文档帮助中心文档
音频工具箱™ 提供为音频、语音和声学应用(包括说话人识别、语音命令识别、声学场景识别等)开发机器和深度学习解决方案的功能。万博 尤文图斯
使用音频数据存储接收大型音频数据集并并行处理文件。
音频数据存储
使用音频贴标机通过手动和自动注释音频记录来构建音频数据集。
使用音频数据增强器创建内置或自定义信号处理方法的随机管道,用于增强和合成音频数据集。
音频数据增强器
使用音频特征提取器在共享中间计算的同时提取不同特征的组合。
音频特征提取器
“音频工具箱”还提供对文本到语音和语音到文本的第三方API的访问,它包括预训练的VGISH和YAMNet模型,以便您可以执行迁移学习、声音分类和提取特征嵌入。使用预先训练的网络需要深入的学习™.
训练深度学习模型,检测音频中是否存在语音命令。该示例使用语音命令数据集[1]来训练卷积神经网络以识别给定的命令集。
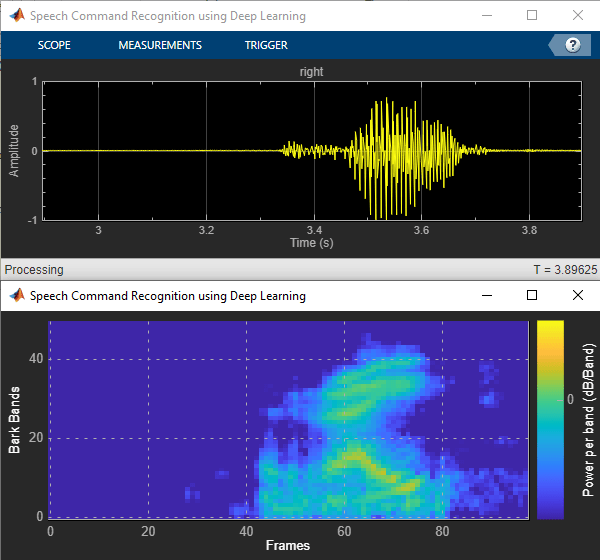
在英特尔处理器上部署用于语音命令识别的特征提取和卷积神经网络(CNN)。要生成特征提取和网络代码,请使用MATLAB编码器和“英特尔深度神经网络数学内核库”(MKL-DNN)。在本例中,生成的代码是MATLAB可执行(MEX)函数,由显示预测语音命令以及时域信号和听觉频谱图的MATLAB脚本调用。有关音频预处理和网络培训的详细信息,请参阅使用深度学习的语音命令识别。
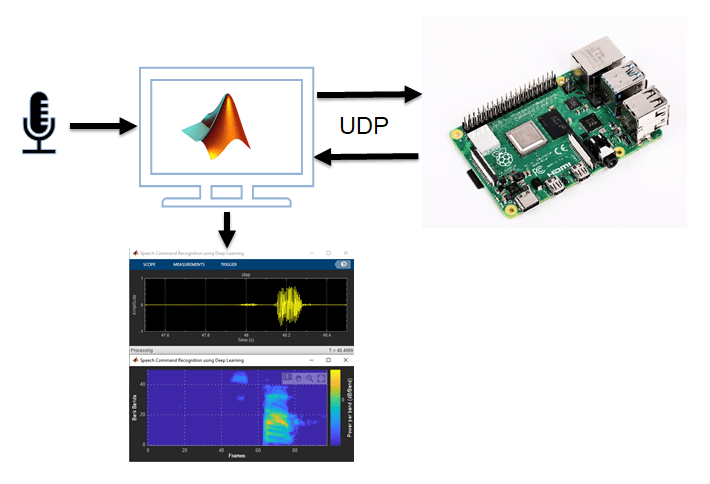
将特征提取和卷积神经网络(CNN)用于树莓Pi语音命令识别™. 要生成特征提取和网络代码,请使用MATLAB编码器、Raspberry Pi硬件的MATLAB支持包和ARM®计算库。在本例中,生成的代码是Raspberry Pi上的一个可执行文件,由显示预测语音命令以及信号和听觉频谱图的MATLAB脚本调用。MATLAB脚本和Raspberry Pi上的可执行文件之间的交互使用用户数据报协议(万博1manbetxUDP)进行处理。有关音频预处理和网络培训的详细信息,请参阅使用深度学习的语音命令识别。
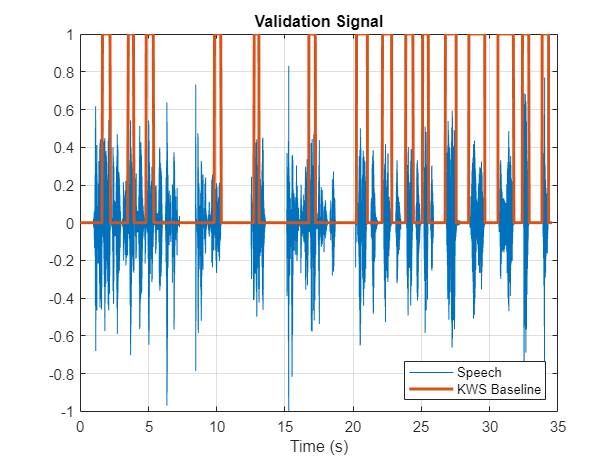
使用深度学习网络识别含噪语音中的关键词。具体而言,该示例使用双向长短时记忆(BiLSTM)网络和mel频率倒谱系数(MFCC)。
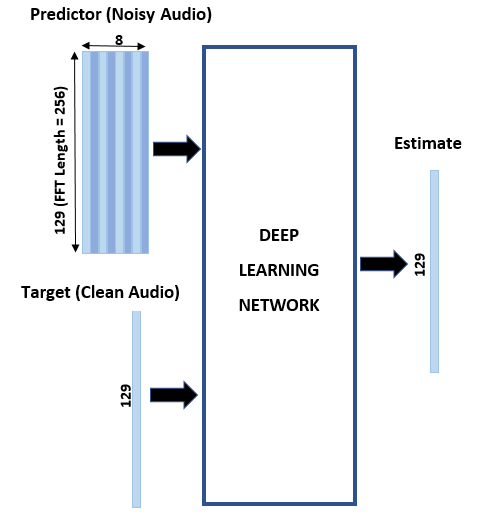
使用深度学习网络对语音信号进行去噪。该示例比较了应用于同一任务的两种类型的网络:完全连接网络和卷积网络。
使用深度学习网络隔离语音信号。
训练并使用生成性对抗网络(GAN)生成声音。
演示了一种基于从录制的语音中提取的特征来识别人员的机器学习方法。用于训练分类器的特征是语音浊音段的基音和mel频率倒谱系数(MFCC)。这是一个闭合集扬声器识别:将被测扬声器的音频与所有可用扬声器型号(有限集)进行比较,并返回最接近的匹配。
说话人验证或认证的任务是确认说话人的身份是他们声称的身份。说话人验证多年来一直是一个活跃的研究领域。早期的性能突破是在声学特征(通常是mfcc)上使用高斯混合模型和通用背景模型(GMM-UBM)[1]。例如,请参阅使用高斯混合模型的说话人验证。GMM-UBM系统的主要困难之一涉及会话间的可变性。提出了联合因子分析(JFA),通过分别建模说话人间可变性和信道或会话可变性来补偿这种可变性[2][3]。然而,[4]发现JFA中的信道因素也包含关于说话人的信息,并建议将信道和说话人空间组合成一个总的可变性空间。然后使用后端程序(如线性判别分析(LDA)和类内协方差归一化(WCCN))对会话间可变性进行补偿,然后是评分,如余弦相似性评分。[5]建议用概率LDA(PLDA)模型取代余弦相似性评分。[11]和[12]提出了一种对i向量进行高斯化的方法,从而在PLDA中进行高斯假设,称为G-PLDA或简化PLDA。虽然i向量最初用于说话人验证,但它们已被应用于许多问题,如语言识别、说话人二值化、情感识别、年龄估计和反欺骗fing[10]。最近,有人提出了用d向量或x向量代替i向量的深度学习技术[8][6]。
使用端到端深度学习网络进行独立于说话人的语音分离。
在进入该项目之前,您必须遵守以下规定:
在澳大利亚的MATLAB中,您的名字是durch Eingabe。韦伯·朗瑟·恩特森·基恩·贝维尔。
选择一个网站以获取翻译后的内容(如果可用),并查看本地活动和优惠。根据您的位置,我们建议您选择:.
您还可以从以下列表中选择网站:
选择中国站点(中文或英文)以获得最佳站点性能。其他MathWorks国家/地区网站未针对您所在地的访问进行优化。
联系当地办事处
现在受审