在这个视频中,我们展示了泰卢加固学习如何对帕曼森特磁铁同步电动机的田间控制。
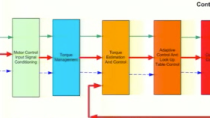
To showcase this, we start with an example that uses the typical field oriented control architecture, where the outer loop controller is responsible for speed control; whereas the inner loop PI controllers are responsible for controlling the d-axis and q-axis currents.
然后我们创建并验证一个 强化学习代理 ,它取代了这个体系结构的内环控制器。
当系统是非线性的时候,RL代理的使用是特别有益的,在这种情况下,我们可以训练一个单一的RL代理,而不是在多个操作条件下整定PI控制器。
在这个例子中,我们使用一个线性电机模型来展示使用强化学习的面向领域控制的工作流,这个工作流对于复杂的非线性电机也是一样的。
让我们看看实现面向字段的控制体系结构万博1manbetx的Simulink模型。
该模型包含两个控制回路:外速度回路和内电流回路。
外环在“速度控制”子系统中实现,并且它包含PI控制器,该PI控制器负责为内循环产生参考电流。
内环是在“电流控制”子系统中实现的,包含两个PI控制器来确定dq帧中的参考电压。
然后使用参考电压产生适当的PWM信号,控制逆变器的半导体开关,然后驱动永磁同步电机实现所需的转矩和磁通。
让我们继续运行Simulink模型。 万博1manbetx
我们可以看到,控制器的跟踪性能很好,能够跟踪期望的速度。
让我们将这个结果保存起来,以便稍后与强化学习控制器进行比较。
现在我们更新现有的模型,将电流环中的两个PI控制器替换为一个Reinforcement Learning Agent block.
在此示例中,我们使用DDPG作为加强学习算法,它培训了演员和评论家同时学习最佳政策,以最大化长期奖励。
一旦使用钢筋学习块万博1manbetx验证了Simulink模型,我们将遵循加强学习工作流程来设置,列车和模拟控制器。
加强学习工作流程如下:
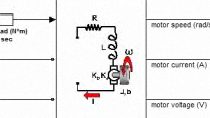
第一步是创造一个环境。在这个例子中,我们已经有了一个Simulink模型,其中包含了在“工厂万博1manbetx和逆变器”子系统中使用电机控制模块和Simscape电气建模的永磁同步电机。
然后,我们使用这个Simulink万博1manbetx模型创建一个具有适当观察和行动的强化学习环境界面。
这里观察到的强化学习块是错误的定子电流' id错误'和' iq错误'和定子电流' id '和' iq '。
动作是定子电压' vd '和' vq '。
接下来,我们创建奖励信号,让强化学习代理知道它在训练中选择的动作是好是坏,这是基于它与环境的交互作用。
在这里,我们根据二次奖励惩罚来塑造奖励,从目标和控制努力中惩罚距离。
然后我们继续创建网络架构。
在这里,我们根据DDPG算法以编程方式使用MATLAB函数来构建演员和批评网络,以用于层和表示。
无网络网络也可以使用深网络设计器应用程序构建,然后导入MATLAB。
本例中的批评网络以观察和动作作为输入,给出估计的Q值作为输出。
另一方面,演员网络将观察视为输入,并将动作作为输出提供。
使用演员和批评者表示创建,我们可以创建一个DDPG代理。
DDPG代理的采样时间根据控制环路的执行要求进行配置。
一般情况下,样本时间越短的agent训练时间越长,因为每一集的模拟步骤越多。
我们现在可以培训代理人了。
首先,我们指定培训选项。
在这里,我们指定了我们希望在大多数2000次剧集中运行培训并停止培训,如果平均奖励超过提供的价值。
然后我们使用“火车”命令开始培训过程。
一般来说,最好的做法是在训练过程中随机参考信号给控制器,以获得更鲁棒的策略。这可以通过为环境编写一个本地重置函数来实现。
在培训过程中,可以在插曲管理器中监控培训进度。
一旦培训完成,我们就可以模拟并验证培训的代理的控制策略。
通过使用培训的代理模拟模型,我们看到场导向控制的速度跟踪性能具有控制定子电流的钢筋学习剂。
通过先前保存的输出查看此性能,我们看到使用强化学习代理的现场导向控制的性能与其PI控制器对应物相当。
这是视频的结论。