不平衡数据分类
这个例子展示了当一个类的观察值比另一个类多很多时如何执行分类。你可以使用RUSBoost首先是算法,因为它就是用来处理这种情况的。处理不平衡数据的另一种方法是使用名称-值对参数“之前”或“成本”.详细信息请参见处理分类集合中的不平衡数据或不平等错误分类代价.
此示例使用来自UCI机器学习存档的“封面类型”数据,在https://archive.ics.uci.edu/ml/datasets/Covertype.这些数据根据海拔、土壤类型和到水的距离等预测因素对森林类型(地面覆盖)进行了分类。数据有超过500,000个观测值和超过50个预测因子,因此训练和使用分类器是耗时的。
布莱克德和迪恩[1]描述对这些数据的神经网络分类。他们引用了70.6%的分类准确率。RUSBoost获得81%以上的分类准确率。
获取数据
将数据导入您的工作区。将最后一个数据列提取到名为Y.
gunzip (“https://archive.ics.uci.edu/ml/machine-learning-databases/covtype/covtype.data.gz”)加载covtype.dataY = covtype(:,end);Covtype (:,end) = [];
检查响应数据
汇总(Y)
数值计数百分比1 211840 36.46% 2 283301 48.76% 3 35754 6.15% 4 2747 0.47% 5 9493 1.63% 6 17367 2.99% 7 20510 3.53%
有成千上万的数据点。第4类的人数不到总数的0.5%。这种不平衡表明RUSBoost是一个合适的算法。
划分数据进行质量评估
用一半的数据来拟合一个分类器,另一半来检查结果分类器的质量。
rng (10,“旋风”)%用于再现性part = cvpartition(Y,“坚持”, 0.5);Istrain =训练(部分);拟合数据Istest =测试(部分);用于质量评估的数据汇总(Y (istrain))
数值计数百分比1 105919 36.46% 2 141651 48.76% 3 17877 6.15% 4 1374 0.47% 5 4747 1.63% 6 8684 2.99% 7 10254 3.53%
创建整体
使用深树以获得更高的集成精度。要做到这一点,将树设置为具有最大数量的决策分割N,在那里N是训练样本中的观察数。集LearnRate来0.1为了达到更高的精度。数据很大,而且对于深度树,创建集合非常耗时。
N = sum(istrain);%训练样本中的观察数t = templateTree(“MaxNumSplits”N);tic rusTree = fitcensemble(covtype(istrain,:)),Y(istrain),“方法”,“RUSBoost”,...“NumLearningCycles”, 1000,“学习者”t“LearnRate”, 0.1,“nprint”, 100);
培训RUSBoost……成熟弱学习者:100成熟弱学习者:200成熟弱学习者:300成熟弱学习者:400成熟弱学习者:500成熟弱学习者:600成熟弱学习者:800成熟弱学习者:900成熟弱学习者:1000
toc
运行时间为242.836734秒。
检查分类错误
将分类错误与集合中成员的数量画在一起。
图;抽搐的阴谋(损失(rusTree covtype(是:),Y(是),“模式”,“累积”));toc
运行时间为164.470086秒。
网格在;包含(“树的数量”);ylabel (“测试分类错误”);

使用116棵或更多的树,集合的分类误差在20%以下。对于500棵或更多的树,分类错误以较慢的速度减少。
检查每个类的混淆矩阵作为真实类的百分比。
tic Yfit = predict(rusTree,covtype(istest,:));toc
运行时间为132.353489秒。
Yfit confusionchart (Y(是),“归一化”,“row-normalized”,“RowSummary”,“row-normalized”)
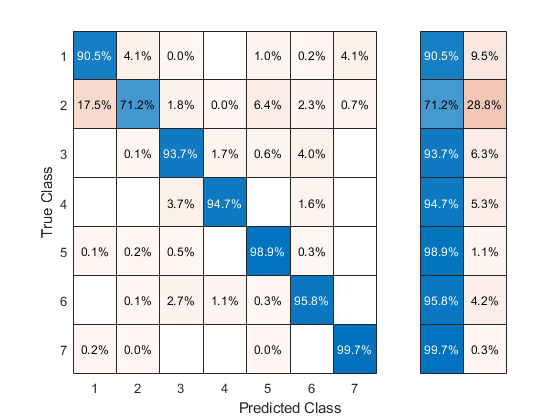
除二类外,所有类别的分类准确率均超过90%。但是第2类占据了近一半的数据,所以整体的准确性并没有那么高。
紧凑整体
乐团规模很大。方法删除数据紧凑的方法。
cmpctRus = compact(rusTree);Sz (1) = whos(“rusTree”);Sz (2) = whos(“cmpctRus”);(深圳(1)。字节深圳(2).bytes]
ans =1×2109× 1.6579 0.9423
紧凑的整体大约是原来的一半大小。
移去一半的树cmpctRus.这一操作可能对预测性能的影响很小,根据观察,1000棵树中的500棵提供了接近最佳的精度。
cmpctRus = removel收入者(cmpctRus,[500:1000]);Sz (3) = whos(“cmpctRus”);深圳(3).bytes
Ans = 452868660
精简的紧凑型合奏占用的内存约为完整合奏的四分之一。其总体损失率低于19%:
L = loss(cmpctRus,covtype(istest,:),Y(istest))
L = 0.1833
新数据的预测精度可能不同,因为集合精度可能有偏差。产生偏差是因为用于评估集合的相同数据被用于减少集合的大小。为了获得所需集合大小的无偏估计,您应该使用交叉验证。然而,这个过程很耗时。
参考文献
布莱克德,J. A.和D. J.迪恩。“从地图变量预测森林覆盖类型的人工神经网络和判别分析的比较准确性”。农业中的计算机和电子学第24卷,1999年第3期,第131-151页。
另请参阅
fitcensemble|汇总|cvpartition|培训|测验|templateTree|损失|预测|紧凑的|removeLearners|confusionchart
相关的话题
您也可以从以下列表中选择一个网站: