在实时推理的边缘上的深度学习部署是许多应用领域的关键。在网络带宽,网络延迟和功耗方面,它显着降低了与云通信的成本。
然而,边缘设备的内存、计算资源和功率都是有限的。这意味着,深度学习网络必须针对嵌入式部署进行优化。
INT8量化已成为一种流行的方法,不仅用于机器学习框架,如Tensorflow和Pytorch,而且还用于像NVIDIA这样的硬件工具链®统治和Xilinx.®DNNDK - 主要是因为INT8使用8位整数而不是浮点数和整数数学而不是浮点数学,从而减少内存和计算要求。
这些需求可能相当大。例如,相对简单的AlexNet网络超过200mb,而像VGG-16这样的大型网络超过500mb[1]。这种规模的网络不适合低功耗的微控制器和更小的fpga。
在本文中,我们将详细了解使用8位表示数字意味着什么,并了解int8量化(用整数表示数字)如何将内存和带宽使用减少75%。
int8表示
我们从一个简单的例子开始,使用VGG16网络,由几个卷积和ReLU层和几个完全连接和最大池层组成。首先,让我们看看现实世界中的数字(在本例中是一个卷积层中的权重)如何用整数表示。这个函数FI.在matlab.®使用8位字长度为我们提供最佳精度缩放。这意味着我们获得了具有2 ^ -12的缩放因子的最佳精度,并将其存储为位模式,01101110表示整数110。
\ [real \ _number =存储\ _integer * scaling \ _factor \]
\ [0.0269 = 110 * 2 ^ { - 12} \]
脚本如下:
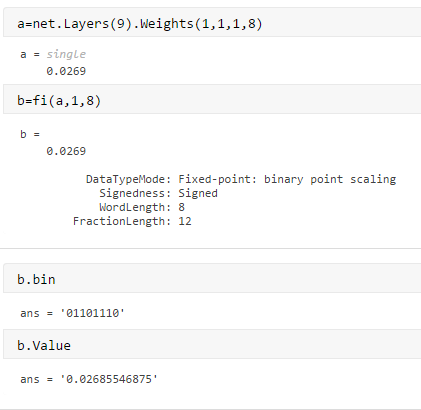
现在让我们考虑这一层的所有权重。使用FI.再一次,我们发现,对于卷积层中的所有权重,给出最佳精度的比例因子是2^-8。我们在直方图中可视化权重的动态范围的分布。从直方图可以看出,大部分权重分布在2^-3和2^-9的范围内(图1),这也说明了权重分布的对称性。
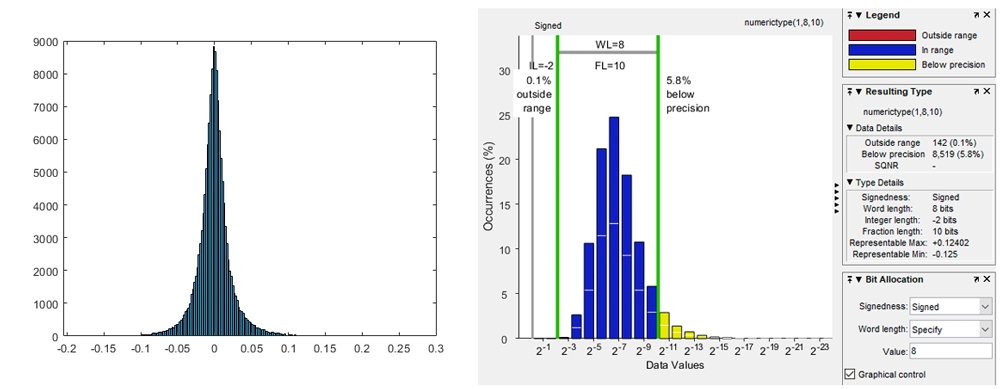
图1所示。VGG16中卷积层权值的分布。
此示例显示了一种方式来量化和表示8位整数。有几个其他替代方案:
通过考虑精度的权衡选择一个不同的比例因子.因为我们选择了2^-8的比例因子,近22%的权重低于精度。如果我们选择2^-10的比例因子,只有6%的权重会低于精度,但0.1%的权重会超出范围。误差分布和最大绝对误差也说明了这种权衡(图2)。我们可以选择16位整数,但这样我们将使用两倍的位。另一方面,使用4位将导致严重的精度损失或溢出。
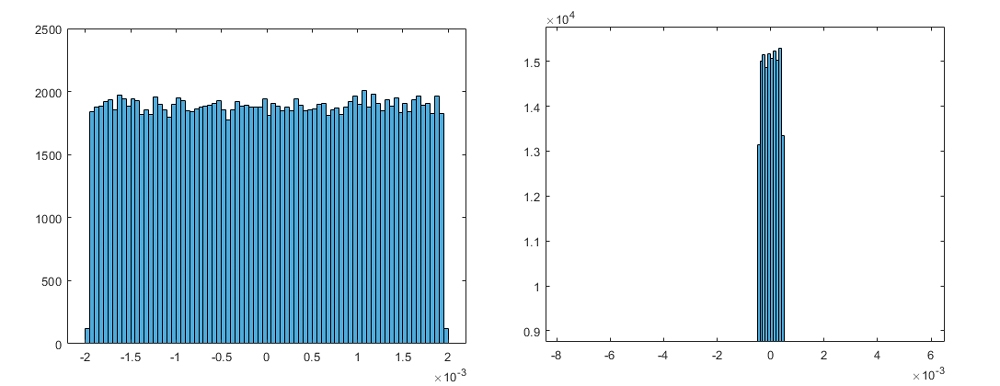
图2。比例因子为2^-8(左)和2^-10(右)的误差的直方图分布及其对应的最大绝对误差。
在调用时指定偏差FI.,基于权重的分配。
\ [real \ _number =存储\ _integer * scaling \ _factor + bias \]
您可以对任何网络进行类似的分析 - 说,Reset50或Yolo - 并识别整数数据类型或缩放因子,其可以在特定公差内表示权重和偏置。
使用int8用整数表示数据有两个关键好处:
- 您可以将数据存储要求减少为4,因为单精度浮点需要32位来表示数字。结果是用于存储所有权重和偏置的内存以及在传输所有数据时消耗的功率的记忆,因为能量消耗由内存访问主导。
- 根据目标硬件,您可以使用整数计算而不是浮点数学来获得进一步加速。例如,您可能能够在NVIDIA GPU上使用半精度浮点。大多数CPU不支持本机半计算。万博1manbetx但是,所有目标都支持整数数学,有些也提供了某万博1manbetx些目标特定内在内部,例如SIMD支持,可以在使用底层计算的整数时提供显着的加速。
量化网络到INT8
量化背后的核心思想是神经网络对噪声的弹性;特别是深度神经网络,它被训练得能够识别关键模式并忽略噪声。这意味着网络可以应对量化误差导致的网络权重和偏差的微小变化,而且越来越多的工作表明量化对整个网络的准确性影响最小。这使得量化成为将神经网络部署到嵌入式硬件的一种有效方法,再加上显著减少内存占用、功耗和提高计算速度[1,2]。
我们将把上面讨论的想法应用到网络中。为了简单起见,我们将使用一个简单的网络来进行MNIST数字分类,它由两层组成。用于图像分类和目标检测的深度网络,如VGG16或ResNet,包括多种层次。卷积层和全连接层是内存和计算最密集的层。
我们的网络模拟了这两层的特性。我们在Simulink中对这个网络建模万博1manbetx®这样我们就可以观察信号流,并进一步了解计算的本质(图3)。
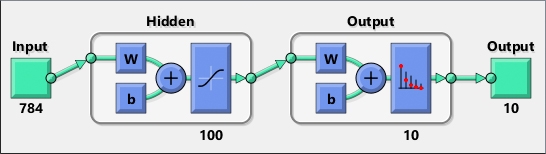
图3. Mnist网络。
在每层中,我们将用缩放的Int8整数替换权重和偏置,然后将矩阵乘法的输出与固定指数乘以重新扫描。当我们在验证数据集上验证修改的网络的预测时,混淆矩阵显示INT8表示仍保持95.9%的精度(图4)。
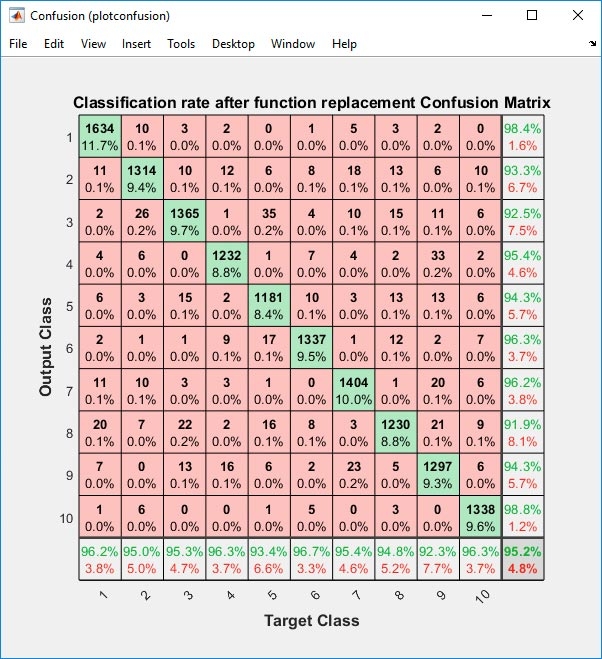
图4。缩放MNIST的混淆矩阵.
为了理解将权值和偏差量化到int8的效率收益,让我们将这个网络部署到一个嵌入式硬件目标—在本例中,一个ST发现板(STM32F746G.).我们将分析两个关键指标:
- 内存使用情况
- 运行时执行性能
当我们尝试部署原始模型(在双精度浮点中)时,它甚至不适合板,并且RAM溢出。最简单的解决方法是将权重和偏差转换为单个数据类型。该模型现在适用于目标硬件,但仍有改进的空间。
我们使用使用int8的权重和偏差矩阵的比例模型,但计算仍然是单一精度(图5)。
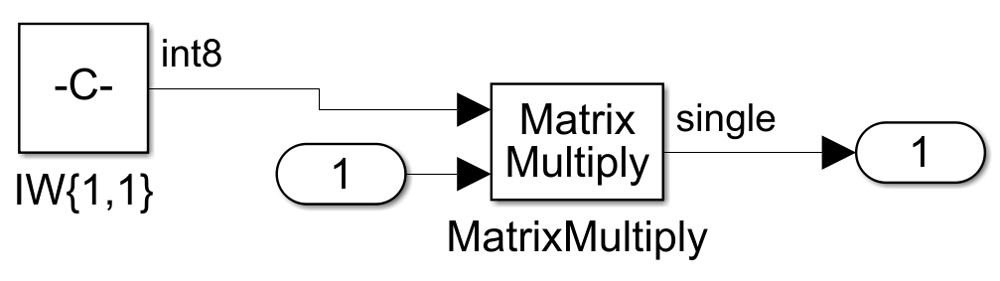
图5。第1层的矩阵乘法。权值是int8,但是输入数据是单精度的,底层计算也是单精度的。
如预期的那样,生成的代码消耗的内存少了4x(图6)。
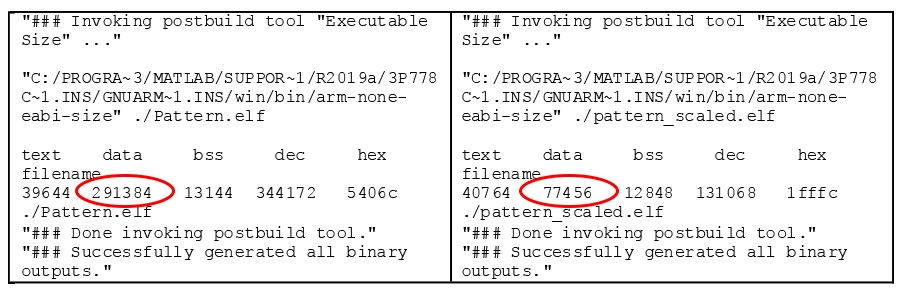
图6.左:单精度代码。右:INT8代码。
然而,在发现板上的执行时间显示,单精度版本平均运行14.5毫秒(大约69帧每秒),而缩放版本稍微慢一点,平均运行19.8毫秒(大约50帧每秒)。这可能是因为对单一精度的强制转换的开销,因为我们仍然在单一精度中进行计算(图7)。
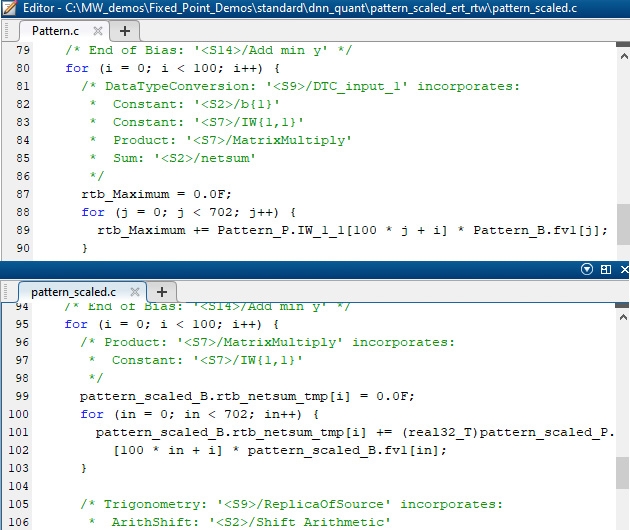
图7。顶部:为单精度生成的代码。底部:按比例缩小的版本。
此示例仅涵盖了INT8中量化存储权重和偏差的一个方面。通过将相同的原则应用于标准的现成网络,如alexNet和vgg,您可以通过3x [1]来降低它们的内存占用空间。
例如,TensorFlow支持以两种形式对8位进行训练后量化——即带有浮点核的权值和权值和激活[3]的全整数量化。TensorFlow使用带有偏差的比例因子映射到int8范围[-128,127],NVIDIA TensorRT通过确定一个阈值来避免偏差的需要,该阈值可以最小化信息损失,并饱和阈值范围[4]之外的值。
为了利用全整数量化的好处,我们还需要将每个层的输入缩放或转换为整数类型。这需要我们确定图层输入的正确缩放,然后在整数乘法之后重新缩放。但是,int8是正确的数据类型吗?是否会出现溢出?网络的准确性是否可以接受?
这些问题是定点分析的本质 - 实际上,数字识别文档示例说明了如何使用定点数据类型转换Mnist网络[5]。在该示例中所示的步骤之后,我们提出了一个8位表示,其重量在1%以下的精度下降(图8)。
图8。模型转换为使用16位字长。
生成的代码不仅只有原来的四分之一大小;它也更快,11毫秒~ 90帧每秒(图9)。

图9。左:从定点模型生成的代码。右:从MNIST网络的第一层缩放权重。
其他量化技术
我们只研究了一些正在研究和探索的许多策略,以优化嵌入式部署的深度神经网络。例如,第一层中的权重为100x702的大小,仅由192个唯一值组成。可以应用的其他量化技术包括以下内容:
- 通过聚类权值进行权值共享,并使用Huffman编码减少权值[1]。
- 量化权重到最接近的2的幂。这大大加快了计算速度,因为它用更快的算术移位操作取代了乘法操作。
- 将激活函数替换为查找表以加快激活函数的计算,例如
塔尼和经验值.例如,在图9所示的生成代码中,我们可以通过替换塔尼功能与查找表。
深度学习应用不仅仅是网络。您还需要考虑应用程序的预处理和后处理逻辑。我们讨论的一些工具和技术已经用于量化这类算法几十年了。它们不仅可以量化网络,还可以量化整个应用程序。
你可以在MATLAB中探索所有这些优化思想。您可以探索量化以进一步限制精度整数数据类型(如int4)的可行性和影响,或者探索浮点数据类型(如半精度)。结果可能是令人印象深刻的:Song、Huizi和william[1]使用了这些技术的组合,分别将AlexNet和VGG等网络的大小减少了35倍和49倍。