集群中使用高斯混合模型
本主题将介绍群集使用统计和机器学习工具箱™功能的高斯混合模型(GMM)簇和示例性示出使用拟合GMM模型时指定可选参数的影响fitgmdist。
如何高斯混合模型Cluster数据
高斯混合模型(的GMM)通常用于数据聚类。您可以使用转基因微生物要么执行硬群集或柔软的聚类的查询数据。
去表演硬聚类,所述GMM受让人查询数据点,以最大化该组件后验概率多元正常组分,给出的数据。也就是说,给定一个装有GMM,簇受让人查询数据到组件产生最高的后验概率。硬聚集分配数据点只有一个集群。为示出了如何使用拟合模型来拟合GMM到数据,群集和估算部件的后验概率的例子,请参见集群混合高斯数据使用硬聚类。
此外,还可以使用GMM来对数据进行更灵活的集群,被称为柔软的(要么模糊)集群。软聚类方法分配分数为每个簇的数据点。的分数的值指示数据点到集群的关联强度。相对于硬聚类方法,软聚类方法是灵活的,因为他们可以将数据点分配到多个集群。当您执行GMM集群,得分的后验概率。对于具有GMM软聚类的一个例子,请参见集群混合高斯数据使用软聚类。
GMM聚类可以容纳具有在其中不同的尺寸和相关结构的簇。因此,在某些应用中,, GMM聚类可以比的方法,如更合适ķ-means集群。像许多聚类方法,GMM集群需要你拟合模型之前指定集群的数目。簇指定数目在GMM部件的数量。
对于转基因微生物,请遵循以下最佳做法:
考虑部件的协方差结构。您可以指定对角或全协方差矩阵,以及所有部件是否有相同的协方差矩阵。
指定的初始条件。该期望最大化(EM)算法适合GMM。如ķ-means聚类算法,EM是对初始条件的敏感,可能会收敛到局部最优。您可以为参数指定自己的初始值,数据点指定初始聚类分配或让他们随机选择,或指定使用的ķ-means ++算法。
实现正规化。举例来说,如果你有超过个数据点的预测,那么你可以为正规化估计稳定性。
GMM适合不同协方差选项和初始条件
本实施例中探讨指定为协方差结构和初始条件不同的选项时执行GMM聚类的影响。
加载费舍尔的虹膜数据集。考虑聚类萼片测量,并使用测量萼片在2- d可视化的数据。
加载fisheriris;X = MEAS(:,1:2);[N,P] =尺寸(X);积(X(:,1),X(:,2),'','MarkerSize',15);标题(“费舍尔”的虹膜数据集”);xlabel('萼片长度(cm)');ylabel(“萼片宽度(厘米)”);
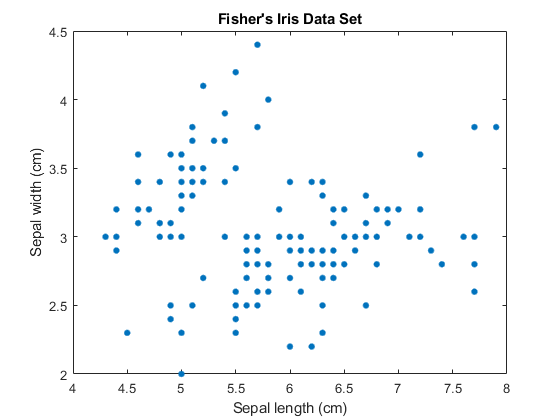
组件的数量ķ在GMM确定亚群体,或簇的数目。在此图中,很难确定是否两个,三个,或者更高斯要素是适当的。一个GMM的复杂性随着ķ增大。
指定不同的协方差结构选项
每个高斯分量具有协方差矩阵。几何上,协方差结构决定的置信度的椭球形状绘制在一个集群。您可以指定所有组件的协方差矩阵是否对角线或完整,以及所有部件是否有相同的协方差矩阵。规格每个组合确定椭圆体的形状和取向。
指定三个GMM组件和EM算法1000次最大迭代。对于重复性,设置随机种子。
RNG(3);K = 3;GMM部件的数量%选项= statset('MAXITER',1000);
指定协方差结构的选择。
西格玛= {'对角线','充分'};为协方差矩阵型%期权nSigma = numel(Sigma公司);SharedCovariance = {TRUE,FALSE};%指标为相同或不相同的协方差矩阵SCtext = {'真正','假'};NSC = numel(SharedCovariance);
创建覆盖所述测量的极端所组成的平面上的2-d的网格。稍后您将使用此格在集群绘制信心椭球。
d = 500;%网格长度X1 = linspace(分钟(X(:,1)) - 2,MAX(X(:,1))+ 2,d);X2 = linspace(分钟(X(:,2)) - 2,MAX(X(:,2))+ 2,d);[x1grid,x2grid] = meshgrid(X1,X2);X0 = [x1grid(:) x2grid(:)];
指定以下内容:
对于协方差结构选项的组合,适合GMM由三个部分组成。
使用拟合GMM集群的2-d格。
获取用于指定每个区域的信心有99%的概率阈值的分数。本说明书中确定了椭圆体的长轴和短轴的长度。
颜色的每个椭圆形使用类似的颜色作为其集群。
阈值= SQRT(chi2inv(0.99,2));计数= 1;对于I = 1:nSigma对于J = 1:NSC gmfit = fitgmdist(X,K,'CovarianceType',西格玛{I},...'SharedCovariance',SharedCovariance {Ĵ}“选项”,选项);%合身GMMclusterX =簇(gmfit,X);%簇索引mahalDist =陵(gmfit,X0);从每个网格点的每个GMM部件%距离%绘制椭圆体在每个GMM组分和显示聚类结果。副区(2,2,计数);H1 = gscatter(X(:,1),X(:,2),clusterX);保持上对于M = 1:K = IDX mahalDist(:,米)<=阈值;颜色= H1(米)。颜色* 0.75 - 0.5 *(H1(米)。颜色 - 1);H2 =情节(X0(IDX,1),X0(IDX,2),'','颜色',颜色,'MarkerSize',1);uistack(H2,'底部');结束情节(gmfit.mu(:,1),gmfit.mu(:,2),'KX','行宽',2,'MarkerSize',10)的标题(的sprintf('西格玛为%s \ nSharedCovariance =%s' 的,西格玛{I},{SCtext}Ĵ),'字体大小',8)图例(H1,{'1','2','3'})保持离计数=计数+ 1;结束结束
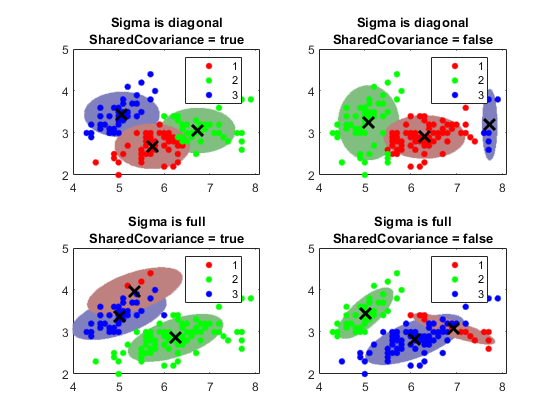
的信任区中的概率阈值确定长轴和短轴的长度,和协方差类型决定的轴线的方向。注意有关的协方差矩阵选项如下:
对角线协方差矩阵表明该预测是不相关的。椭圆的长轴和短轴平行或垂直于X和ÿ轴。本说明书中通过增加的参数的总数 ,预测器的数目,对于每个部件,但是比全协方差说明书更简洁。
全协方差矩阵允许相关预测,没有限制到椭圆的相对方位X和ÿ轴。每个组件通过增加的参数的总数 ,但捕获的预测之间的相关性的结构。这个规范会导致过度拟合。
共享协方差矩阵表明,所有组件都具有相同的协方差矩阵。所有椭圆的大小相同,并具有相同的方向。本说明书中比非共享说明书更简洁,因为通过用于仅一个分量的协方差的参数的数量总数的参数增加而增加。
非共享的协方差矩阵表明每个组件都有自己的协方差矩阵。所有椭圆的大小和方向可能会有所不同。本说明书中通过增加参数的数量ķ的一个组件协方差参数的次数,但是可以捕获组件之间的协方差差异。
该图还显示,簇并不总是保持集群顺序。如果您群集几个装gmdistribution楷模,簇可以用于类似的部件分配不同的簇标签。
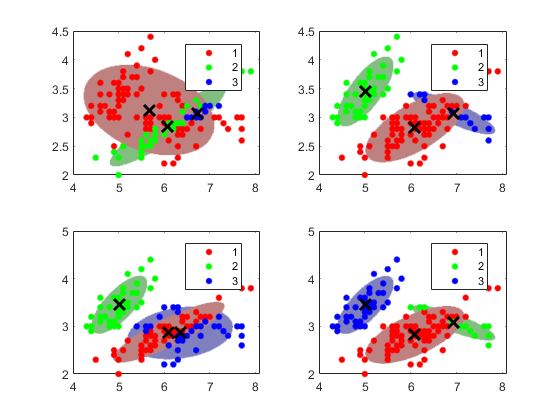
指定不同的初始条件
该算法适合一个GMM的数据可以是对初始条件敏感。为了说明这一点的灵敏度,适合四种不同的GMM如下:
对于第一个GMM,分配大多数数据指向第一个集群。
对于第二GMM,随机指定的数据点簇。
对于第三GMM,使数据点到另一个集群随机分配。
对于第四GMM,使用ķ-means ++以获得初始聚类中心。
initialCond1 = [一(正8,1);[2;2;2;2];[3;3;3;3]];%对于第一GMMinitialCond2 = randsample(1:K,N,TRUE);%对于第二GMMinitialCond3 = randsample(1:K,N,TRUE);%对于第三GMMinitialCond4 ='加';%对于第四GMMcluster0 = {initialCond1;initialCond2;initialCond3;initialCond4};
对于所有的情况下,使用ķ= 3层的组件,非共享和完全协方差矩阵,相同的初始混合物的比例,和相同的初始协方差矩阵。对于稳定性,当你尝试不同的设置初始值,增加EM算法迭代次数。此外,笼络集群信心椭球。
融合=南(4,1);对于J = 1:4 gmfit = fitgmdist(X,K,'CovarianceType','充分',...'SharedCovariance',假,'开始',cluster0 {Ĵ}...“选项”,选项);clusterX =簇(gmfit,X);%簇索引mahalDist =陵(gmfit,X0);从每个网格点的每个GMM部件%距离%绘制椭圆体在每个GMM组分和显示聚类结果。副区(2,2,j)的;H1 = gscatter(X(:,1),X(:,2),clusterX);从每个网格点的每个GMM部件%距离保持上;为nK = numel(唯一的(clusterX));对于m = 1时:为nK IDX = mahalDist(:,米)<=阈值;颜色= H1(米)。颜色* 0.75 + -0.5 *(H1(米)。颜色 - 1);H2 =情节(X0(IDX,1),X0(IDX,2),'','颜色',颜色,'MarkerSize',1);uistack(H2,'底部');结束情节(gmfit.mu(:,1),gmfit.mu(:,2),'KX','行宽',2,'MarkerSize',10)图例(H1,{'1','2','3'});保持离收敛(j)的= gmfit.Converged;%指标收敛结束
总和(融合)
ANS = 4
所有算法收敛。每个起始簇分配的数据点都通向不同的,装簇分配。您可以指定名字 - 值对参数的正整数“重复测试”,它运行的算法的指定次数。后来,fitgmdist选择能产生最大可能性的契合。
当以规范
有时,EM算法的迭代期间,拟合协方差矩阵可以成为病态的,这意味着可能性逃逸到无穷大。如果一个或多个下列条件存在可能发生此问题:
你比个数据点的预测。
您指定了太多的部件装配。
变量是高度相关的。
为了克服这个问题,你可以使用指定一个小的正数'RegularizationValue'名称 - 值对的参数。fitgmdist增加了该号码的所有协方差矩阵的对角元素,这确保了所有矩阵是正定的。规制可以降低最大似然值。
模型拟合统计
在大多数应用中,组件的数量ķ和适当的协方差结构Σ是未知的。你可以调整的一种方法一GMM是通过比较信息的标准。两个流行信息的标准是赤池信息准则(AIC)和贝叶斯信息准则(BIC)。
两者AIC和BIC采取优化,负对数似然,然后用参数模型的数目(该模型复杂性)惩罚它。然而,BIC的复杂性惩罚比AIC更严重。因此,AIC往往会选择更复杂的模型可能过度拟合,而BIC倾向于选择简单的模型可能underfit。一个好的做法是评估模型时看两个标准。较低的AIC或BIC值表明更好的拟合模型。另外,确保你的选择ķ和协方差矩阵结构适合您的应用程序。fitgmdist存储AIC和BIC装gmdistribution在属性的模型对象AIC和BIC。您可以通过使用点表示法访问这些属性。有关说明如何选择适当的参数的例子,见调高斯混合模型。
也可以看看
相关话题
您还可以选择从下面的列表中的网站:
