设计模式
GPU编码器™支持一些万博1manbetx有效映射到GPU结构的设计模式。
模板处理
Stencil内核操作将输出数组的每个元素作为输入数组的一个小区域的函数来计算。可以将许多过滤操作表示为模板操作。例子包括卷积、中值滤波和有限元方法。
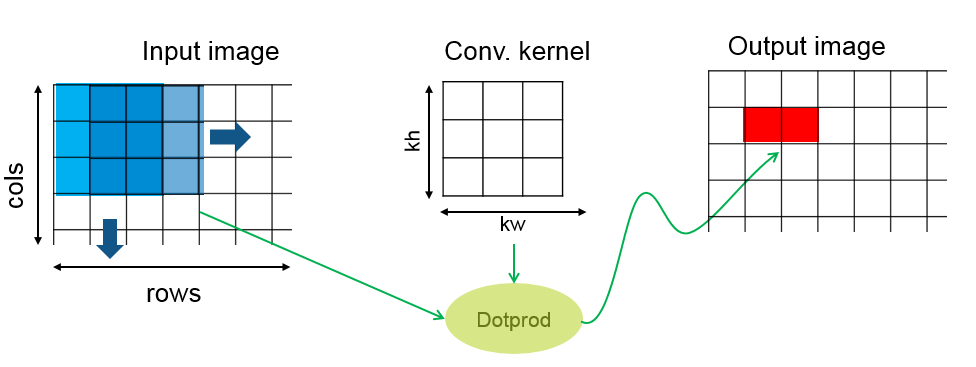
在模板内核的GPU编码器实现中,每个线程计算输出数组的一个元素。由于给定的输入元素被反复访问以计算多个相邻的输出元素,GPU编码器使用共享内存来提高内存带宽和数据局域性。
使用gpucoder.stencilKernel函数并创建CUDA®模板函数的代码。有关演示模板处理的示例,请参见图形处理器上的模板处理.
对于非常大的输入尺寸,gpucoder.stencilKernel函数可能产生与MATLAB在数值上不匹配的CUDA代码®模拟。在这种情况下,考虑减少输入的大小以产生准确的结果。
矩阵与矩阵的处理
许多科学应用都包含矩阵-矩阵运算,包括一般矩阵到矩阵乘法(GEMM)的形式C = AB你可以选择转置一个和B.这种矩阵-矩阵运算的代码通常采用以下模式:
为x = 1: M为y = 1: N为K (x,y) = F(A(x,z),B(z,y));结束结束结束
在哪里F ()是用户定义的函数。在这些操作中,使用一个输入矩阵的行和第二个输入矩阵的列来计算输出矩阵的相应元素。每个线程都重新加载行和列。这种设计模式允许通过重用数据和让每个线程计算多个输出元素来优化这种结构。
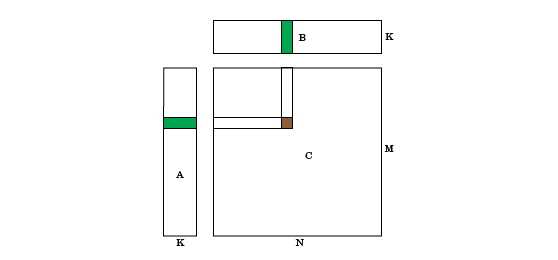
例如,F ()可以是正则矩阵乘法,F () = @mtimes.对于这种模式,GPU编码器提供MatrixMatrix内核创建一个高效、快速的矩阵运算在GPU上的实现。
使用gpucoder.matrixMatrixKernel函数并创建用于执行矩阵-矩阵类型操作的CUDA代码。
另请参阅
coder.gpu.kernel|coder.gpu.kernelfun|gpucoder.matrixMatrixKernel|coder.gpu.constantMemory|gpucoder.stencilKernel
相关的例子
更多关于
你也可以从以下列表中选择一个网站:
