使用多字短语分析文本数据
这个例子展示了如何使用语法频率计数分析文本。
语法是一个元组 连续的单词。例如,一个三元(时的情况 )是一对连续词如“暴雨”。unigram(时的情况 )是一个词。bag-of-n-grams模型记录的次数,不同字格出现在文档集合。
使用bag-of-n-grams模型,您可以保留更多的信息在原文单词排序数据。例如,bag-of-n-grams模型更适合捕捉短语出现在文本,如“暴雨”和“雷暴风”。
创建一个bag-of-n-grams模型,使用bagOfNgrams。你可以输入bagOfNgrams对象为其他文本分析工具箱等功能wordcloud和fitlda。
加载和数据中提取文本
加载示例数据。该文件factoryReports.csv包含工厂的报告,包括每个事件的文本描述和分类标签。删除空的行报告。
文件名=“factoryReports.csv”;data = readtable(文件名,TextType =“字符串”);
提取文本数据的表和视图最初几个报告。
textData = data.Description;textData (1:5)
ans =5×1的字符串“项目是偶尔陷入扫描仪卷。”"Loud rattling and banging sounds are coming from assembler pistons." "There are cuts to the power when starting the plant." "Fried capacitors in the assembler." "Mixer tripped the fuses."
准备文本数据进行分析
创建一个函数符和预处理文本数据,因此它可以用于分析。这个函数preprocessText上市的例子中,执行以下步骤:
将文本数据转换为小写
较低的。在标记文本使用
tokenizedDocument。删除标点符号使用
erasePunctuation。删除列表的停止词(如“和”,“的”,和“的”)
removeStopWords。删除与2或更少的字符使用单词
removeShortWords。删除与15个或更多字符使用单词
removeLongWords。Lemmatize使用的话
normalizeWords。
使用例子预处理功能preprocessText准备的文本数据。
文件= preprocessText (textData);文档(1:5)
ans = 5×1 tokenizedDocument: 6令牌:项目偶尔卡住扫描仪线轴7令牌:大声作响爆炸声音来汇编活塞4令牌:减少力量开始工厂3令牌:炒电容器汇编3令牌:搅拌机旅行保险丝
创建词云三元
创建一个词云首先创建bag-of-n-grams模型使用的三元bagOfNgrams,然后输入模型wordcloud。
计算长度的字格2(三元),使用bagOfNgrams使用默认选项。
袋= bagOfNgrams(文档)
袋= bagOfNgrams属性:数量:(480×921双)词汇:[“项”“偶尔”“获得”“卡”“扫描仪”“大声”“活泼的”“爆炸”“声”“来”“汇编”“切”“权力”“开始”“炒”“电容器”“搅拌机”“旅行”“突然”“管”…]Ngrams:[921×2字符串]NgramLengths: 2 NumNgrams: 921 NumDocuments: 480
可视化bag-of-n-grams云模型使用一个词。
图wordcloud(袋);标题(“文本数据:预处理三元”)

Bag-of-N-Grams符合主题模式
潜在狄利克雷分配(LDA)模型是一种主题模型,发现潜在的主题集合中的文档和推断概率这个词的主题。
创建一个LDA主题模型与10个主题用fitlda。函数符合一个LDA模型把单个词的字格。
mdl = fitlda(包10 Verbose = 0);
想象第一个四个主题字云。
图tiledlayout (“流”);为i = 1:4 nexttile wordcloud (mdl);标题(“LDA的话题”+ i)结束

云强调这个词普遍共病的三元LDA的话题。功能块的三元大小根据他们的概率为指定的LDA的话题。
使用长短语分析文本
使用更长的短语分析文本,指定NGramLengths选项bagOfNgrams更大的值。
在处理长短语时,它可以保持停止词在模型中是有用的。例如,发现这句话“很不高兴”,保持停止词“是”和“不是”模型。
预处理文本。删除标点符号使用erasePunctuation,标记使用tokenizedDocument。
cleanTextData = erasePunctuation (textData);文件= tokenizedDocument (cleanTextData);
计算长度的字格3(三)使用bagOfNgrams并指定NGramLengths是3。
袋= bagOfNgrams(文档、NGramLengths = 3);
可视化bag-of-n-grams云模型使用一个词。这个词云三元模型更好的显示单词的上下文。
图wordcloud(袋);标题(“文本数据:三元模型”)
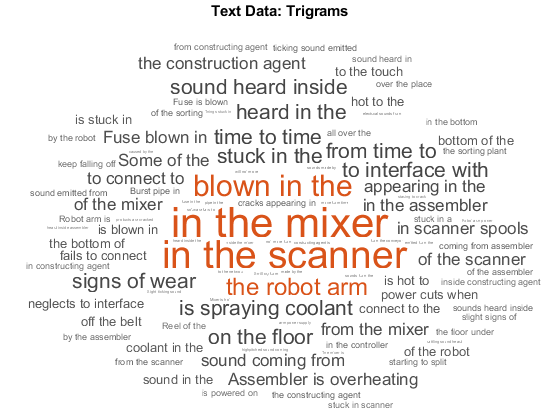
查看排名前十的三元模型及其使用的频率计数topkngrams。
台= topkngrams(袋,10)
台=10×3表Ngram计数NgramLength __________________________________ _____ ___________”“““搅拌机”14 3“在”“”“扫描仪”13 3“吹”“在”““9 3“的”“机器人”“手臂”7 3“卡”“在”“的”6 3”是““喷洒”“冷却剂”6 3”从““时间””“6 3“时间”“”“时间”6 3“听到”“在”“的”6 3“”“”“地板”6 3
例子预处理功能
这个函数preprocessText执行以下步骤为:
将文本数据转换为小写
较低的。在标记文本使用
tokenizedDocument。删除标点符号使用
erasePunctuation。删除列表的停止词(如“和”,“的”,和“的”)
removeStopWords。删除与2或更少的字符使用单词
removeShortWords。删除与15个或更多字符使用单词
removeLongWords。Lemmatize使用的话
normalizeWords。
函数文件= preprocessText (textData)%将文本数据转换为小写。cleanTextData =低(textData);%在标记文本。文件= tokenizedDocument (cleanTextData);%擦掉标点符号。= erasePunctuation文件(文档);%去除停止词的列表。= removeStopWords文件(文档);% 2或更少的字符删除单词,单词和15或更高%字符。文件= removeShortWords(文件,2);= removeLongWords文档(文档、15);% Lemmatize的话。= addPartOfSpeechDetails文件(文档);文件= = normalizeWords(文档、风格“引理”);结束
另请参阅
tokenizedDocument|bagOfWords|removeStopWords|erasePunctuation|removeLongWords|removeShortWords|bagOfNgrams|normalizeWords|topkngrams|fitlda|ldaModel|wordcloud|addPartOfSpeechDetails