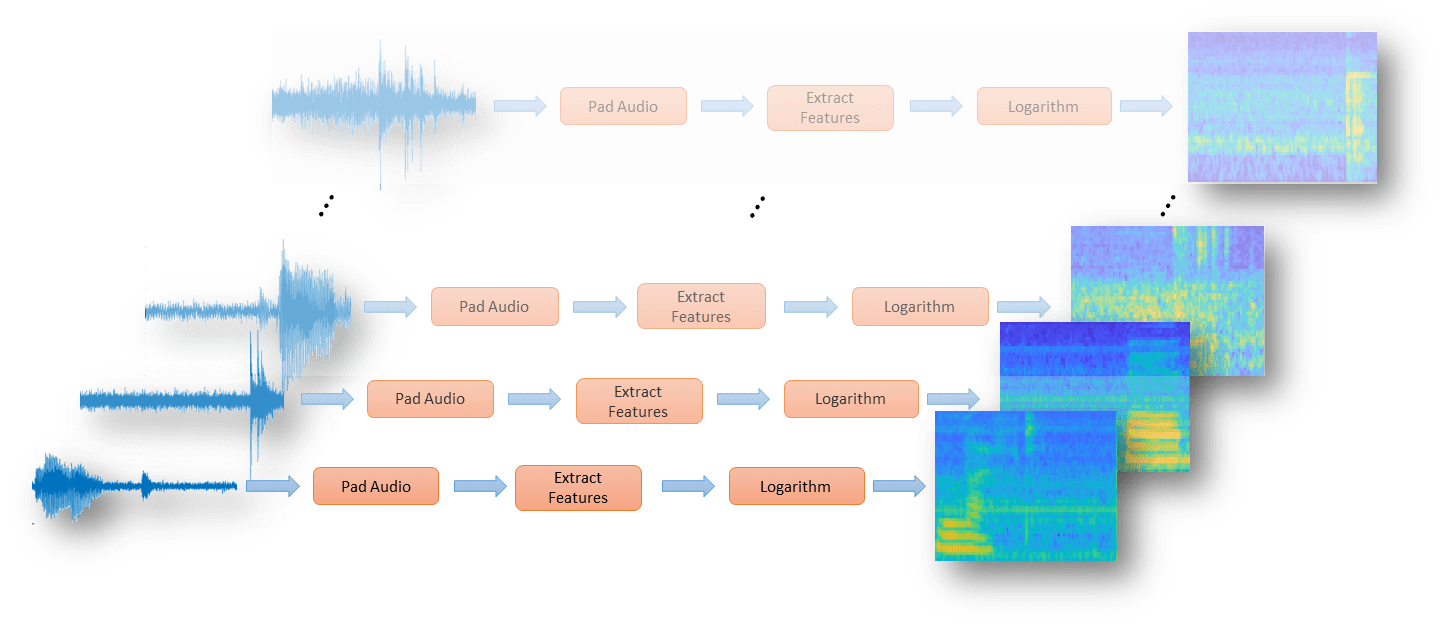
XTrain = readall(transform3,UseParallel= UseParallel);
输出为numFiles-by-1单元格数组。细胞阵列的每个元素都对应于从文件中提取的听觉频谱图。
numFiles = nummel (XTrain)
numFiles = 28463
[numHops,numBands,numChannels] = size(XTrain{1})
numHops = 98
numBands = 50
numChannels = 1
将细胞阵列转换为带有沿第四维听觉频谱图的四维阵列。
XTrain = cat(4,XTrain{:});[numHops,numBands,numChannels,numFiles] = size(XTrain)
numHops = 98
numBands = 50
numChannels = 1
numFiles = 28463
在验证集上执行上述特征提取步骤。
transform1 = transform(adsValidation,@(x)[零(地板((segmentSamples-size(x,1))/2),1);x;零(ceil((segmentSamples-size(x,1))/2),1)]);Transform2 = transform(transform1,@(x)extract(afe,x));Transform3 = transform(transform2,@(x){log10(x+1e-6)});XValidation = readall(transform3,UseParallel= UseParallel);XValidation = cat(4,XValidation{:});
为了方便起见,请隔离训练和验证目标标签。
TTrain = adsTrain.Labels;TValidation = adsValidation.Labels;
可视化数据
绘制一些训练样本的波形和听觉谱图。播放相应的音频片段。
specMin = min(XTrain,[],“所有”);specMax = max(XTrain,[],“所有”);idx = randperm(numel(adsTrain.Files),3);图(单位=“归一化”位置= (0.2,0.2,0.6,0.6));tiledlayout(2、3)为ii = 1:3 [x,fs] = audioread(adsTrain.Files{idx(ii)});Nexttile (ii) plot(x)轴紧title(string(adsTrain.Labels(idx(ii)))) nexttile(ii+3) spect = XTrain(:,:,1,idx(ii)))';pcolor(spect) clim([specMin specMax])着色平声音(x, fs)暂停(2)结束

定义网络架构
创建一个简单的网络体系结构作为层的数组。使用卷积和批处理归一化层,并使用最大池化层在“空间上”(即在时间和频率上)对特征映射进行下采样。添加最后的最大池化层,随着时间的推移将输入特征映射全局池化。这加强了输入频谱图中的(近似)时间平移不变性,允许网络执行相同的分类,而不依赖于语音在时间上的确切位置。全局池化还显著减少了最终全连接层中的参数数量。为了降低网络记忆训练数据特定特征的可能性,在最后一个全连接层的输入中加入少量的dropout。
该网络很小,因为它只有5个卷积层和很少的滤波器。numF控制卷积层中的过滤器数量。为了提高网络的准确性,可以尝试通过添加卷积、批处理归一化和ReLU层的相同块来增加网络深度。你也可以尝试增加卷积滤波器的数量numF.
