GPU编程范式
gpu加速计算遵循异构编程模型。软件应用程序的高度并行化部分被映射到在物理上独立的GPU设备上执行的内核中,而其余的顺序代码仍然在CPU上运行。每个内核都被分配了几个工作者或线程,这些工作者或线程以块和网格的形式组织。内核中的每个线程相对于其他线程并发执行。
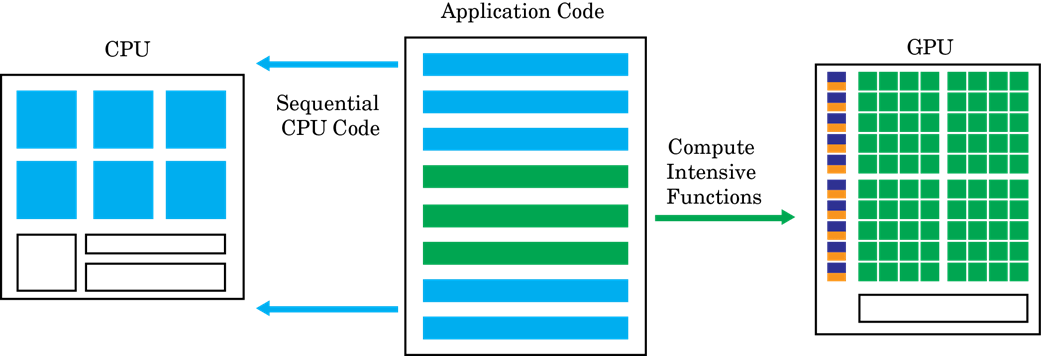
GPU编码器™的目标是采取一个序列的MATLAB®程序生成分区的,优化的CUDA®代码。这个过程包括:
CPU / GPU分区 - 识别在GPU上运行的CPU和段运行的代码段。对于不同的方式GPU编码器识别CUDA内核,请参阅内核创建.在内核创建算法中,CPU和GPU之间的内存传输成本是一个重要的考虑因素。
内核分区完成后,GPU Coder会分析CPU分区和GPU分区之间的数据依赖关系。CPU和GPU之间共享的数据在GPU内存中分配(通过使用
Cudamalloc.或cudaMallocManagedapi)。该分析还确定了数据必须通过使用在CPU和GPU之间复制的最小位置集cudaMemcpy.如果在CUDA中使用统一内存,那么同样的分析也确定了最小位置在代码中的位置cudaDeviceSync必须插入调用以获得正确的函数行为。接下来,在每个内核中,GPU编码器可以选择将数据映射到共享内存或固定内存。如果使用得当,这些内存是GPU内存层次结构的一部分,可能会带来更大的内存带宽。有关GPU编码器如何选择映射到共享内存的信息,请参见模板处理.有关GPU编码器如何选择映射到常量内存的信息,请参阅
coder.gpu.constantMemory.一旦分区和内存分配和传输语句到位,GPU编码器生成CUDA代码,遵循分区和内存分配决策。生成的源代码可以编译为一个MEX目标,以便从MATLAB内部调用,或者编译为一个共享库,以便与外部项目集成。信息,请参阅使用命令行界面生成代码.
相关话题
你也可以从以下列表中选择一个网站:
