使用Simulink缓存文万博1manbetx件加速持续集成工作流中的Simulink仿真
作者:Puneet Khetarpal, Marco Dragic, Govind Malleichervu, MathWorks
在敏捷开发工作流中,设计复杂的系统是一项协作工作,大型团队开发组件,组装子系统,并将它们集成到系统设计中。理想情况下,系统仿真是组件设计工作流中不可或缺的验证步骤,使工程师能够验证组件是否满足系统需求。然而,多次模拟具有复杂模型层次结构的系统可能非常耗时。
一种方法是Simulink万博1manbetx®通过在第一次运行模拟时创建一组中间派生工件来加速大型模型引用层次结构的模拟。对于大型团队,共享和重用这些派生文件(包括MEX文件和其他二进制文件)可能具有挑战性。因此,团队成员经常花费时间重建和重新创建团队中其他人已经创建的文件。这种多余的工作消耗了本可以用于更有效的设计活动的时间。团队越大,模型越复杂,问题就越大。
为了解决这个问题,Simulink将这些派生工万博1manbetx件打包并存储在万博1manbetx模型缓存文件。在本文中,我们描述了在典型的敏捷开发工作流中管理和共享Simulink缓存文件的方法,该工作流使用Git™进行源代码控制,使用万博1manbetxJenkins™进行持续集成(CI)。这种方法大大加快了系统模拟的速度。
Simu万博1manbetxlink缓存
当您以加速模式、快速加速模式或模型参考加速模式模拟模型时,Simulink将层次结构中每个模型的派生文件打包到其相应的Simulink缓存文件(SLXC)中。万博1manbetx团队成员可以彼此共享这些SLXC文件和相应的Simulink模型文件。万博1manbetx当团队成员在他们的机器上重复模拟时,Simulink将从SLXC文件中为每个模型提取必要的派生文件。万博1manbetx因此,Simulink不需万博1manbetx要执行不必要的重建,并且仿真完成速度显著加快。
确切的性能改进取决于几个因素,比如层次结构中的模型数量、模型引用重建设置、引用模型中的块数量,以及为每个模型创建的派生文件的大小和数量。在我们对各种系统模型(包含0-500个参考模型和1 - 10级层次结构)的测试中,我们看到了从2倍到34倍以上的改进(图1)。
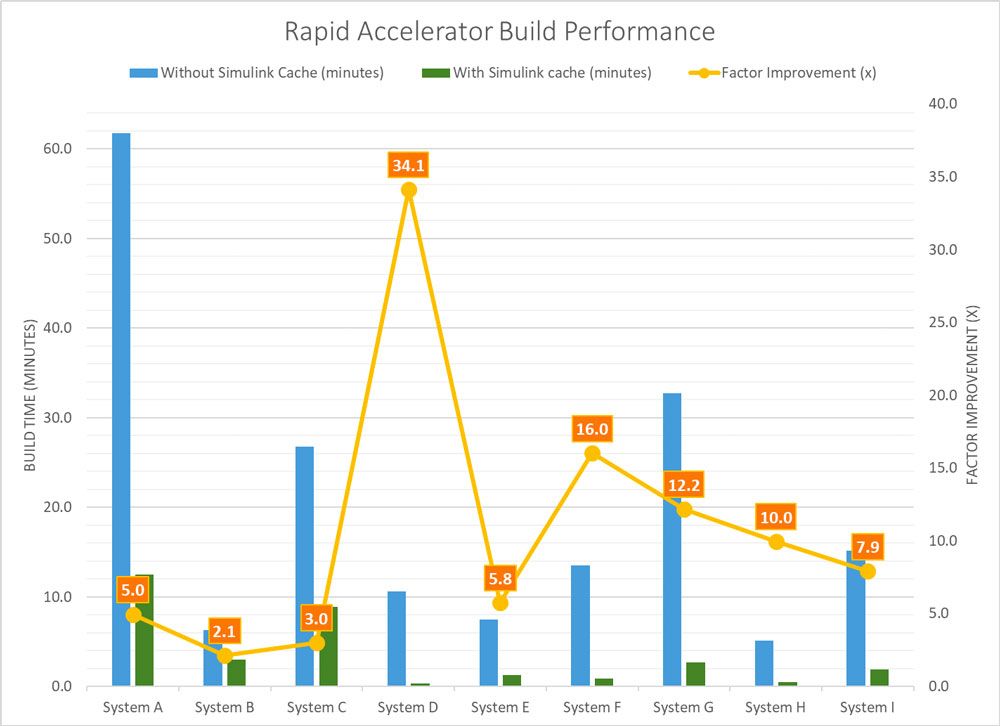
图1。通过对各种系统模型使用Simulink缓存文件实现性能改进。万博1manbetx
在包含Jenkins CI系统的敏捷工作万博1manbetx流中共享和重用Simulink缓存文件分为三个阶段(图2):
- 向Git提交设计更改。
- 集成设计更改并归档SLXC文件。
- Jenkins从Git中提取设计更改,并运行模拟来测试它们。
- Jenkins将Simulink缓存万博1manbetx文件保存在Jenkins构建存档中。
- 同步设计更改和SLXC文件。
- 团队成员同步来自Git的最新设计更改和来自Jenkins构建存档的相关缓存文件。
- 团队成员使用缓存文件运行系统模拟。
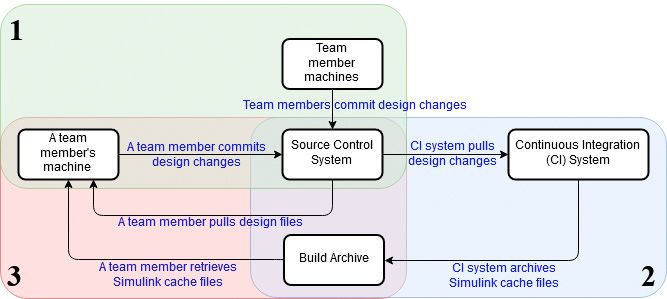
图2。在源代码控制和持续集成系统中重用Simulink缓存文件的典型万博1manbetx工作流。阴影区域描述了工作流的三个阶段。
在更详细地研究这些阶段之前,让我们考虑一下使用Simulink缓存的需求和最佳实践。万博1manbetx
共享和重用Simulink缓存文件的要求和最佳实践万博1manbetx
Simu万博1manbetxlink缓存包含派生文件,这些文件依赖于仿真过程中使用的MATLAB版本、平台和编译器。为了共享和重用这些文件,所有团队成员必须使用相同的MATLAB®发行版、平台和编译器。在本文中,我们使用的是Microsoft的MATLAB R2019a®窗户®,以及Microsoft Visual c++®2017年,分别。
通过重用共享缓存文件,以下最佳实践可以更容易地加速大型分层模型的模拟:
- 遵循基于组件的建模指南适合您的模型。
- 让每个团队成员负责层次结构的一个子集——通常,由几个Simulink模型组成一个组件,例如具有良好定义接口的控制器或设备。万博1manbetx这样可以最大限度地减少合并设计更改时的问题。
- 使用项目与启动和关闭脚本,以确保所有团队成员一致的工作环境。启动脚本在项目打开时初始化环境,关闭脚本在项目关闭时清理环境。
- 引用所有模型加速器模式。要在本地机器上调试引用的模型,请使用正常的模式。但是,此模式不能提供与Accelerator模式相同的模拟性能优势。
- 设置每个模型的重建参数如果检测到任何已知依赖项的变化(图3),并使用模型的依赖性参数指定用户创建的依赖项。这提高了重建检测的速度和准确性。
- 如果您正在使用并行计算工具箱™,请选择启用并行模型参考构建(图3)。模型引用层次结构将自动并行地构建。
- 决定Jenkins构建是在每次提交时运行,还是在一天的特定时间运行,还是按需运行。您的特定需求将决定哪种时机最有效,以及使用以下哪种类型的构建:
- 无菌:一种构建,其中Jenkins工作区清除了以前Jenkins构建中的工件或文件。如果您的团队经常更改Simulink模型配置,请使用无菌构建。万博1manbetx例如,更改Simulink模型层次结构上的硬件设置需要一个干净的工作空间。万博1manbetx
- 增量:保留前一个Jenkins构建中的构件的构建。如果您的团队对单个组件进行了小的增量更改,则使用增量构建。
无菌构建通常比增量构建花费更长的时间,这取决于模型层次结构的大小。

图3。模型配置参数。
向Git提交设计更改
在此步骤中,团队成员修改模型,模拟模型层次结构,运行model Advisor检查,并执行单元测试。他们承诺只有他们的设计文件到一个源代码控制系统,比如Git。万博1manbetx不应将Simulink缓存文件提交给源代码控制系统;它们是派生的二进制文件,可能占用大量磁盘空间,不能进行比较或合并。在Git存储库中,您可以配置.gitignore文件,以便Git忽略所有派生工件,包括SLXC文件。
集成设计变更并归档SLXC文件
有关在Simulink中使用Jenkins的指导和配置技巧,请参阅这篇技术文章万博1manbetx
在本文的其余部分中,我们将使用Simulink Cache和Jenkin万博1manbetxs的示例.
在本例中,Jenkins管理员指定构建命令MATLAB Jenkins插件.该命令启动MATLAB,构建加速器目标,为嵌入式实时目标控制器生成生产C代码,并运行软件在环(SIL)等效测试。图4显示了打开Simulink项目并执行myBuildAndTest脚本的命令。万博1manbetx
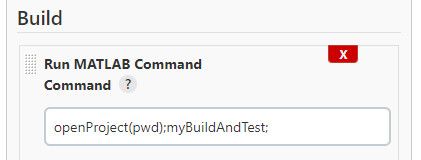
图4。Jenkins Build命令的示例,该命令打开Simulink项目并执行myBuildAndTest脚本。万博1manbetx该脚本为系统构建加速目标,为嵌入式实时目标控制器生成生产C代码,并运行多个模拟来测试更改。
作为仿真和代码生成的一部分,Simulink创建了SLXC文件,其中包含层次结构中所有万博1manbetx模型的加速器和模型参考仿真目标。这些SLXC文件的一个子集包含用于嵌入式实时控制器目标的生产C代码。万博1manbetxSimulink将这些SLXC文件存储在模拟缓存文件夹中。目录中指定了此文件夹的位置项目详细信息(图5)。脚本然后运行多个模拟来测试设计更改。

图5。“项目详细信息”对话框指定存储SLXC文件的缓存文件夹的位置。默认设置为[项目根]。
此外,管理员还要设置一个Post-build行动在Jenkins中存档SLXC文件(图6)。构建之后,Jenkins将SLXC文件从Jenkins工作区复制到构建存档位置。
要指定Jenkins构建存档位置,管理员可以编辑Jenkins主目录中的config.xml文件。
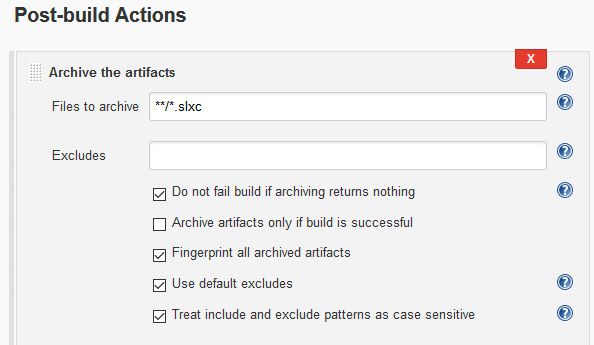
图6。一个Jenkins构建后操作,配置为在构建完成后将所有Simulink缓存文件从Jenkins工作区归档到万博1manbetx构建归档区域。
同步设计更改和SLXC文件
通常,Jenkins构建在夜间执行。然后,每个团队成员都可以基于上一次成功的构建同步沙盒。团队成员从Git中检出设计更改,从构建归档区域检索相关的Simulink缓存文件,并在模拟之前将Simulink缓存文件放在他们的模拟缓存文件夹中。万博1manbetx团队可以设置一个脚本来自动化这个过程。
在这个例子中,syncSLXCForCurrentHash脚本访问一个SQLite数据库来查询成功的构建,找到它对应的Git提交散列,并将SLXC文件从Jenkins中的存档构建区域复制到模拟缓存文件夹中。
增强工作流
有几种方法可以使这个工作流更快、更少出错。为了方便地管理来自多个Jenkins构建的SLXC文件,您可以使用数据库或存储库管理工具,如本例所示。最后,为了进一步扩展模拟性能,可以使用parsim对一定范围的输入参数值运行多个系统模拟。
2022年出版的
查看相关功能的文章
您也可以从以下列表中选择一个网站: