火车DDPG剂来控制飞行机器人
这个例子展示了如何训练深决定性策略梯度(DDPG)代理生成轨迹的飞行机器人建模仿真软件®。万博1manbetxDDPG代理的更多信息,请参阅深决定性策略梯度(DDPG)代理。
飞行机器人模型
这个例子的强化学习环境是一个飞行机器人的初始条件随机环周围半径15米。机器人的定位也是随机的。机器人有两个推进器安装在身体的一侧,用于推动和引导机器人。培训目标是驱动的机器人原点朝东的初始条件。
打开模型。
mdl =“rlFlyingRobotEnv”;open_system (mdl)
设置初始状态变量模型。
theta0 = 0;x0 = -15;y0 = 0;
定义样本的时间Ts和仿真时间特遣部队。
t = 0.4;Tf = 30;
对于这个模型:
我们的目标取向是
0rad(机器人朝东)。每个执行器的推力是有界的从1到1 N
来自环境的观测位置,方向定位(正弦和余弦),速度,角速度的机器人。
奖励 在每一个时间步是提供
地点:
是沿着x轴机器人的位置。
沿y轴机器人的位置。
是机器人的姿态。
从左边的推进器控制工作。
从正确的推进器控制工作。
是奖励当机器人是接近我们的目标。
是惩罚当机器人驱动器超过20 m x或y方向。模拟时终止 。
QR惩罚,惩罚的距离目标和控制工作。
创建集成模型
培训的代理FlyingRobotEnv模型,使用createIntegratedEnv函数自动生成仿真软件模型包含一个RL代理块,准备培训。万博1manbetx
integratedMdl =“IntegratedFlyingRobot”;[~,agentBlk obsInfo actInfo] =…createIntegratedEnv (mdl integratedMdl);
操作和观察
创建环境对象之前,为观察和操作规范,指定名称和绑定1之间的推力的行动和1。
这种环境的观测向量 。环境观测通道分配一个名称。
obsInfo。Name =“观察”;
这个环境是动作向量 。指定一个名称,以及上、下极限,对环境行动通道。
actInfo。Name =“手臂”;actInfo。lowerLimit = -ones(prod(actInfo.Dimension),1); actInfo.UpperLimit = ones(prod(actInfo.Dimension),1);
请注意,刺激(obsInfo.Dimension)和刺激(actInfo.Dimension)返回的数量的维度观察和行动空间,分别不管他们是否安排行向量,列向量或矩阵。
创建环境对象
创建一个环境对象使用集成的仿真软件模型。万博1manbetx
env = rl万博1manbetxSimulinkEnv (…integratedMdl,…agentBlk,…obsInfo,…actInfo);
重置功能
创建一个定制的复位函数,随机排列机器人的初始位置沿环半径15米和初始取向。重置功能的详细信息,请参见flyingRobotResetFcn。
env。ResetFcn = @(in) flyingRobotResetFcn(in);
解决随机发生器再现性的种子。
rng (0)
创建DDPG代理
DDPG代理使用参数化核反应能量函数近似者估计价值的政策。核反应能量函数批评家接受当前的观察和行动作为输入并返回一个标量输出(估计折扣累积长期奖励给状态对应于当前的行为观察,和后政策之后)。
模型中的参数化核反应能量函数评论家,使用神经网络和两个输入层(一个用于观测通道,所指定的obsInfo,行动的其他渠道,指定的actInfo)和一个输出层(返回标量值)。
定义每个网络路径层对象数组。将名称分配给每条路径的输入和输出层。这些名字让你连接路径,然后明确关联网络的输入和输出通道层与适当的环境。
%为隐藏层指定输出的数量。hiddenLayerSize = 100;%定义观察路径层observationPath = [featureInputLayer (…刺激(obsInfo.Dimension),名称=“obsInLyr”)fullyConnectedLayer (hiddenLayerSize) reluLayer fullyConnectedLayer hiddenLayerSize additionLayer (Name =“添加”)reluLayer fullyConnectedLayer (hiddenLayerSize) reluLayer fullyConnectedLayer (Name =“fc4”));%定义行动路径层actionPath = [featureInputLayer (…刺激(actInfo.Dimension),…Name =“actInLyr”)fullyConnectedLayer (hiddenLayerSize Name =“fc5”));%创建层图。criticNetwork = layerGraph (observationPath);criticNetwork = addLayers (criticNetwork actionPath);%连接actionPath observationPath。criticNetwork = connectLayers (criticNetwork,“fc5”,“添加/ in2”);%创建dlnetwork层图criticNetwork = dlnetwork (criticNetwork);%显示参数的数量总结(criticNetwork)
初始化:可学的真正的数量:21.4 k输入:1“obsInLyr”7功能2“actInLyr”功能
创建一个评论家使用criticNetwork、环境的规范和网络输入层的名称连接到观察和行动通道。更多信息见rlQValueFunction。
评论家= rlQValueFunction (criticNetwork obsInfo actInfo,…ObservationInputNames =“obsInLyr”ActionInputNames =“actInLyr”);
DDPG代理使用参数化确定性政策连续动作空间,由一个连续的学习确定的演员。这个演员需要当前观测作为输入并返回输出一个观察的行动是一个确定性的函数。
模型中的参数化政策的演员,使用一个输入神经网络层(接收环境观察频道的内容,规定obsInfo)和一个输出层(返回行动对环境行动通道,是指定的actInfo)。
层的网络定义为一个数组对象。
actorNetwork = [featureInputLayer (prod (obsInfo.Dimension)) fullyConnectedLayer (hiddenLayerSize) reluLayer fullyConnectedLayer (hiddenLayerSize) reluLayer fullyConnectedLayer (hiddenLayerSize) reluLayer fullyConnectedLayer(刺激(actInfo.Dimension)) tanhLayer];
转换层对象的数组dlnetwork对象和显示参数的数量。
actorNetwork = dlnetwork (actorNetwork);总结(actorNetwork)
初始化:真很多可学的:21.2 k输入:1“输入”7功能
定义演员使用actorNetwork,规范操作和观察通道。有关更多信息,请参见rlContinuousDeterministicActor。
演员= rlContinuousDeterministicActor (actorNetwork obsInfo actInfo);
使用指定选项的评论家和演员rlOptimizerOptions。
criticOptions = rlOptimizerOptions (LearnRate = 1 e 03, GradientThreshold = 1);actorOptions = rlOptimizerOptions (LearnRate = 1 e-04, GradientThreshold = 1);
使用指定DDPG代理选项rlDDPGAgentOptions的训练选项,包括演员和评论家。
agentOptions = rlDDPGAgentOptions (…SampleTime = Ts,…ActorOptimizerOptions = actorOptions,…CriticOptimizerOptions = criticOptions,…ExperienceBufferLength = 1 e6,…MiniBatchSize = 256);agentOptions.NoiseOptions。方差= 1 e 1;agentOptions.NoiseOptions。VarianceDecayRate = 1 e-6;
然后,创建代理使用演员,评论家和代理选项。有关更多信息,请参见rlDDPGAgent。
代理= rlDDPGAgent(演员、评论家、agentOptions);
或者,您可以创建代理,然后访问其选择对象和修改选项使用点符号。
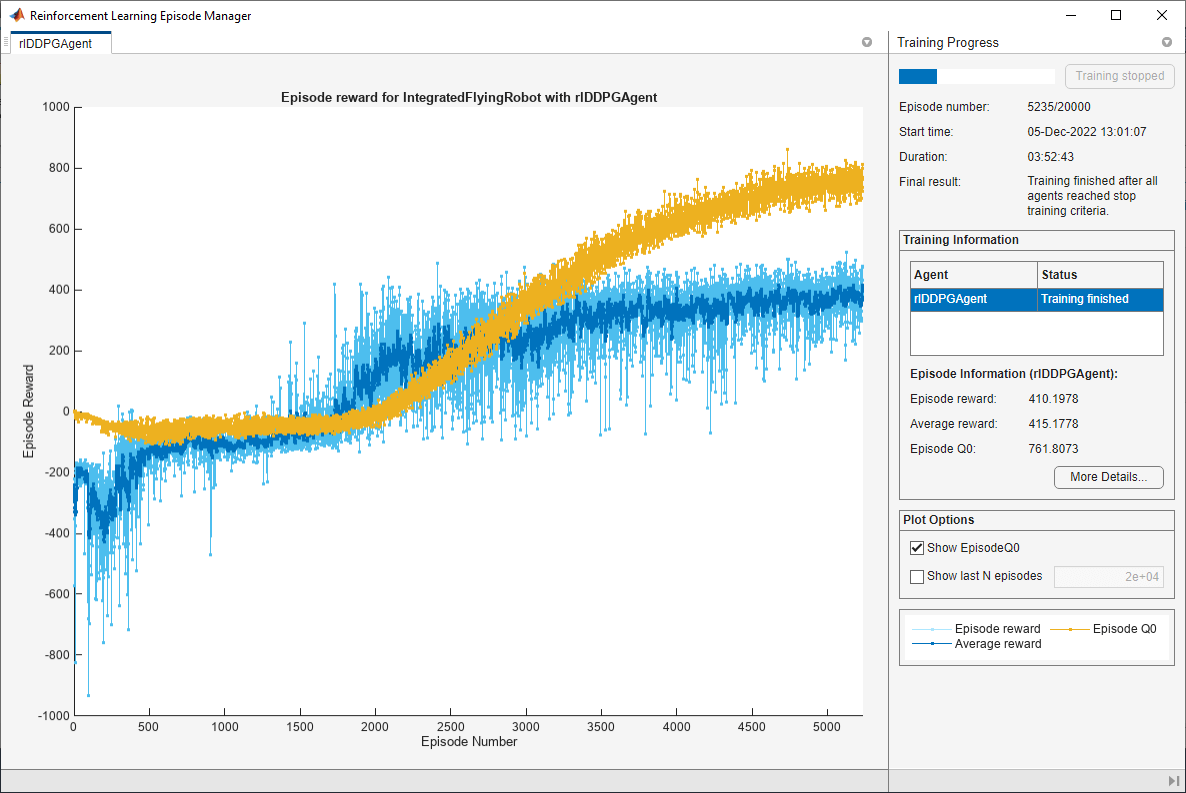
火车代理
培训代理商,首先指定培训选项。对于这个示例,使用以下选项:
运行每个培训
20000年集,每集持久的最多装天花板(Tf / Ts)时间的步骤。在事件管理器对话框显示培训进展(设置
情节在命令行选项)和禁用显示(设置详细的选项假)。停止训练当代理接收到平均累积奖励大于
415年连续超过10集。此时,代理可以驱动飞行机器人的目标位置。保存一份代理累积奖励大于每一集
415年。
有关更多信息,请参见rlTrainingOptions。
maxepisodes = 20000;maxsteps =装天花板(Tf / Ts);trainingOptions = rlTrainingOptions (…MaxEpisodes = MaxEpisodes,…MaxStepsPerEpisode = maxsteps,…StopOnError =“上”,…Verbose = false,…情节=“训练进步”,…StopTrainingCriteria =“AverageReward”,…StopTrainingValue = 415,…ScoreAveragingWindowLength = 10,…SaveAgentCriteria =“EpisodeReward”,…SaveAgentValue = 415);
火车代理使用火车函数。培训是一个计算密集型的过程需要几个小时才能完成。节省时间在运行这个例子中,加载一个pretrained代理设置doTraining来假。训练自己代理,集doTraining来真正的。
doTraining = false;如果doTraining%培训代理。trainingStats =火车(代理,env, trainingOptions);其他的%加载pretrained代理的例子。负载(“FlyingRobotDDPG.mat”,“代理”)结束
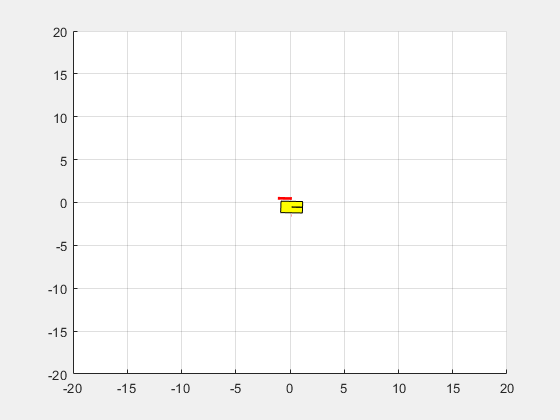
模拟DDPG代理
验证培训代理的性能,模拟环境中的代理。代理模拟更多的信息,请参阅rlSimulationOptions和sim卡。
simOptions = rlSimulationOptions (MaxSteps = MaxSteps);经验= sim (env,代理,simOptions);
另请参阅
功能
对象
rlDDPGAgent|rlDDPGAgentOptions|rlQValueFunction|rlContinuousDeterministicActor|rlTrainingOptions|rlSimulationOptions|rlOptimizerOptions