预处理和探索加上时间戳数据使用时间表
这个例子展示了如何分析自行车交通模式从传感器数据使用时间表数据组织和预处理加上时间戳数据的容器。数据来自传感器在剑桥,在百老汇街。剑桥城提供了公共访问完整的数据集剑桥大学公开数据网站。
这个例子展示了如何执行各种数据清洗、绿豆、预处理等任务删除缺失值和同步带时间戳数据与不同的步伐。此外,数据探索包括可视化和分组计算使用突出显示时间表数据容器:
探索日常自行车交通
自行车交通当地天气状况进行比较
分析自行车交通在不同天的一天的星期和时间
自行车交通数据导入时间表
进口自行车交通的样本数据从一个逗号分隔的文本文件。的readtable函数返回一个表中的数据。显示使用前八行头函数。
bikeTbl = readtable (“BicycleCounts.csv”);头(bikeTbl)
时间戳天总西行的往东的___________________ _________________ _____替2015-06-24就是{“星期三”}13 9 4 2015-06-24 01:00:00{“星期三”}3 3 0 2015-06-24 02:00:00{“星期三”}1 1 0 2015-06-24 03:00:00{“星期三”}1 1 0 2015-06-24 04:00:00{“星期三”}1 1 0 2015-06-24 05:00:00{“星期三”}7 3 4 2015-06-24 06:00:00{“星期三”}36 6 30 2015-06-24 07:00:00{“星期三”}141 13 128
数据的时间戳,因此方便使用时间表来存储和分析数据。时间表是类似于一个表,但是包括时间戳与行相关联的数据。时间戳,或行乘以,表示datetime或持续时间值。datetime和持续时间推荐的数据类型代表点在时间或运行时间,分别。
转换bikeTbl成一个时间表使用table2timetable函数。你必须使用一个转换函数,因为readtable返回一个表。table2timetable将第一个datetime或持续时间表中变量的行乘以一个时间表。行乘以元数据标签的行。然而,当你显示一个时间表,行乘以和时间表变量显示在类似的方式。注意,桌上有五个变量而时间表有四个。
bikeData = table2timetable (bikeTbl);头(bikeData)
时间戳天总西行的往东的___________________ _________________ _____替2015-06-24就是{“星期三”}13 9 4 2015-06-24 01:00:00{“星期三”}3 3 0 2015-06-24 02:00:00{“星期三”}1 1 0 2015-06-24 03:00:00{“星期三”}1 1 0 2015-06-24 04:00:00{“星期三”}1 1 0 2015-06-24 05:00:00{“星期三”}7 3 4 2015-06-24 06:00:00{“星期三”}36 6 30 2015-06-24 07:00:00{“星期三”}141 13 128
谁bikeTblbikeData
类属性名称大小字节bikeData 9387 x4 1412425时间表bikeTbl 9387 x5 1487735表
访问时间和数据
转换一天变量来分类。范畴数据类型是专为数据由一组有限的离散值,如天的名字。所以他们的类别列表显示在订单。使用点加下标来访问变量的名字。
bikeData。一天= categorical(bikeData.Day,{“星期天”,“周一”,“星期二”,…“星期三”,“星期四”,“星期五”,“星期六”});
时间表,时间是分开处理的数据变量。访问属性时间表显示的行时间是第一维的时间表,和变量是第二个维度。的DimensionNames属性显示两个维度的名称,而VariableNames属性显示变量的名称,以及第二个维度。
bikeData.Properties
ans = TimetableProperties属性:描述:“用户数据:[]DimensionNames:{“时间戳”“变量”}VariableNames:{“天”“总”“西行”“往东的”}VariableDescriptions: {} VariableUnits: {} VariableContinuity: [] RowTimes: x1 datetime[9387]开始时间:2015-06-24就是SampleRate:南步伐:南事件:[]CustomProperties:没有自定义属性集。使用addprop和rmprop CustomProperties修改。
默认情况下,table2timetable分配时间戳作为第一个维度名称表转化成一个时间表,因为这是来自原始表变量名。你可以改变尺寸的名称,和其他时间表元数据,通过属性。
改变尺寸的名称时间和数据。
bikeData.Properties。DimensionNames = {“时间”“数据”};bikeData.Properties
ans = TimetableProperties属性:描述:“用户数据:[]DimensionNames:{‘时间’‘数据’}VariableNames:{“天”“总”“西行”“往东的”}VariableDescriptions: {} VariableUnits: {} VariableContinuity: [] RowTimes: x1 datetime[9387]开始时间:2015-06-24就是SampleRate:南步伐:南事件:[]CustomProperties:没有自定义属性集。使用addprop和rmprop CustomProperties修改。
显示的前八行时间表。
头(bikeData)
时间一天总西行的往东的___________________ _____ _____替2015-06-24就是星期三13 9 4 2015-06-24 01:00:00周三3 3 0 2015-06-24 02:00:00周三1 1 0 2015-06-24 03:00:00周三1 1 0 2015-06-24 04:00:00周三1 1 0 2015-06-24 05:00:00周三7 3 4 2015-06-24 06:00:00周三36 6 141 2015-06-24周三07:00:00 13 128人
确定的天数之间运行最新的最早、行乘以。变量可以被点符号引用变量时访问一次。
elapsedTime = max (bikeData.Time) - min (bikeData.Time)
elapsedTime =持续时间9383:30:00
elapsedTime。格式=' d '
elapsedTime =持续时间390.98天
检查典型的自行车数量在给定的一天,计算方法的总数自行车,和数字西行和东边的旅行。
返回一个矩阵的数值数据索引的内容bikeData使用花括号。前八行显示。使用标准表加下标来访问多个变量。
数量= bikeData{: 2:结束};计数(1:8,:)
ans =8×313 9 4 3 3 0 1 1 0 1 1 0 1 1 0 7 3 4 36 6 30 141 13 128
自的意思是只适合数值数据,您可以使用vartype函数选择数值变量。vartype更方便比手动选择变量索引表或时间表。计算方法和省略南值。
数量= bikeData {: vartype (“数字”)};意思是(计数,“omitnan”)
ans =1×349.8860 24.2002 25.6857
选择数据的日期和时间
确定有多少人自行车度假期间,检查数据7月4日假期。索引的时间表行时间7月4日,2015年。索引行乘以时,您必须匹配时间。你可以指定时间指数datetime或持续时间值,或作为特征向量,可以转换为日期和时间。你可以多次指定为一个数组。
索引bikeData与特定的日期和时间为7月4日提取数据,2015。如果您指定的日期,然后被认为是午夜的时候,或者就是。
bikeData (“2015-07-04”:)
ans =1×4时间表时间一天总西行的往东的___________________ ________替2015-07-04就是周六8 7 1 _____
d = {“2015-07-04 08:00:00”,“2015-07-04 09:00:00”};bikeData (d,:)
ans =2×4时间表时间一天总西行的往东的___________________ ________ _____替2015-07-04 08:00:00周六15 3 12 2015-07-04 09:00:00周六21 4 17
这将是乏味的使用这一策略提取一整天。您还可以指定范围的时间没有索引在特定时间。创建一个时间范围下标作为辅助,使用timerange函数。
下标的时间表使用时间范围为整个7月4日,2015年。指定开始时间为7月4日午夜,结束时间为7月5日午夜。默认情况下,timerange涵盖了所有时间从开始时间和,但不包括结束时间。情节自行车数量的一天。
tr = timerange (“2015-07-04”,“2015-07-05”);jul4 = bikeData (tr,“总”);头(jul4)
时间总___________________ _____ 2015-07-04就是8 2015-07-04 01:00:00 13 2015-07-04 02:00:00 4 2015-07-04 03:00:00 1 2015-07-04 0 2015-07-04 05:00:00 1 04:00:00 2015-07-04 06:00:00 8 2015-07-04 07:00:00 16
酒吧(jul4.Time jul4.Total) ylabel (的自行车数量)标题(“自行车数量在2015年7月4日”)
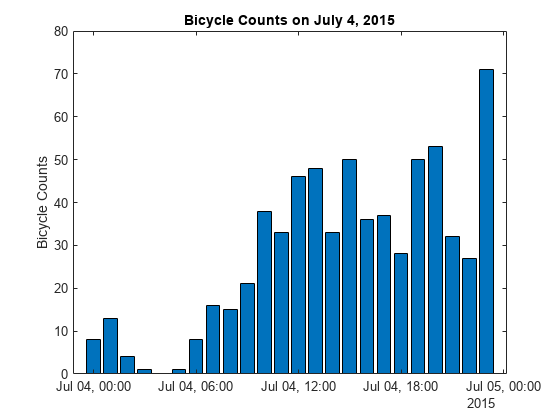
从情节,体积整整一天,下午趋于稳定。因为许多企业关闭,情节不显示典型的交通在上下班时间。峰值后晚上可以归因于庆典烟花,天黑后发生的。仔细研究这些趋势,数据应该比典型的天。
比较数据,7月4日7月的数据。
7月= bikeData (timerange (“2015-07-01”,“2015-08-01”):);情节(jul.Time jul.Total)在情节(jul4.Time jul4.Total) ylabel (“总数”)标题(7月份的自行车数量的)举行从传奇(“自行车数”,“7月4日自行车数”)
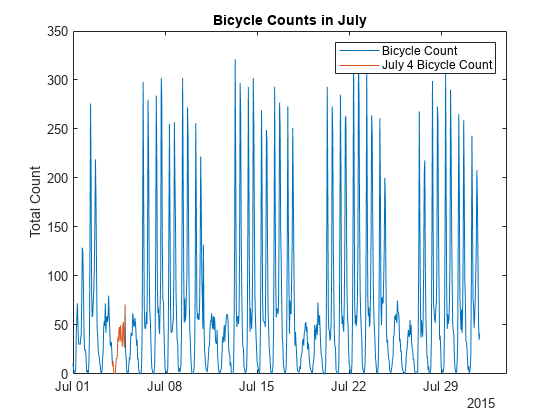
情节变化表明,可以归因于交通差异工作日和周末。7月4和5的交通模式是符合周末交通的模式。7月5日是星期一,但经常被观察到的是度假。这些趋势可以进一步检查更紧密地与预处理和分析。
预处理时间和数据使用时间表
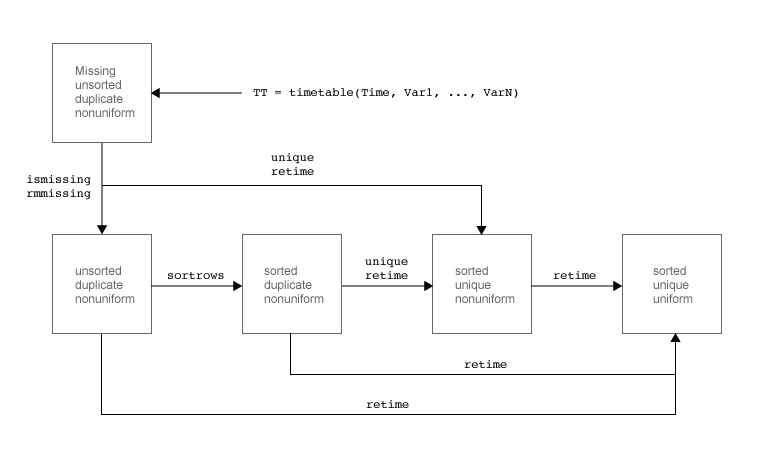
带时间戳数据集往往是混乱和可能包含异常或错误。时间表非常适合解决异常和错误。
时间表不必行乘以在任何特定的顺序。它可以包含行不按他们的行乘以。时间表也可以包含多个行相同的行,尽管行可以有不同的数据值。即使行乘以排序和独特的,他们可以通过时间不同大小不同的步骤。甚至可以包含一个时间表NaT或南值表示缺失行乘以。
的时间表数据类型提供了许多不同的方法来解决失踪,复制,或非均匀。你也可以重新取样或聚合数据创建一个常规的时间表。常规时间表时,行乘以排序和独特的,和有一个统一的或均匀间隔的时间步。
寻找失踪的行次,使用
ismissing。删除丢失的时间和数据,使用
rmmissing。由行乘以一个时间表,使用
sortrows。做一个时间表和独特的行乘以排序,使用
独特的和调整时间。常规的时间表,指定一个均匀间隔的时间向量和使用
调整时间。
按时间顺序排序
确定的时间表进行排序。时间表是排序如果行乘以按升序列出。
issorted (bikeData)
ans =逻辑0
的时间表。的sortrows函数的行次,从最早的最新时间。如果有行用重复的行次,然后sortrows所有的副本复制到输出。
bikeData = sortrows (bikeData);issorted (bikeData)
ans =逻辑1
识别和删除丢失的时间和数据
一个时间表可以有缺失的数据指标变量或行乘以。例如,您可以显示缺失的数值南年代,失踪的datetime值NaT年代。你可以分配,查找、删除和缺失值填充standardizeMissing,ismissing,rmmissing,fillmissing函数,分别。
找到并计数丢失的时间表变量中的值。在这个例子中,缺失值显示情况下没有数据收集。
missData = ismissing (bikeData);总和(missData)
ans =1×41 3 3 3
的输出ismissing是一个逻辑矩阵,相同的尺寸表,确定丢失的数据值是真实的。显示任何行已缺失的数据指标。
idx = (missData, 2);bikeData (idx:)
ans =3×4时间表时间一天总西行的往东的___________________ ___________ _____替2015-08-03就是周一南南南南南南2015-08-03 01:00:00 NaT <定义>南南南
ismissing (bikeData)发现缺失数据的时间表变量,不是《纽约时报》。寻找失踪的行次,电话ismissing行乘以。
missTimes = ismissing (bikeData.Time);bikeData (missTimes:)
ans =2×4时间表时间一天总西行的往东的告诉⒈替NaT <定义>南南南NaT周五6 3 3
在这个例子中,失踪的时间或数据值显示测量错误,可以排除。删除表的行包含缺失的数据值和失踪行乘以使用rmmissing。
bikeData = rmmissing (bikeData);sum (ismissing (bikeData))
ans =1×40 0 0 0
sum (ismissing (bikeData.Time))
ans = 0
删除重复的时间和数据
确定是否有重复的时间和/或重复的行数据。您可能想要排除精确复制,因为这些也可以被认为是测量错误。识别重复次发现,排序时间之间的差异就是零。
idx = diff (bikeData.Time) = = 0;dup = bikeData.Time (idx)
dup =3 x1 datetime2015-08-21就是2015-08-21 23:00:00 2015-08-21 23:00:00
2015年三次重复和11月19日,重复两次。检查相关的数据重复。
bikeData (dup (1):)
ans =2×4时间表时间一天总西行的往东的___________________ _____ _____替2015-08-21就是周五14 9 5 2015-08-21就是星期五11 7 4
bikeData (dup (2):)
ans =3×4时间表时间一天总西行的往东的___________________ ________ _____替2015-11-19 23:00:00周四17 15 2 2015-11-19 23:00:00周四17 15 2 2015-11-19 23:00:00周四17 15 2
第一个复制倍但non-duplicate数据,而其他人是完全复制。时间表的行被认为是重复的,当它们包含相同的行乘以和相同的数据值的行。您可以使用独特的删除重复的行时间表。的独特的函数还行乘以类型的行。
bikeData =独特(bikeData);
重复的行次但non-duplicate数据需要一些解释。检查数据。
d = dup(1) +小时(2:2);bikeData (d,:)
ans =5×4时间表时间一天总西行的往东的___________________ ________ _____替2015-08-20周四22:00:00 40 30 10 2015-08-20 23:00:00周四25 18 7 2015-08-21就是星期五11 7 4 2015-08-21就是周五14 9 5 2015-08-21 02:00:00周五6 5 1
在这种情况下,重复的时间以来可能是错误的数据和周围的时间是一致的。虽然它似乎代表01:00:00,这还不确定什么时间应该是。积累的数据可以考虑到在两个时间点的数据。
sum (bikeData {dup (1), 2:})
ans =1×325 16 9
这只是一个案例中,可以手动完成的。然而,对于许多行,调整时间函数可以执行此计算。积累的数据使用独特的倍总和聚合函数。和适合数值数据而不是分类数据的时间表。使用vartype确定数值变量。
vt = vartype (“数字”);t =独特(bikeData.Time);numData =调整时间(bikeData (:, vt), t,“和”);头(numData)
时间总西行的往东的___________________ _____替2015-06-24就是13 9 4 2015-06-24 01:00:00 3 3 0 2015-06-24 02:00:00 1 1 0 2015-06-24 03:00:00 1 1 0 2015-06-24 04:00:00 1 1 0 2015-06-24 05:00:00 7 3 4 2015-06-24 06:00:00 36 6 141 2015-06-24 07:00:00 13 128人
你不能和分类数据,但由于一个品牌代表了一整天,每天带第一个值。你可以执行调整时间操作的时间向量和连接一起的时间表。
vc = vartype (“分类”);catData =调整时间(bikeData (:, vc), t,“firstvalue”);bikeData = [catData, numData];bikeData (d,:)
ans =4×4的时间表时间一天总西行的往东的___________________ ________ _____替2015-08-20周四22:00:00 40 30 10 2015-08-20 23:00:00周四25 18 7 2015-08-21就是周五25 16 9 2015-08-21 02:00:00周五6 5 1
检查时间间隔的均匀性
数据似乎有一个统一的时间步的一小时。确定这是适用于所有的行乘以时间表,使用isregular函数。isregular返回真正的排序、等间隔时间(单调递增),没有重复或丢失(NaT或南)。
isregular (bikeData)
ans =逻辑0
的输出0,或假,表明次时间表不是均匀间隔的。更详细地探索的时间间隔。
dt = diff (bikeData.Time);[min (dt);马克斯(dt)]
ans =2 x1持续时间00:30:00 03:00:00
把时间表在常规时间间隔,使用调整时间或同步并指定感兴趣的时间间隔。
确定每天自行车体积
确定每天使用调整时间函数。每天使用的计数数据积累总和方法。这是适合数字数据而不是分类数据的时间表。使用vartype确定变量的数据类型。
dayCountNum =调整时间(bikeData (:, vt),“每天”,“和”);头(dayCountNum)
时间总西行的往东的___________________ _____替2015-06-24就是2141 1141 1000 2015-06-24就是2106 1123 983 2015-06-26就是1748 970 778 2015-06-26就是695 346 349 2015-06-28就是153 83 70 2015-06-28就是1841 978 863 2015-06-30就是2170 1145 1025 2015-06-30就是997 544 453
如上所述,您可以执行调整时间操作又代表分类数据使用一个适当的方法,将时间表连接在一起。
dayCountCat =调整时间(bikeData (:, vc),“每天”,“firstvalue”);dayCount = [dayCountCat, dayCountNum];头(dayCount)
时间一天总西行的往东的___________________ _____ _____替2015-06-24就是周三周四2106 1123 983 2141 1141 1000 2015-06-25就是2015-06-26就是周五周六695 346 349 1748 970 778 2015-06-27就是2015-06-28就是周日周一1841 978 863 153 83 70 2015-06-29就是2015-06-30就是周二周三997 544 453 2170 1145 1025 2015-07-01就是
自行车计数和天气数据同步
检查的影响天气骑自行车的行为与天气数据通过比较自行车计数。加载天气时间表,其中包括历史气象数据来自波士顿,MA,包括风暴事件。
负载BostonWeatherData头(weatherData)
时间TemperatureF湿度事件___________ _______ ________ _______ 01 - 72年7月- 2015年78雷暴02 - 72年7月- 2015年60没有03 - 70年7月- 2015年56没有04—05 75没有67年7月- 2015 - 7 - 2015 72 67没有06 - 69没有74年7月- 2015年07 - 77雨08年75年7月- 2015年7月——2015 79 68下雨
总结《纽约时报》在时间表和变量,使用总结函数。
总结(weatherData)
x1 datetime值:RowTimes:时间:383分钟01 - 2015中位数08年7月- 2016年1月2016 Max 17 - 7月步伐24:00:00变量:TemperatureF: x1双重价值:383分钟2 55 Max 85湿度中位数:383 x1双重价值:分钟29 64 Max 97事件中位数:383 x1分类值:7冰雹雨108雨雪雾4雪18雷暴12没有233
把自行车数据和天气数据使用一个共同的时间向量同步。你可以重新取样或总时间表数据使用任何方法记录参考页面同步函数。
从两个时间表同步数据向量,一个共同的时间由个人日常时间的交集向量。
data =同步(dayCount weatherData,“十字路口”);头(数据)
时间一天总西行的往东的TemperatureF湿度事件___________________ _____ _____替_______ ________ _______ 2015-07-01就是周三997 544 453 72 78雷暴2015-07-02就是周四60 1943 1033 910 72 2015-07-03就是没有一个周五870 454 416 70 56 2015-07-04就是没有周六周日669 328 341 67 75 2015-07-05就是没有一个702 407 295 72 67 2015-07-06就是没有一个星期一1900 1029 871 74 69 2015-07-07就是没有一个星期二星期三雨2106 1140 966 75 77 2015-07-08就是1855 984 871 79 68下雨
比较自行车交通计数和室外温度在不同的y轴检查的趋势。把周末从可视化的数据。
idx = ~ isweekend (data.Time);weekdayData =数据(idx, {“TemperatureF”,“总”});图yyaxis左情节(weekdayData。时间,weekdayData.Total) ylabel(“自行车数”)yyaxis正确的情节(weekdayData.Time weekdayData.TemperatureF) ylabel (“温度(\保监会F)”)标题(的自行车数量和温度随时间的推移)xlim((最小(data.Time)最大(data.Time)))
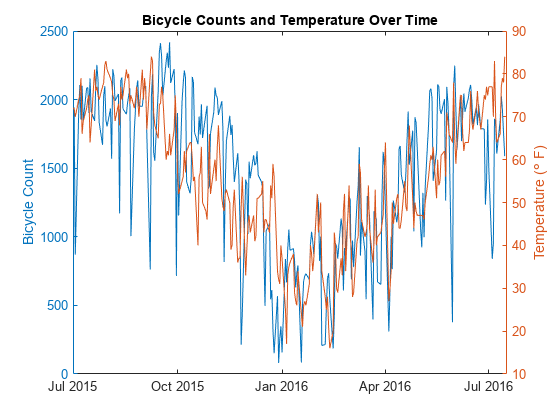
情节表明交通和天气数据可能遵循类似的趋势。放大的阴谋。
xlim ([datetime (“2015-11-01”)、日期时间(“2016-05-01”)))
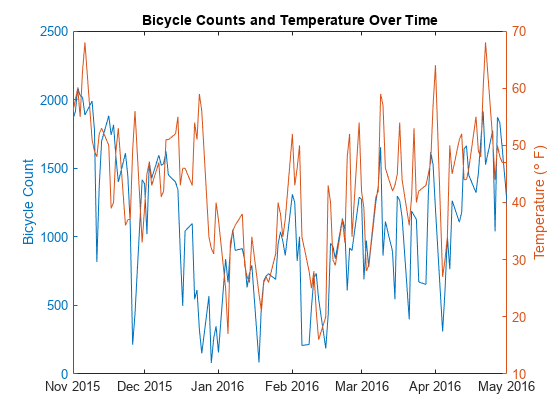
的趋势是相似的,这表明更少的人在寒冷的日子里循环。
分析,每周和每天的时间
检查数据根据不同的间隔,如星期和时间。确定总数量每天使用varfun对变量进行分组计算。指定总和函数与函数处理分组变量和优先使用名称-值对输出类型。
byDay = varfun (@sum bikeData,“GroupingVariables”,“天”,…“OutputFormat”,“表”)
byDay =7×5表天GroupCount sum_Total sum_Westbound sum_Eastbound _____ _____ _____ _________________ _________________周日周一1344 25315 12471 12844 1343 79991 39219 40772周二周四周三1320 81480 39695 41785 1344 86853 41726 45127 1344 87516 42682 44834周五周六1342 76643 36926 39717 1343 30292 14343 15949
图酒吧(byDay {: {“sum_Westbound”,“sum_Eastbound”}})传说({“西行”,“往东的”},“位置”,“eastoutside”)xticklabels ({“太阳”,“我的”,“星期二”,“结婚”,“星期四”,“星期五”,“坐”})标题(“自行车数天的星期”)
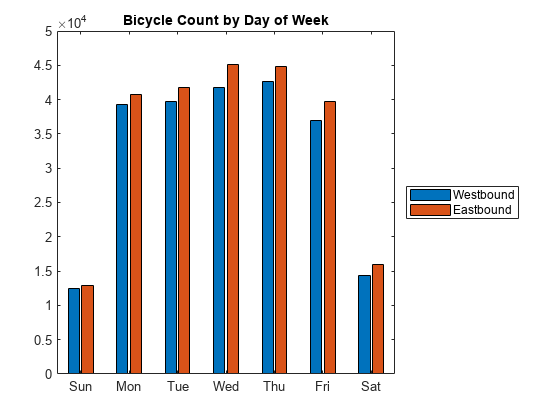
酒吧情节表明在工作日交通更拥堵。同时,有一个往东的差异,西行的方向。这可能表明,人们倾向于采取不同的路线进入和离开这个城市的时候。一种可能性是,某些人进入一天,另一天再回来。
决定一天的小时和使用varfun为计算组。
bikeData。HrOfDay =小时(bikeData.Time);byHr = varfun (@mean bikeData (: {“西行”,“往东的”,“HrOfDay”}),…“GroupingVariables”,“HrOfDay”,“OutputFormat”,“表”);头(byHr)
除了___ ____ HrOfDay GroupCount mean_Westbound mean_Eastbound __________ * * * 0 389 5.4396 1.7686 2.7712 389 0.87147 391 1.8696 0.58312 0.7468 391 0.289 391 0.52685 1.0026 391 391 0.70588 4.7494 3.1228 63.54 22.097 391 9.1176
栏(byHr {: {“mean_Westbound”,“mean_Eastbound”}})传说(“西行”,“往东的”,“位置”,“eastoutside”)包含(一天的小时)ylabel (“自行车数”)标题(的意思是自行车的小时数天)
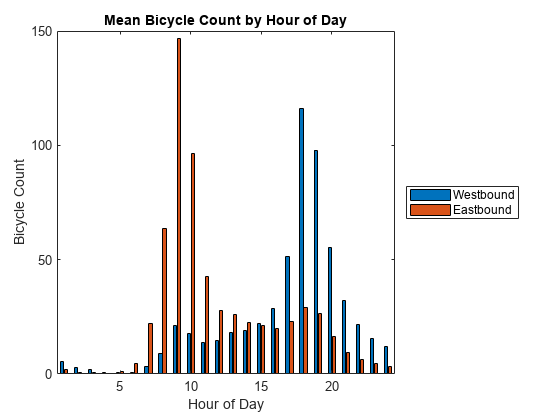
有流量峰值,在典型的通勤时间,上午9点左右和下午5点。同时,往东的之间的趋势和西行方向是不同的。一般来说,西行的方向是对剑桥地区周围的居民区和大学。往东的方向是向波士顿。
重交通当天晚些时候在西行方向比往东的方向。这可能表明大学时间表和交通由于餐馆。检查一周的趋势,以及小时的一天。
byHrDay = varfun (@sum bikeData,“GroupingVariables”,{“HrOfDay”,“天”},…“OutputFormat”,“表”);头(byHrDay)
HrOfDay天GroupCount sum_Total sum_Westbound sum_Eastbound _____ _____ _____ _________________ _________________周日56 473 345 128 0周一57 55 202 145 0周二周三55 297 213 84 0 56周四56 436 324 112 374 286 88 0 0 56周五55 442 348 94 0周六周日56 333 259 74 580 455 125 1
安排本周的时间表,这样的日子是变量,使用unstack函数。
hrAndDayWeek = unstack (byHrDay (: {“HrOfDay”,“天”,“sum_Total”}),“sum_Total”,“天”);头(hrAndDayWeek)
HrOfDay周日周一周二周三周四周五周六累积交_____ ________ ________ ________ 0 473 202 297 374 436 442 580 333 81 147 168 173 183 332 86 198 77 68 93 128 141 254 3 51 41 43 44 50 61 80 81 117 101 108 80 60 419 105 353 407 381 340 128 275 1750 1867 2066 1927 1625 351 5818 553 5355 5515 5731 4733 704
丝带(hrAndDayWeek.HrOfDay hrAndDayWeek{: 2:结束})ylim([0] 24日)xlim ([0 8]) xticks (1:7) xticklabels ({“太阳”,“我的”,“星期二”,“结婚”,“星期四”,“星期五”,“坐”})ylabel (“小时”)标题(的自行车数小时和天一周的)
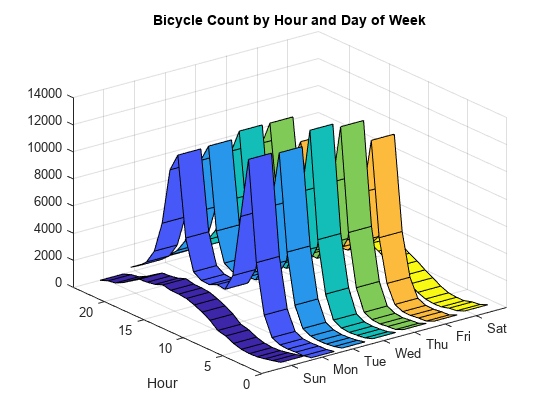
也有类似的趋势经常周一到周五的工作日,交通高峰期的山峰和逐步减少在晚上。周五体积不大,但总体趋势是类似于其他工作天。周六和周日的趋势相似,没有高峰的峰值和更多的体积在当天晚些时候。晚上趋势也类似的周一到周五,周五体积较小。
分析交通高峰时间
检查整个时间趋势,分手高峰期倍的数据。可以使用一天中不同时段或使用单位的时间离散化函数。例如,把数据分成组我,AMRush,一天,PMRush,点。然后使用varfun计算的意思。
bikeData。HrLabel =离散化(bikeData.HrOfDay, [0、6、10、15、19、24),“分类”,…{“我”,“RushAM”,“天”,“RushPM”,“点”});byHrBin = varfun (@mean bikeData (: {“总”,“HrLabel”}),“GroupingVariables”,“HrLabel”,…“OutputFormat”,“表”)
byHrBin =5×3表HrLabel GroupCount mean_Total __________ _____我2342天3.5508 RushAM 1564 94.893 1955 45.612 RushPM 1564 98.066 1955 35.198点
酒吧(byHrBin.mean_Total)猫=类别(byHrBin.HrLabel);xticklabels(猫)标题(“高峰时期意味着自行车数”)
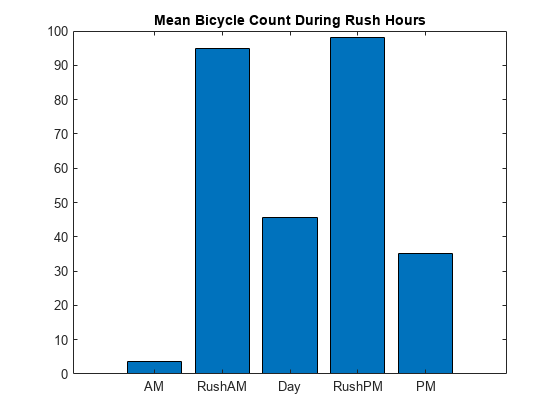
一般来说,在这一领域有两倍多的交通高峰在晚上和早晨比一天的其他时间。这个地区很少有交通清晨,但仍有巨大的流量在傍晚和晚上,与外面的天早晚高峰。
另请参阅
时间表|table2timetable|头|总结|varfun|timerange|sortrows|rmmissing|调整时间|datetime|unstack