为了让每个类在损失中拥有相同的总权重,使用与每个类中的训练示例数量成反比的类权重。当使用Adam优化器训练网络时,训练算法独立于类权值的整体归一化。
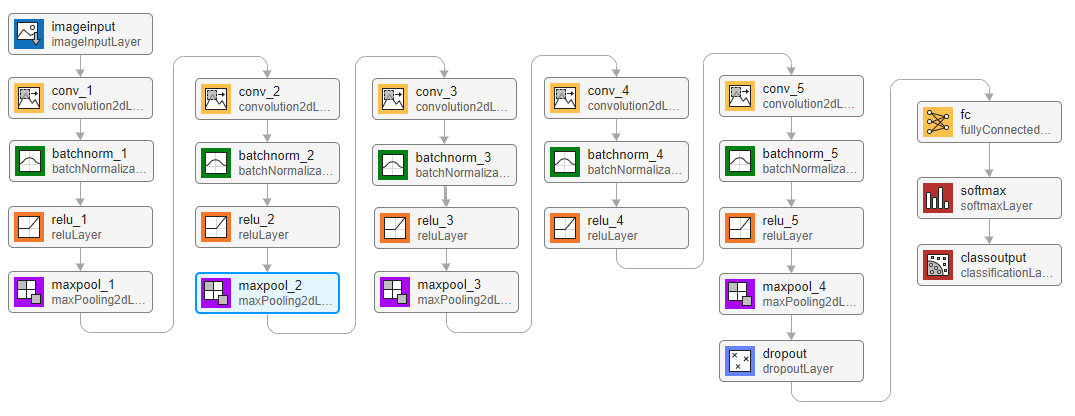
类=类别(TTrain);classWeights = 1./countcats(TTrain);classWeights = classWeights'/mean(classWeights);numClasses = nummel(类);timePoolSize = ceil(numHops/8);dropoutProb = 0.2;numF = 12;layers = [imageInputLayer([numHops,afe.FeatureVectorLength]) convolution2dLayer(3,numF,Padding=“相同”) batchNormalizationLayer reluLayer maxPooling2dLayer(3,Stride=2,Padding=“相同”) convolution2dLayer (3 2 * numF填充=“相同”) batchNormalizationLayer reluLayer maxPooling2dLayer(3,Stride=2,Padding=“相同”) convolution2dLayer(3、4 * numF填充=“相同”) batchNormalizationLayer reluLayer maxPooling2dLayer(3,Stride=2,Padding=“相同”) convolution2dLayer(3、4 * numF填充=“相同”) batchNormalizationLayer reluLayer convolution2dLayer(3,4*numF,Padding=“相同”) batchNormalizationLayer reluLayer maxPooling2dLayer([timePoolSize,1]) dropoutLayer(dropoutProb) fullyConnectedLayer(numClasses) softmaxLayer classificationLayer(Classes= Classes,ClassWeights= ClassWeights)];
指定培训项目
要为训练定义参数,请使用trainingOptions.使用Adam优化器,迷你批量大小为128。
miniBatchSize = 128;validationFrequency = floor(数字(TTrain)/miniBatchSize);选项= trainingOptions(“亚当”,...InitialLearnRate = 3的军医,...MaxEpochs = 15,...MiniBatchSize = MiniBatchSize,...洗牌=“every-epoch”,...情节=“训练进步”,...Verbose = false,...ValidationData = {XValidation, TValidation},...ValidationFrequency = ValidationFrequency);
列车网络的
为了训练网络,使用trainNetwork.如果你没有GPU,那么训练网络可能需要时间。
trainedNet = trainNetwork(XTrain,TTrain,图层,选项);

评估训练网络
要计算网络在训练集和验证集上的最终精度,请使用分类.网络在这个数据集上非常准确。然而,训练、验证和测试数据都有类似的分布,不一定反映现实环境。这一限制尤其适用于未知的类别,它只包含少量单词的发音。
YValidation = classification (trainedNet,XValidation);validationError = mean(YValidation ~= TValidation);YTrain =分类(trainedNet,XTrain);trainError = mean(YTrain ~= TTrain);disp ([“训练错误:”+ trainError*100 +“%”;"验证错误:"+ validationError*100 +“%”])
“训练误差:2.7263%”“验证误差:6.3968%”
若要绘制验证集的混淆矩阵,请使用confusionchart.通过使用列和行摘要显示每个类的精度和召回率。
图(单位=“归一化”位置= (0.2,0.2,0.5,0.5));cm = confusichart (TValidation,YValidation,...Title =验证数据混淆矩阵,...ColumnSummary =“column-normalized”RowSummary =“row-normalized”);sortClasses(厘米,[命令,“未知”,“背景”])

当处理硬件资源受限的应用程序时,例如移动应用程序,考虑可用内存和计算资源的限制是很重要的。以千字节为单位计算网络的总大小,并在使用CPU时测试其预测速度。预测时间是对单个输入图像进行分类的时间。如果向网络输入多个图像,则可以同时对这些图像进行分类,从而缩短每张图像的预测时间。然而,在对流媒体音频进行分类时,单幅图像预测时间是最相关的。
为ii = 1:100 x = randn([numHops,numBands]);predictionTimer = tic;[y,probs] = category (trainedNet,x,ExecutionEnvironment=“cpu”);time(ii) = toc(predictionTimer);结束disp ([“网络规模:”+谁(“trainedNet”).字节/ 1024 +“知识库”;...CPU单图像预测时间:+ mean(time(11:end))*1000 +“女士”])
“网络大小:292.2842 kB”“CPU上的单幅图像预测时间:3.7237 ms”
万博1manbetx支持功能
用背景噪声增强数据集
函数augmentDataset(datasetloc) adsBkg = audioDatastore(fullfile(datasetloc,“背景”));Fs = 16e3;%数据集的已知抽样率segmentDuration = 1;segmentSamples = round(segmentDuration*fs);volumeRange = log10([1e-4,1]);numkgsegments = 4000;numkgfiles = nummel (adsBkg.Files);numSegmentsPerFile = floor(numkgsegments / numkgfiles);fpTrain = fullfile(datasetloc,“训练”,“背景”);fpValidation = fullfile(datasetloc,“确认”,“背景”);如果~ datasetExists (fpTrain)%创建目录mkdir (fpTrain) mkdir (fpValidation)为backgroundFileIndex = 1: nummel (adsBkg. files) [bkgFile,fileInfo] = read(adsBkg);[~,fn] = fileparts(fileInfo.FileName);确定每个分段的起始指数segmentStart = randi(size(bkgFile,1)-segmentSamples,numSegmentsPerFile,1);%确定每个剪辑的增益增益= 10.^((volumeRange(2)-volumeRange(1))*rand(numSegmentsPerFile,1) + volumeRange(1));为segmentdx = 1:numSegmentsPerFile隔离随机选择的数据段。bkgSegment = bkgFile(segmentStart(segmentdx):segmentStart(segmentdx)+segmentSamples-1);按指定增益缩放段。bkgSegment = bkgSegment*gain(segmentdx);剪辑介于-1和1之间的音频。bkgSegment = max(min(bkgSegment,1),-1);创建文件名。Afn = fn +“_segment”+ segmentdx +“wav”;%随机分配背景段给火车或%验证集。如果兰特> 0.85将15%分配给验证dirToWriteTo = fpValidation;其他的将85%分配给训练集。dirToWriteTo = fpTrain;结束将音频写入文件位置。ffn = fullfile(dirToWriteTo,afn);audiowrite (ffn bkgSegment fs)结束打印进度%流('进度= %d (%%)\n'而圆(100 *进展(adsBkg)))结束结束结束
参考文献
狱长P。“语音命令:用于单词语音识别的公共数据集”,2017年。可以从https://storage.googleapis.com/download.tensorflow.org/data/speech_commands_v0.01.tar.gz.版权所有谷歌2017。语音命令数据集是在创作共用属性4.0许可下授权的,可在这里获得:https://creativecommons.org/licenses/by/4.0/legalcode.
参考文献
狱长P。“语音命令:用于单词语音识别的公共数据集”,2017年。可以从http://download.tensorflow.org/data/speech_commands_v0.01.tar.gz.版权所有谷歌2017。语音命令数据集是在创作共用属性4.0许可下授权的,可在这里获得:https://creativecommons.org/licenses/by/4.0/legalcode.
另请参阅
trainNetwork|分类|analyzeNetwork
相关的话题
您也可以从以下列表中选择一个网站: