使用主题模型分析文本数据
这个例子展示了如何使用潜狄利克雷分配(LDA)主题模型来分析文本数据。
潜狄利克雷分配(Latent Dirichlet Allocation, LDA)模型是一种在文档集合中发现潜在主题并推断主题中的单词概率的主题模型。
加载和提取文本数据
加载示例数据。该文件factoryReports.csv包含工厂报告,包括每个事件的文本描述和分类标签。
数据=可读数据(“factoryReports.csv”TextType =“字符串”);头(数据)
ans =8×5表类别描述紧急解决成本 _____________________________________________________________________ ____________________ ________ ____________________ _____ " 项目是偶尔陷入扫描仪卷。”“机械故障”“中等”“重新调整机”45“装配活塞发出巨大的嘎嘎声和砰砰声。”“机械故障”“中等”“重新调整机器”“开机时电源有故障。”"电子故障" "高" "完全更换" 16200 "装配器电容器烧坏"“电子故障”“高”“更换部件”“352”“混合器熔断器触发。”"电子故障" "低" "列入观察名单" 55 "爆裂管道中施工剂正在喷洒冷却剂""泄漏" "高" "更换部件" 371 "搅拌机保险丝烧断。"“电子故障”“信号低”“更换部件”“东西继续从传送带上掉下来。”"机械故障" "低" "调整机
从字段中提取文本数据描述.
textData = data.Description;textData (1:10)
ans =10×1的字符串“物品偶尔会卡在扫描仪线轴上。”“组装活塞发出巨大的嘎嘎声和砰砰声。”“在启动工厂时,电力会被切断。”“组装机里的电容器烧坏了。”“混频器把保险丝弄断了。”"爆裂管道内的施工剂正在喷洒冷却剂"“搅拌机里的保险丝烧断了。”“东西继续从传送带上掉下来。”“传送带上落下的物品。”扫描器卷筒裂开了,很快就会开始弯曲。
为分析准备文本数据
创建一个函数,对文本数据进行标记和预处理,以便用于分析。这个函数preprocessText,列于预处理功能部分的示例,按顺序执行以下步骤:
使用标记化文本
tokenizedDocument.使用词汇
normalizeWords.使用删除标点符号
erasePunctuation.删除使用停止词的列表(如“and”,“of”和“the”)
removeStopWords.删除使用2个或更少字符的单词
removeShortWords.删除使用15个或更多字符的单词
removeLongWords.
方法准备文本数据以供分析preprocessText函数。
documents = preprocessText(textData);文档(1:5)
ans = 5×1 tokenizedDocument: 6令牌:物品偶尔卡住扫描仪线轴7令牌:响亮的咔咔声来装配活塞4令牌:切断电源启动装置3令牌:炸电容器装配3令牌:混合器跳闸保险丝
从标记化的文档创建单词袋模型。
bag = bagOfWords(文档)
bag = bagOfWords with properties:计数:[480×338 double]词汇:[1×338 string] NumWords: 338 NumDocuments: 480
从单词袋模型中删除总共出现不超过两次的单词。从单词袋模型中删除任何不包含单词的文档。
袋子= removeInfrequentWords(袋子,2);包= removeEmptyDocuments(包)
bag = bagOfWords with properties:计数:[480×158 double]词汇:[1×158 string] NumWords: 158 NumDocuments: 480
拟合LDA模型
拟合7个主题的LDA模型。有关显示如何选择主题数量的示例,请参见为LDA模型选择主题数量.若要抑制详细输出,请设置详细的选项为0。为了重现性,使用rng函数与“默认”选择。
rng (“默认”) numTopics = 7;mdl = fitlda(包,numTopics,Verbose=0);
如果你有一个大的数据集,那么随机近似变分贝叶斯求解器通常更适合,因为它可以在更少的数据传递中拟合出一个好的模型。的默认解算器fitlda(折叠吉布斯抽样)可以更准确,代价是需要更长的运行时间。要使用随机近似变分贝叶斯,请设置解算器选项“savb”.有关显示如何比较LDA求解器的示例,请参见比较LDA求解器.
使用词云可视化主题
您可以使用单词云来查看每个主题中概率最高的单词。使用词汇云来可视化主题。
图t = tiledlayout(“流”);标题(t)“LDA的话题”)为i = 1:numTopics nexttile wordcloud(mdl,i);标题(“主题”+ i)结束

查看文档中混合的主题
使用与训练数据相同的预处理函数,为一组以前未见过的文档创建一个标记化文档数组。
STR = [“冷却剂正在组装器下面聚集。”“分拣机在启动时炸断保险丝。”“有一些非常响亮的咔嗒声从组装。”];newDocuments = preprocessText(str);
使用变换函数将文档转换为主题概率的向量。注意,对于非常短的文档,主题混合可能不能很好地表示文档内容。
topicmixture = transform(mdl,newDocuments);
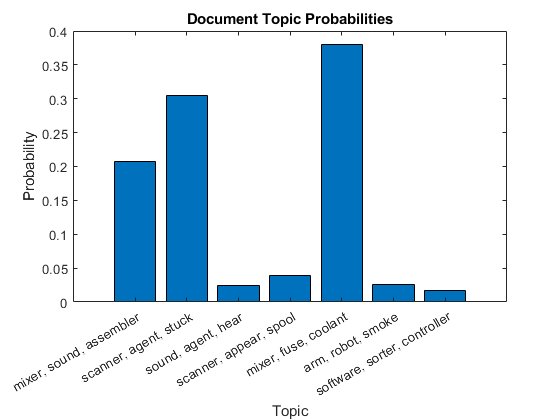
在柱状图中绘制第一个文档的文档主题概率。用对应主题的前三个词来标记主题。
为i = 1:numTopics top = topkwords(mdl,3,i);topWords(i) = join(top。词,”、“);结束图栏(topicmixture (1,:)) xlabel(“主题”) xticklabels (topWords);ylabel (“概率”)标题(“文档主题概率”)
使用堆叠柱状图可视化多个主题混合。可视化文档的主题混合。
图barh (topicMixtures,“堆叠”xlim([0 1])“主题混合”)包含(“主题概率”) ylabel (“文档”)传说(topWords...位置=“southoutside”,...NumColumns = 2)

预处理功能
这个函数preprocessText,依次执行以下步骤:
使用标记化文本
tokenizedDocument.使用词汇
normalizeWords.使用删除标点符号
erasePunctuation.删除使用停止词的列表(如“and”,“of”和“the”)
removeStopWords.删除使用2个或更少字符的单词
removeShortWords.删除使用15个或更多字符的单词
removeLongWords.
函数documents = preprocessText(textData)标记文本。documents = tokenizedDocument(textData);把这些词简化。文档= addPartOfSpeechDetails(文档);文档= normalizeWords(文档,样式=“引理”);删除标点符号。documents = eraspunctuation(文档);删除一个停止词列表。documents = removeStopWords(文档);删除2个或更少字符的单词,以及15个或更多字符的单词%字符。文档= removeShortWords(文档,2);documents = removeLongWords(documents,15);结束
另请参阅
tokenizedDocument|bagOfWords|removeStopWords|fitlda|ldaModel|wordcloud|addPartOfSpeechDetails|removeEmptyDocuments|removeInfrequentWords|变换
相关的话题
您也可以从以下列表中选择一个网站: