文本分析工具箱提供了工具,用于从文件中提取文本,预处理的原始文本,可视化文本,对文本进行机器学习数据。
您可以使用文本分析工具箱分析数据来源如维护报告,操作日志、财务文件,网络和社会化媒体资源。
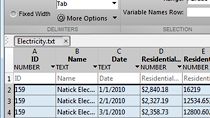
你可以从各种来源中提取原始文本包括Microsoft Word、Microsoft Excel, PDF和使用词云视图的相对频率单词和互动的散点图来理解单词之间的数值关系。
文本分析工具箱提供了功能等预处理原始文本删除常用单词和标点符号和文档为单独的词或分词短语。
一旦文本预处理,将文本转换为数字表示让你做更多的分析和可视化理解词的频率,包括:
- 直方图比较单词统计
- 袋子里的单词和Ngrams启用有效的可视化和计算
- 和TF-IDF模型对文本挖掘和机器学习
统计和机器学习算法可以用于文本分析执行主题建模识别主题文件,分类文件和作出预测。
你可以训练机器学习模型或者使用pre-trained字嵌入模型如word2vec FastText和手套。
在这个例子中,潜在狄利克雷分配算法是用于构建一个主题模型与60话题风暴报告来识别损伤和天气模式。
您还可以使用深学习算法建立准确的分类器,当你有大量的文档和使用并行计算加速文本处理和培训。
关于文本分析工具箱的更多信息,请参见产品页面,或者选择下面的一个链接。