主要内容
最大似然估计
的大中型企业函数计算由其名称指定的分布和由其概率密度函数(pdf)、日志pdf或负对数似然函数指定的自定义分布的最大似然估计(MLEs)。
对于某些分布,MLEs可以用封闭形式直接给出并计算。对于其他分布,必须使用最大似然搜索。可以使用选项输入参数,使用statset函数。为了提高搜索效率,选择合理的分布模型并设置适当的收敛容限是非常重要的。
MLEs可能有偏差,特别是对于小样本。然而,随着样本量的增加,MLEs成为近似正态分布的无偏最小方差估计量。这用于计算估计的置信范围。
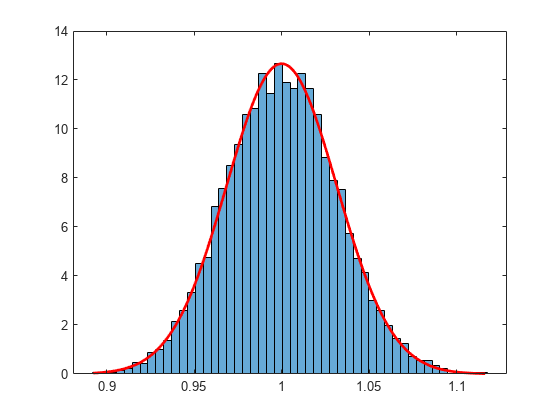
例如,考虑以下指数分布的重复随机样本的均值分布:
μ= 1;%总体参数n = 1 e3;%样本大小ns = 1 e4;%样本数量rng ('默认')%的再现性样品= exprnd(μ,n, ns);%的人口样本意味着=意味着(样本);%样本均值
中心极限定理说,不管样本中的数据如何分布,均值都近似正态分布。的大中型企业函数可以找到最适合均值的正态分布:
(太好了,pci) =企业(意味着)
太好了=1×21.0000 - 0.0315
pci =2×20.9994 0.0311 1.0006 0.0319
太好了(1)和太好了(2)为均值和标准差的MLEs。pci (: 1)和pci (: 1)为相应的95%置信区间。
将样本均值的分布与拟合的正态分布形象化。
numbins = 50;直方图(意味着,numbins,“归一化”,“pdf”)举行在x = min(手段):0.001:max(手段);y = normpdf(x,phat(1),phat(2));绘图(x,y,“r”,“线宽”,2)
另请参阅
相关话题
你也可以从以下列表中选择一个网站:
