设计和实现控制技术,以满足系统目标
最优控制是动态系统满足设计目标的条件。最优控制是通过控制律来实现的,控制律按照定义的最优性标准执行。一些广泛应用的最优控制技术有:
线性二次调节器(LQR)/线性二次高斯(LQG)控制
线性二次调节器(LQR)是一种全状态反馈最优控制律(u= -Kx),它最小化二次代价函数来调节控制系统。
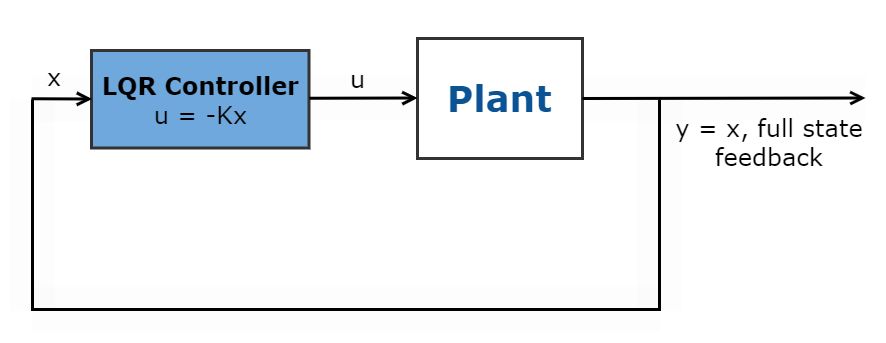
图1所示。线性二次型调节器控制器原理图。
这个代价函数依赖于系统状态\((x)\)和控制输入\((u)\),如下图所示。
$ $ J (u) = \ int_ {0} ^ {\ infty} (x ^ T Qx + u ^ T俄文+ 2 x ^ Tν)dt $ $
在性能指标的基础上,为该最优控制律设置权重因子Q、R、N,以确定系统状态调节与控制驱动成本之间的适当平衡。
在许多最优控制问题中,并不是所有的状态测量都是可访问的。在这些情况下,必须使用观察员来估计状态。这通常是使用一个观察者,如卡尔曼滤波器。卡尔曼滤波器和LQR控制器组成了线性二次高斯(LQG)控制器。
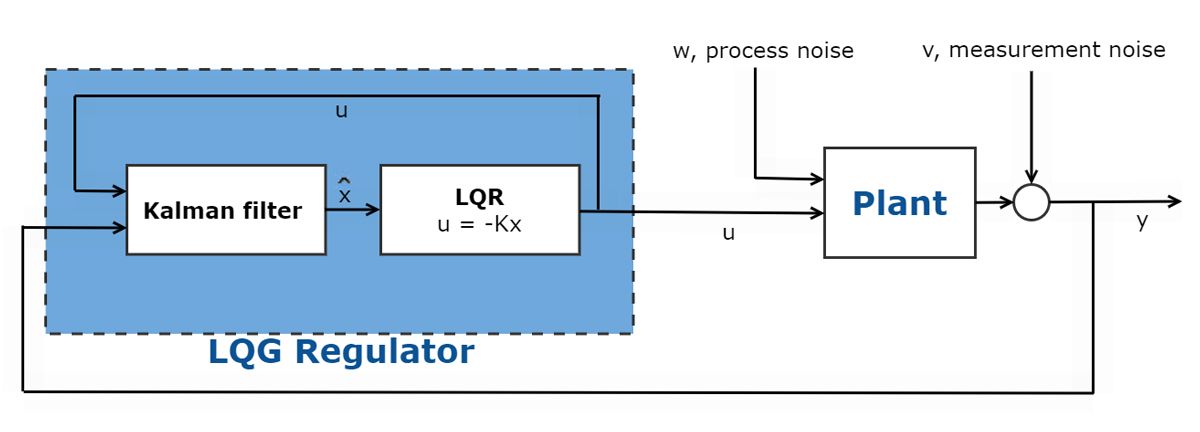
图2所示。线性二次型高斯控制器原理图。
要了解更多,请查看这个MATLAB技术讲座LQR控制。
模型预测控制
模型预测控制(MPC)用于多输入多输出(MIMO)系统中受输入和输出约束的成本函数最小化。这种最优控制技术使用系统模型来预测未来的工厂产量。利用预测的工厂输出,控制器解决了一个在线优化问题,即一个二次程序,以确定对一个可操作变量的最优调整,该变量将预测输出驱动到参考。MPC的变体包括自适应、增益调度和非线性MPC控制器。所使用的MPC控制器类型取决于预测模型(线性/非线性)、约束条件(线性/非线性)、成本函数(二次/非二次)、吞吐量和采样时间。要了解更多,请查看这个MATLAB技术讲座关于MPC变体。
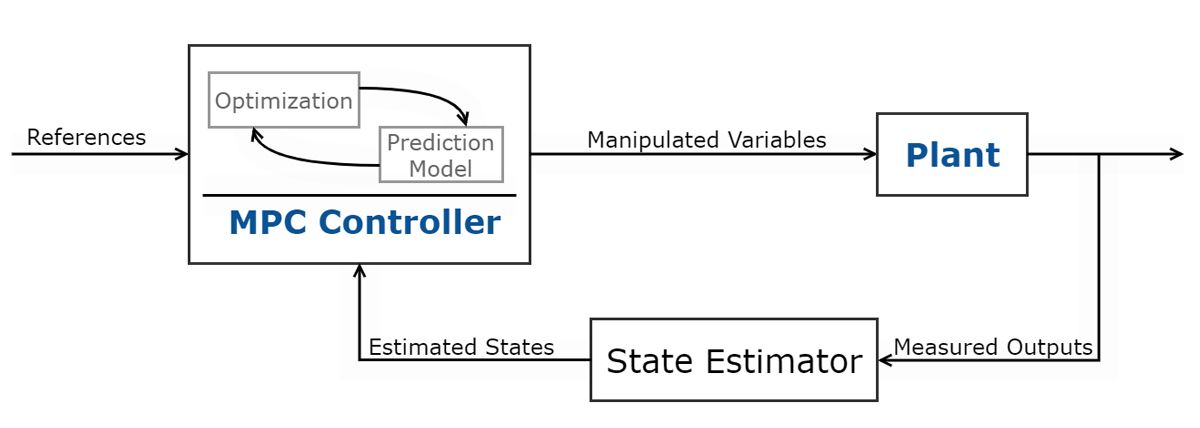
图3所示。模型预测控制原理图。
微处理器技术和高效算法的进步增加了这种最优控制方法在自动驾驶、航空航天应用中的最优地形跟踪等应用中的采用。
要了解更多,请查看这个MATLAB技术讲座系列模型预测控制。
强化学习
强化学习是一种机器学习技术,其中计算机代理通过与动态环境的反复试错交互来学习最佳行为。代理使用来自环境的观察来执行一系列操作,目的是最大化代理对任务的累积奖励指标。这种学习没有人为干预,也没有明确的编程。
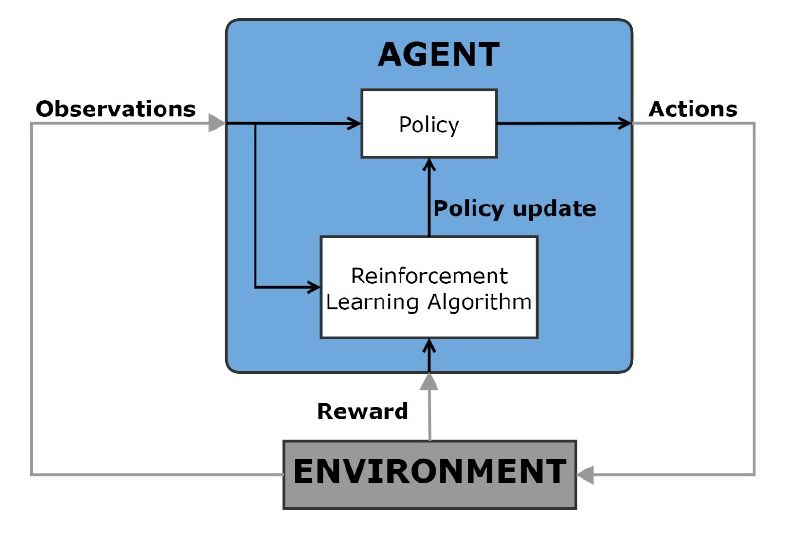
图4所示。强化学习原理图。
这种最优控制方法可用于决策问题,并作为使用传统控制方法的应用程序的非线性控制替代方案,如自动驾驶、机器人、调度问题和系统的动态校准。
要了解更多,请查看这个MATLAB技术讲座系列关于强化学习。
极值求值控制
极值寻优是一种利用无模型实时优化自动调整控制系统参数以使目标函数最大的最优控制技术。该方法不需要系统模型,可用于参数和扰动随时间缓慢变化的系统。这种最优控制技术适用于控制中能够容忍噪声的稳定系统,并且只需要调整少量控制系统参数的情况。
极值搜索控制的应用包括自适应巡航控制、太阳能电池阵列的最大功率点跟踪(MPPT)和防抱死制动系统(ABS)。
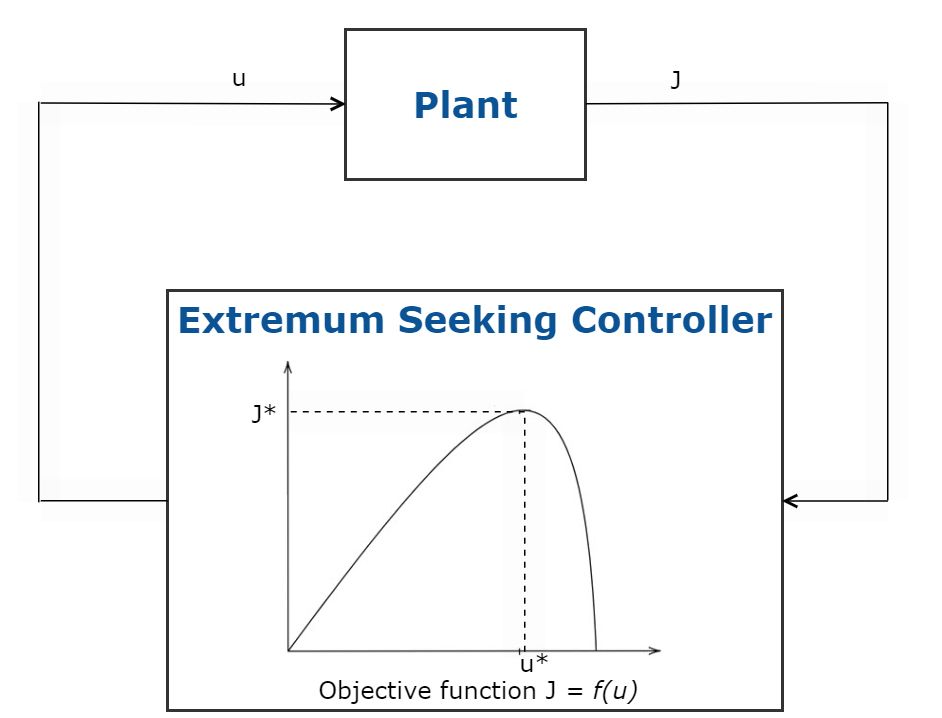
图5所示。极值搜索控制原理图。
摘要针对合成
h∞合成是设计单输入单输出(SISO或MIMO)反馈控制器以实现鲁棒性能和稳定性的最优控制工具/技术。与传统控制技术(如波德环整形或PID整定)相比,h -∞更适合于需要通道间交叉耦合的多变量控制系统。
当h为无穷大时,控制目标用归一化闭环增益来表示。h -∞合成自动计算控制器,通过最小化增益来优化性能。这是很有用的,因为许多控制目标可以用最小化增益来表示。这包括干扰抑制、噪声灵敏度、跟踪、环路整形、环路解耦和鲁棒稳定性等目标。h∞合成的变化可以用来处理固定结构或全阶控制器。
要了解更多,请查看这个MATLAB技术讲座h -∞合成。
下表对上述最优控制方法进行了比较:
| 最优控制方法 | 是否在运行时进行优化?(是/否) | 对于这个最优控制过程,优化过程是如何工作的? | 它能处理硬约束吗?*(是/否) | 它是否使用基于模型的技术?(是/否) | 吞吐量是多少?(高/低) |
|---|---|---|---|---|---|
| 等/ LQG | 没有 | 使用封闭的解这适用于已知的线性时不变系统 | 没有 | 是的 | 高 |
| 隐式MPC(是) | 使用一个预测模型,解决在线优化问题计算最优控制动作 | 是的 | 是的 | 低(非线性MPC),高(线性MPC) | |
| 显式MPC (No) | 解决方案优化问题用于计算最优控制动作离线计算 | 是的 | 是的 | 高 | |
| 强化学习 | 是的* * | 学习任务的最佳行为最大化奖励指标 | 没有* * * | 取决于训练算法 | 低(训练中),中高(推理中) |
| 极值求值控制 | 是的 | 扰动和适应控制参数使目标函数最大化 | 没有 | 没有 | 高 |
| 摘要针对合成 | 没有 | 自动计算控制器最小化归一化闭环增益 | 没有 | 是的 | 高 |
例子和如何
等/ LQG
模型预测控制
强化学习
极值求值控制
摘要针对合成


您也可以从以下列表中选择一个网站: