燃油里程预测
这个例子展示了如何使用先前记录的观测数据来预测汽车的燃料消耗。
汽车每加仑行驶里程(MPG)的预测是一个典型的非线性回归问题,利用多种汽车特征来预测每加仑行驶里程(MPG)的油耗。本例的训练数据可在加州大学欧文分校(University of California, Irvine)获得机器学习库并且包含了从各种型号的汽车中收集的数据。
在这个数据集中,6个输入变量是汽缸数、排量、马力、重量、加速度和型号年。要预测的输出变量是MPG的油耗。在本例中,不使用数据集中的制造商和型号信息。
对数据进行分区
从原始数据文件中获取数据集autoGas.dat使用loadGasData函数。
[data,input_name] = loadGasData;
将数据集划分为一个训练集(奇数索引样本)和一个验证集(偶数索引样本)。
Trn_data = data(1:2:end,:);Val_data = data(2:2:end,:);
选择输入
使用exhaustiveSearch函数在可用输入中执行详尽搜索,以选择对燃油消耗影响最大的一组输入。使用的第一个参数exhaustiveSearch指定每个组合的输入数量(本例为1)。exhaustiveSearch为每个组合建立一个ANFIS模型,训练它一个时代,并报告所取得的性能。首先,使用exhaustiveSearch来确定哪个变量本身能最好地预测输出。
exhaustiveSearch (1 trn_data val_data input_name);
训练6个ANFIS模型,每个模型从6个候选模型中选择1个输入…型号1:气缸,误差:trn = 4.6400, val = 4.7255型号2:Disp,误差:trn = 4.3106, val = 4.4316型号3:功率,误差:trn = 4.5399, val = 4.1713型号4:重量,误差:trn = 4.2577, val = 4.0863型号5:加速器,误差:trn = 6.9789, val = 6.9317型号6:年,误差:trn = 6.2255, val = 6.1693
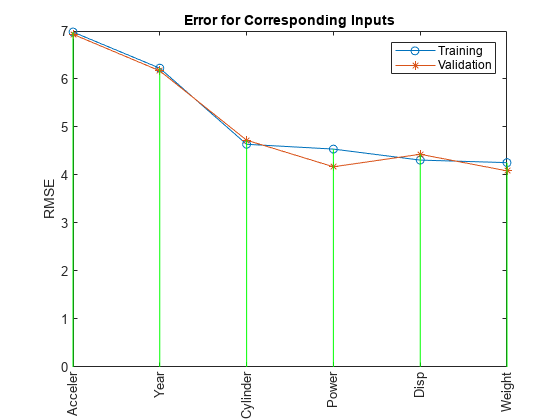
图表显示W八个变量的均方根误差最小。换句话说,它能最好地预测MPG。
为重量,训练误差和验证误差相当,表明过拟合很少。因此,您可以在ANFIS模型中使用多个输入变量。
虽然模型使用重量而且Disp各自的误差最小,这两个变量的组合不一定产生最小的训练误差。要确定两个输入变量的哪个组合产生的误差最小,请使用exhaustiveSearch搜索每一个组合。
input_index = expltivesearch (2,trn_data,val_data,input_name);
训练15个ANFIS模型,每个模型从6个候选模型中选择2个输入…简称ANFIS模型1:汽缸Disp,错误:trn = 3.9320, val = 4.7920简称ANFIS模型2:油缸,错误:trn = 3.7364, val = 4.8683简称ANFIS模型3:汽缸重量,错误:trn = 3.8741, val = 4.6762简称ANFIS模型4:气缸加速者,错误:trn = 4.3287, val = 5.9625简称ANFIS模型5:气缸,错误:trn = 3.7129, val = 4.5946简称ANFIS模型6:Disp权力,错误:trn = 3.8087, val = 3.8594简称ANFIS模型7:Disp重量,错误:trn = 4.0271, val = 4.6352简称ANFIS模型8:Disp加速者,错误:trn = 4.0782, val = 4.4890简称ANFIS模型9:Disp,错误:trn = 2.9565, val = 3.3905简称ANFIS模型10:功率重量,错误:trn = 3.9310, val = 4.2967简称ANFIS模型11:加速者,错误:trn = 4.2740, val = 3.8738简称ANFIS模型12:权力,错误:trn = 3.3796, val = 3.3505简称ANFIS模型13:体重加速者,错误:trn = 4.0875, val = 4.0094简称ANFIS模型14:重量,错误:trn = 2.7657, val = 2.9954简称ANFIS模型15:加速者,错误:trn = 5.6242, val = 5.6481
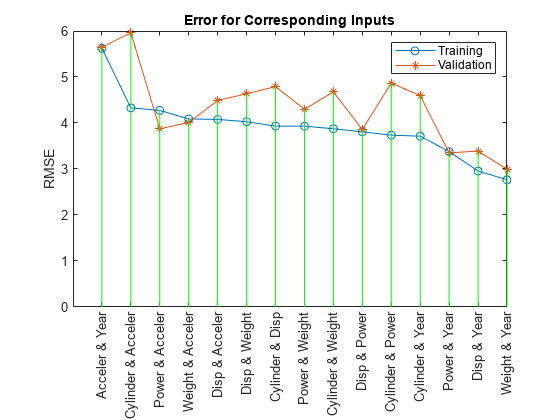
的结果exhaustiveSearch表明,重量而且一年形成两个输入变量的最优组合。然而,训练误差和验证误差之间的差异大于单独的任何一个变量之间的差异,这表明包含更多的变量会增加过拟合。运行exhaustiveSearch使用三个输入变量的组合来观察这些差异是否随着模型复杂性的增加而进一步增加。
exhaustiveSearch (3 trn_data val_data input_name);
训练20个ANFIS模型,每个模型从6个候选模型中选择3个输入…简称ANFIS模型1:汽缸Disp权力,错误:trn = 3.4446, val = 11.5329简称ANFIS模型2:汽缸Disp重量,错误:trn = 3.6686, val = 4.8926简称ANFIS模型3:缸Disp加速者,错误:trn = 3.6610, val = 5.2384简称ANFIS模型4:汽缸Disp,错误:trn = 2.5463, val = 4.9001简称ANFIS模型5:气缸功率重量,错误:trn = 3.4797, val = 9.3759简称ANFIS模型6:气缸加速者,错误:trn = 3.5432, val = 4.4804简称ANFIS模型7:气缸,错误:trn = 2.6300, val = 3.6300简称ANFIS模型8:汽缸体重加速者,错误:trn = 3.5708, val = 4.8379简称ANFIS模型9:汽缸重量,错误:trn = 2.4951, val = 4.0434简称ANFIS模型10:气缸加速者,错误:trn = 3.2698, val = 6.2616简称ANFIS模型11:Disp功率重量,错误:trn = 3.5879, val = 7.4951简称ANFIS模型12:Disp力量加速者,错误:trn = 3.5395, val = 3.9953简称ANFIS模型13:Disp权力,错误:trn = 2.4607, val = 3.3563简称ANFIS模型14:Disp体重加速者,错误:trn = 3.6075, val = 4.2323简称ANFIS模型15:Disp重量,错误:trn = 2.5617, val = 3.7858简称ANFIS模型16:Disp加速者,错误:trn = 2.4149, val = 3.2480简称ANFIS模型17:权力体重加速者,错误:trn = 3.7884, val = 4.0471简称ANFIS模型18:功率重量,错误:trn = 2.4371, val = 3.2830简称ANFIS模型19:力量加速者,错误:trn = 2.7276, val = 3.2580简称ANFIS模型20:体重加速者,错误:trn = 2.3603, val = 2.9152

该图显示了选择三个输入的结果。这里的组合重量,一年,加速者产生最低的训练误差。然而,训练和验证误差并不显著低于最佳双输入模型,这表明新添加的变量加速者并不能大大改善预测。由于更简单的模型通常推广效果更好,因此使用双输入ANFIS进行进一步的探索。
从原始训练和验证数据集中提取选定的输入变量。
New_trn_data = trn_data(:,[input_index, size(trn_data,2)]);New_val_data = val_data(:,[input_index, size(val_data,2)]);
训练ANFIS模型
这个函数exhaustiveSearch训练每个ANFIS只使用一个纪元,以便快速找到正确的输入。既然输入是固定的,您可以训练ANFIS模型更多的时代。
使用genfis函数从训练数据生成初始FIS,然后使用简称anfis微调它。
in_fis = genfis (new_trn_data (: 1: end-1), new_trn_data(:,结束));anfisOpt = anfisOptions(“InitialFIS”in_fis,“EpochNumber”, 100,...“StepSizeDecreaseRate”, 0.5,...“StepSizeIncreaseRate”, 1.5,...“ValidationData”new_val_data,...“DisplayANFISInformation”0,...“DisplayErrorValues”0,...“DisplayStepSize”0,...“DisplayFinalResults”, 0);[trn_out_fis, trn_error step_size、val_out_fis val_error] =...简称anfis (new_trn_data anfisOpt);
简称anfis返回训练和验证错误。在训练过程中绘制训练和验证误差。
[a,b] = min(val_error);trn_error情节(1:10 0,“g -”, val_error 1:10 0的r -, b,,“柯”)标题(“训练(绿色)和验证(红色)误差曲线”)包含(的数字时代) ylabel (“RMSE”)
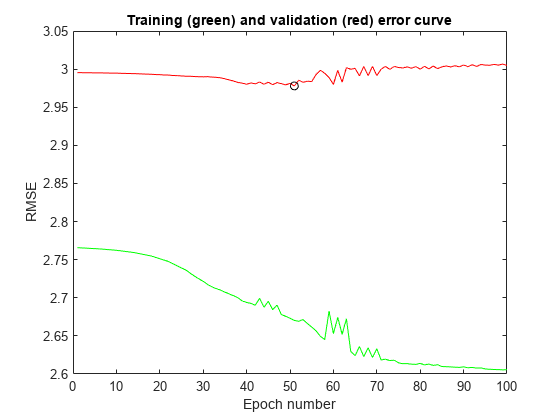
该图显示了ANFIS训练100期的误差曲线。绿色曲线表示训练误差,红色曲线表示验证误差。最小的验证误差发生在第45代左右,用圆圈表示。注意,验证误差曲线在50个周期后上升,表明进一步的训练过拟合数据,产生越来越差的泛化。
分析ANFIS模型
首先,使用各自的验证RMSE值比较ANFIS模型与线性模型的性能。
ANFIS预测可以通过将其各自的RMSE(均方根)值与验证数据进行比较,从而与线性回归模型进行比较。
执行线性回归N = size(trn_data,1);A = [trn_data(:,1:6) ones(N,1)];B = trn_data(:,7);cof = A\B;从训练数据中求解回归参数Nc = size(val_data,1);A_ck = [val_data(:,1:6) ones(Nc,1)];B_ck = val_data(:,7);lr_rmse = norm(A_ck* cof - b_ck)/sqrt(Nc);流(\nRMSE与验证数据\nANFIS: %1.3f\t线性回归:%1.3f\n',...一、lr_rmse);
对验证数据的均方根误差ANFIS: 2.978线性回归:3.444
ANFIS模型具有较低的验证RMSE,因此优于线性回归模型。
变量val_out_fis是训练过程中验证误差最小时ANFIS模型的快照。绘制模型的输出曲面。
val_out_fis.Inputs(1)。Name =“重量”;val_out_fis.Inputs(2)。Name =“年”;val_out_fis.Outputs(1)。Name =“英里”;gensurf (val_out_fis)
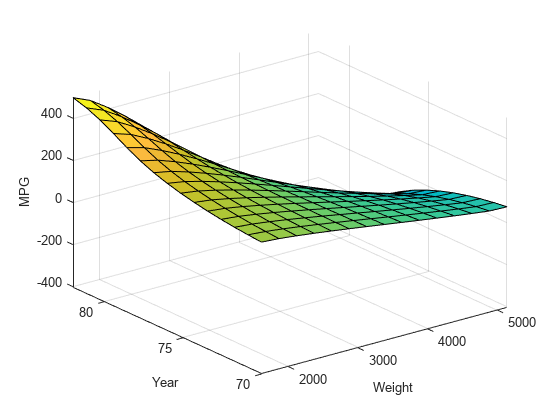
输出面是非线性和单调的,说明了ANFIS模型如何响应的变化值重量而且一年.
这个表面表明,对于1978年或以后生产的车辆,较重的汽车效率更高。绘制数据分布图,以查看输入数据中可能导致这种反直觉结果的任何潜在空白。
情节(new_trn_data (: 1) new_trn_data (:, 2),“波”,...new_val_data (: 1), new_val_data (:, 2),“处方”)包含(“重量”) ylabel (“年”)标题(“培训(o)和验证(x)数据”)
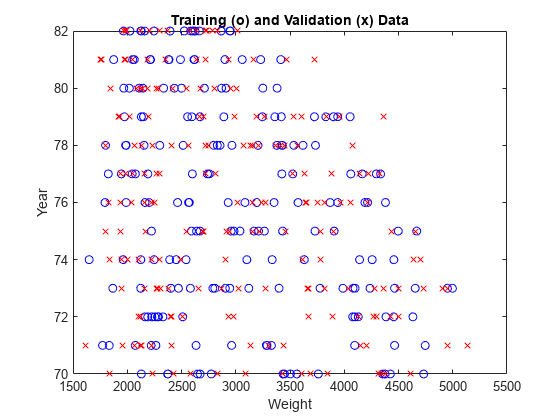
由于缺乏后期制造的重型车辆的训练数据,导致了反常的结果。由于数据分布严重影响预测精度,因此在解释ANFIS模型时要考虑数据分布。
另请参阅
相关的话题
您也可以从以下列表中选择网站: