无监督机器学习在没有标记响应的数据集中寻找模式。
当您想要探索数据,但还没有特定的目标,或者不确定数据包含什么信息时,可以使用这种技术。
这也是一种降低数据维数的好方法。
正如我们之前讨论过的,大多数无监督学习技术都是聚类分析的一种形式,它根据共享特征将数据分成组。
聚类算法分为两大类:
- 硬聚类,每个数据点只属于一个聚类
- 软聚类,每个数据点可以属于多个聚类
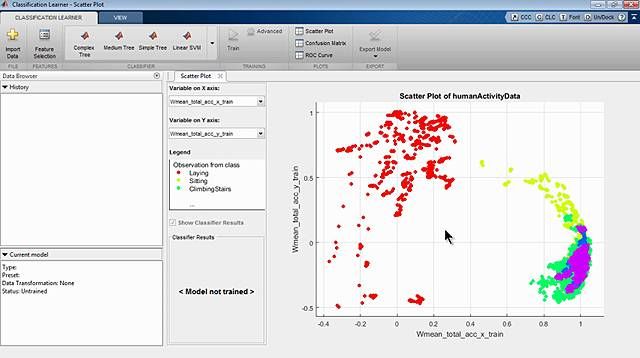
下面是一个硬聚类的例子:
假设你是建造手机信号塔的工程师。你需要决定在哪里建造塔,建造多少塔。为了确保你能提供最好的信号接收,你需要在人群中定位信号塔。
首先,您需要初步猜测集群的数量。为了做到这一点,比较三个塔和四个塔的场景,看看每个塔提供服务的能力如何。
因为一个电话一次只能与一个信号塔通话,所以这是一个困难的聚类问题。
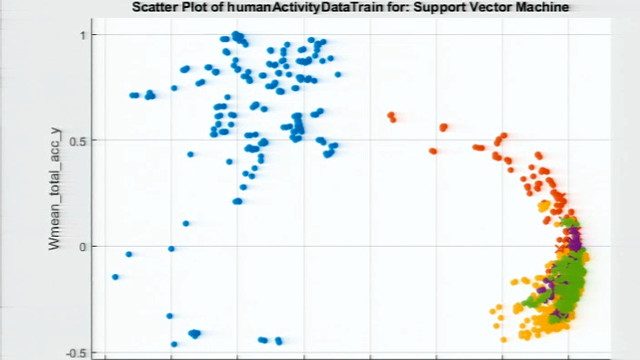
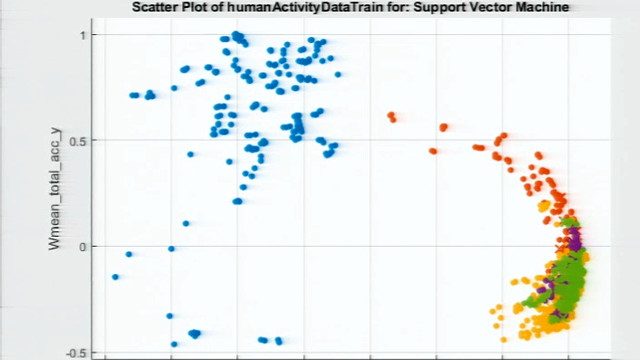
为此,您可以使用k-means聚类,因为k-means算法将数据中的每个观察结果视为在空间中具有位置的对象。它寻找聚类中心,或减少从数据点到它们的聚类中心的总距离的方法。
所以,这是很难的集群。让我们看看如何在现实世界中使用软聚类算法。
假设你是一位生物学家,正在分析与正常和异常细胞分裂有关的基因。你有两个组织样本的数据,你想比较它们,以确定某些基因特征模式是否与癌症相关。
因为相同的基因可以参与多个生物过程,所以没有一个基因可能只属于一个集群。
对数据应用模糊c均值算法,然后将聚类可视化,看看哪些基因组的行为方式相似。
然后,您可以使用这个模型来帮助查看哪些特征与正常或异常的细胞分裂相关。
本文涵盖了用于探索具有未标记响应的数据的两种主要技术(硬聚类和软聚类)。
不过请记住,您还可以使用无监督机器学习来减少数据的特征数量或维数。
这样做是为了让数据不那么复杂——特别是在处理具有数百或数千个变量的数据时。通过降低数据的复杂性,您可以专注于重要的特性并获得更好的见解。
让我们看看3种常见的降维算法:
- 主成分分析(PCA)对数据执行线性转换,以便数据集中的大部分方差被前几个主成分捕获。这可能有助于开发用于机器运行状况监视的状态指示器。
- 因子分析确定数据集中变量之间的潜在相关性。它提供了未观察到的潜在或常见因素的表示。因子分析有时被用来解释股票价格的变化。
- 当模型项必须表示非负的量时,如物理量,则使用非负矩阵分解。如果你需要比较网页或文档上的大量文本,这将是一个很好的方法,因为文本要么不存在,要么出现了正数次。
在这个视频中,我们仔细研究了硬聚类算法和软聚类算法,我们还展示了为什么要使用无监督机器学习来减少数据集中的特征数量。
至于你的下一步:
无监督学习可能是你的最终目标。如果您只是希望分割数据,那么聚类算法是一个合适的选择。
另一方面,你可能想使用无监督学习作为监督学习的降维步骤。在下一个视频中,我们将深入了解监督学习。
到此为止,本视频就到此结束。不要忘记查看下面的描述以获取更多资源和链接。