基于卷积神经网络的文本数据分类
这个例子展示了如何使用卷积神经网络对文本数据进行分类。
要使用卷积对文本数据进行分类,必须将文本数据转换为图像。要做到这一点,填充或截断观测值使其具有恒定的长度年代并将文档转换为长度的单词向量序列C使用单词嵌入。然后可以将文档表示为1-by-年代——- - - - - -C图像(高度为1,宽度为1的图像年代,C渠道)。
要将文本数据从CSV文件转换为图像,请创建tabularTextDatastore对象。转换从tabularTextDatastore对象到图像的深度学习通过调用变换使用自定义转换函数。的transformTextData函数,列在示例的最后,从数据存储读取数据和预先训练的单词嵌入,并将每次观察结果转换为单词向量数组。
这个例子用不同宽度的一维卷积滤波器训练网络。每个过滤器的宽度对应于过滤器可以看到的单词数(n-gram长度)。该网络具有多个卷积层分支,因此可以使用不同的n元长度。
加载预先训练的词嵌入
加载预先训练的fastText单词嵌入。此功能需要文本分析工具箱™模型用于快速文本英语160亿令牌词嵌入万博1manbetx支持包。如果没有安装此支万博1manbetx持包,则该函数将提供下载链接。
emb = fastTextWordEmbedding;
加载数据
从中的数据创建一个表格文本数据存储factoryReports.csv.读取数据“描述”和“类别”只列。
filenameTrain =“factoryReports.csv”;textName =“描述”;labelName =“类别”;ttdsTrain = tabularTextDatastore (filenameTrain,“SelectedVariableNames”, (textName labelName]);
预览数据存储。
ttdsTrain。ReadSize = 8;预览(ttdsTrain)
ans =8×2表类别描述 _______________________________________________________________________ ______________________ {' 项目是偶尔陷于扫描器线轴。机械故障装配工的活塞发出响亮的咔哒咔哒声和砰砰声。{'机械故障' '启动工厂时电源被切断了。' '电子故障' ' '汇编器中的电容器损坏。' '电子故障' '混频器跳闸保险丝。{' '电子故障' '}' '施工剂喷淋冷却剂的管道爆裂。{'漏'{'混合器里的保险丝烧断了。{' '电子故障' ' '东西继续从传送带上滚下来。{'机械故障'}
创建自定义转换函数,将从数据存储读取的数据转换为包含预测器和响应的表。的transformTextData函数,列在示例的最后,接受从tabularTextDatastore对象,并返回一个包含预测器和响应的表。预测是1-by-sequenceLength——- - - - - -C由单词嵌入给出的单词向量的数组循证,在那里C为嵌入维数。中的类的响应是分类标签一会.
使用标签读取训练数据中的标签readLabels函数,并查找唯一的类名。
标签= readLabels (ttdsTrain labelName);一会=独特(标签);numObservations =元素个数(标签);
使用transformTextData函数并指定序列长度为14。
sequenceLength = 14;tdsTrain = transform(ttdsTrain, @(data) transformTextData(data,sequenceLength,emb,classNames))
tdsTrain = TransformedDatastore属性:UnderlyingDatastore:TabularTextDatastore] 万博1manbetxSupportedOutputFormats: ["txt" "csv" "xlsx" "xls" "parquet" "parq" "png" "jpg" "jpeg" "tif" "tiff" "wav" "flac" "ogg" "mp4" "m4a"] Transforms:{@(数据)transformTextData(data,sequenceLength,emb,classNames)} IncludeInfo: 0
预览转换后的数据存储。预测是1-by-年代——- - - - - -C数组,年代序列长度是和吗C为特征个数(嵌入维数)。响应是分类标签。
预览(tdsTrain)
ans =8×2表预测器响应_________________ __________________ {1×14×300 single}机械故障{1×14×300 single}机械故障{1×14×300 single}电子故障{1×14×300 single}电子故障{1×14×300 single}电子故障{1×14×300 single}泄漏{1×14×300 single}电子故障{1×14×300 single}机械故障
定义网络体系结构
定义分类任务的网络架构。
下面的步骤描述了网络架构。
指定输入大小为1-by-年代——- - - - - -C,在那里年代序列长度是和吗C为特征个数(嵌入维数)。
对于长度为n-gram的2、3、4和5,创建包含卷积层、批处理正常化层、ReLU层、dropout层和max pooling层的层块。
对于每个块,指定大小为1 × -的200个卷积滤波器N以及大小为1 × -的区域池年代,在那里N是n格的长度。
将输入层连接到每个块,并使用深度级联层将块的输出连接起来。
要对输出进行分类,需要包含一个具有输出大小的全连接层K, softmax层和分类层,其中K为类数。
首先,在一个层数组中,指定输入层、unigrams的第一个块、深度连接层、完全连接层、softmax层和分类层。
numFeatures = emb.Dimension;inputSize = [1 sequenceLength numFeatures];numFilters = 200;ngramlength = [2 3 4 5];numBlocks =元素个数(ngramLengths);numClasses =元素个数(类名);
创建一个包含输入层的层图。将规范化选项设置为“没有”图层名称为“输入”.
层= imageInputLayer (inputSize,“归一化”,“没有”,“名字”,“输入”);lgraph = layerGraph(层);
对于每个n-gram长度,创建一个由卷积、批处理归一化、ReLU、dropout和max pooling层组成的块。将每个块连接到输入层。
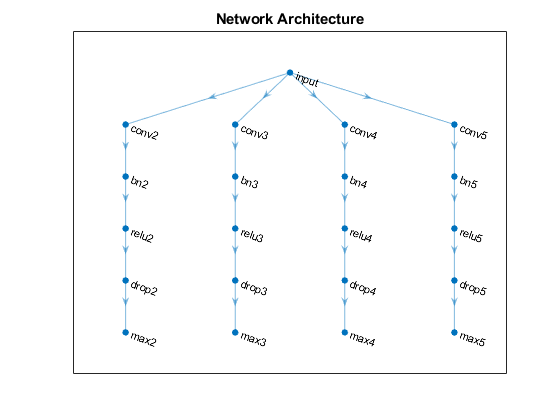
为j = 1:numBlocks N = ngramlength (j);block =[卷积2dlayer ([1 N],numFilters,“名字”,“conv”+ N,“填充”,“相同”) batchNormalizationLayer (“名字”,“bn”+ N) reluLayer (“名字”,“relu”+ N) dropoutLayer (0.2,“名字”,“下降”+ N) maxPooling2dLayer ([1 sequenceLength],“名字”,“马克斯”+ N));lgraph = addLayers (lgraph块);lgraph = connectLayers (lgraph,“输入”,“conv”+ N);结束
在图中查看网络结构。
图绘制(lgraph)标题(“网络架构”)
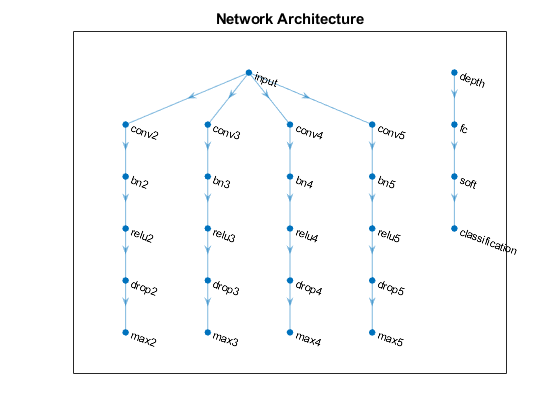
添加深度级联层、全连接层、softmax层和分类层。
[depthConcatenationLayer(numBlocks,“名字”,“深度”) fullyConnectedLayer (numClasses“名字”,“俱乐部”) softmaxLayer (“名字”,“软”) classificationLayer (“名字”,“分类”));lgraph = addLayers (lgraph层);图绘制(lgraph)标题(“网络架构”)
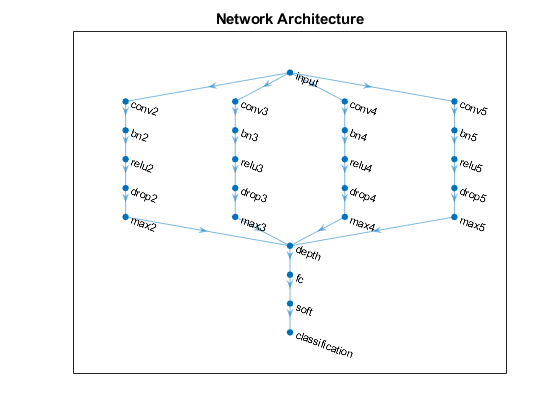
将最大池化层连接到深度级联层,并在图中查看最终的网络架构。
为j = 1:numBlocks N = ngramlength (j);lgraph = connectLayers (lgraph,“马克斯”+ N,“深度/”+ j);结束图绘制(lgraph)标题(“网络架构”)
列车网络的
指定培训选项:
用128的小批量训练。
不要打乱数据,因为数据存储是不可打乱的。
显示训练进度图并抑制冗长的输出。
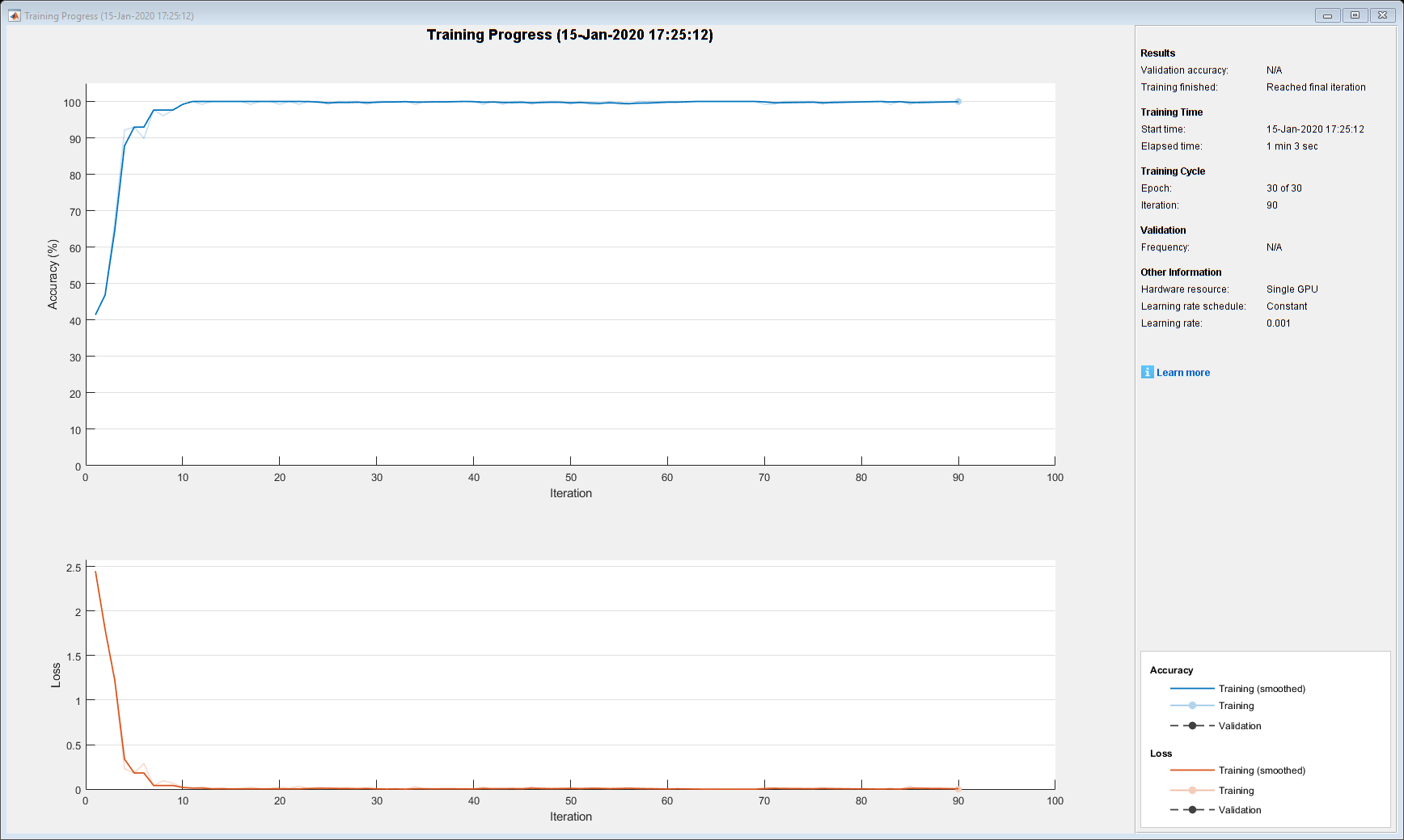
miniBatchSize = 128;numIterationsPerEpoch =地板(numObservations / miniBatchSize);选择= trainingOptions (“亚当”,...“MiniBatchSize”miniBatchSize,...“洗牌”,“永远”,...“阴谋”,“训练进步”,...“详细”、假);
训练网络使用trainNetwork函数。
网= trainNetwork (tdsTrain、lgraph选项);
使用新数据进行预测
对三个新报告的事件类型进行分类。创建包含新报告的字符串数组。
reportsNew = [“冷却剂在分拣机下面汇集。”“分类器在启动时烧断保险丝。”“从组装器里传出很响的咔哒声。”];
将预处理步骤作为训练文档对文本数据进行预处理。
XNew = preprocessText (reportsNew、sequenceLength emb);
用训练好的LSTM网络对新的序列进行分类。
XNew labelsNew =分类(净)
labelsNew =3×1分类泄漏电子故障机械故障
阅读标签功能
的readLabels函数创建tabularTextDatastore对象运输大亨读标签labelName列。
函数标签= readLabels(ttds,labelName) ttdsNew = copy(ttds);ttdsNew。选择edVariableNames = labelName; tbl = readall(ttdsNew); labels = tbl.(labelName);结束
转换文本数据函数
的transformTextData函数接受从对象读取的数据tabularTextDatastore对象,并返回一个包含预测器和响应的表。预测是1-by-sequenceLength——- - - - - -C由单词嵌入给出的单词向量的数组循证,在那里C为嵌入维数。中的类的响应是分类标签一会.
函数dataTransformed = transformTextData(数据、sequenceLength emb一会)%预处理文件。数据textData = {: 1};% Prepocess文本dataTransformed = preprocessText (textData、sequenceLength emb);%阅读标签。数据标签= {:2};反应=分类(标签、类名);%将数据转换为表。dataTransformed。=反应的反应;结束
文本预处理功能
的preprocessTextData函数获取文本数据、序列长度和单词嵌入,并执行以下步骤:
在标记文本。
将文本转换为小写字母。
使用嵌入将文档转换为指定长度的单词向量序列。
重塑输入到网络中的字向量序列。
函数tbl = preprocessText(textData,sequenceLength,emb) documents = tokenizedDocument(textData);文件=低(文件);%将文档转换为嵌入尺寸按序列长度按1的图像。预测= doc2sequence (emb、文档“长度”, sequenceLength);%重塑图像大小为1-by sequencelength - embedingdimension。= cellfun(@(X) permute(X,[3 2 1])),“UniformOutput”、假);台=表;资源描述。预测=预测;结束
另请参阅
fastTextWordEmbedding(文本分析工具箱)|wordcloud(文本分析工具箱)|wordEmbedding(文本分析工具箱)|layerGraph|convolution2dLayer|batchNormalizationLayer|trainingOptions|trainNetwork|doc2sequence(文本分析工具箱)|tokenizedDocument(文本分析工具箱)|变换
相关的话题
- 使用深度学习对文本数据进行分类(文本分析工具箱)
- 使用自定义小批量数据存储对内存不足的文本数据进行分类(文本分析工具箱)
- 为分类创建简单的文本模型(文本分析工具箱)
- 使用主题模型分析文本数据(文本分析工具箱)
- 使用多词短语分析文本数据(文本分析工具箱)
- 训练情感分类器(文本分析工具箱)
- 基于深度学习的序列分类
- 用于深度学习的数据存储
- MATLAB中的深度学习
你也可以从以下列表中选择一个网站:
