文本检测与识别
检测和识别图像中的文本是计算机视觉应用中一个常见的任务。例如,您可以从移动的车辆上捕获道路场景的视频,识别捕获场景中的路标,并提醒驾驶员注意这些标志。工具箱提供了检测和识别多种语言文本的函数。
文本识别的第一步是检测和分割图像中的文本区域。为了检测文本区域,使用局部图像特征检测器和描述符,或预先训练的深度学习模型来检测复杂图像场景中的文本。工具箱中的示例演示了如何使用blob分析、最大稳定极值区域(MSER)特征检测器和用于文本检测的字符区域感知(CRAFT)深度学习模型进行文本检测。
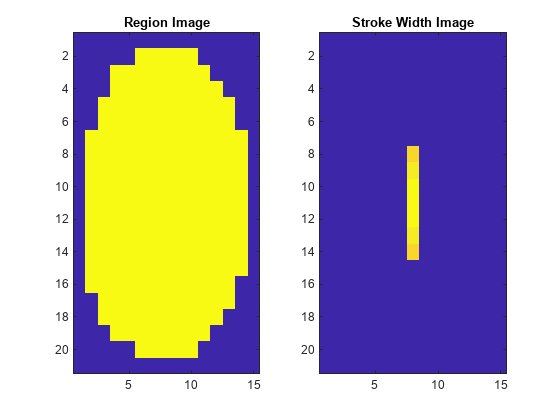
如果测试图像是前景中有文本区域的二值化图像,斑点分析工作得很好。该方法利用区域统计信息对图像前景中的文本进行有效的定位和提取。使用图像阈值分割等分割方法对图像进行二值化。
如果预先知道图像中文本区域的几何特征,则MSER特征检测器工作良好。此外,图像中的文本区域必须是具有均匀强度或颜色值的高对比度区域。特征检测器利用几何约束来过滤非文本区域,并在均匀背景和复杂背景的图像中检测文本区域。
CRAFT模型是一种鲁棒的方法,可以检测图像中的文本区域,而不考虑图像背景、对比度和强度值等因素。当分割图像中的文本区域很困难时,使用CRAFT模型。该模型比其他文本检测方法需要更多的计算资源。
您可以执行文本分割作为预处理或后处理步骤,以提高文本检测的准确性。要从图像区域分割文本,使用图像分割技术,如图像阈值和聚类。有关MATLAB的信息®图像分割函数,见图像分割.或者,您可以使用颜色阈值而且图像裂殖体应用程序交互分割图像中所需的文本区域。
下一步是使用基于机器学习(ML)的分类或光学字符识别(OCR)方法来识别检测或分割区域中的文本。的光学字符识别函数使用OCR引擎页面中的OCR语言数据支持文件,万博1manbetxTesseract开源OCR引擎.支持文件万博1manbetx包含预训练的语言数据文件,用于识别多种语言中的字符。可以使用。下载其他语言文件vision万博1manbetxSupportPackages函数或Add-On资源管理器。有关下载外接程序的详细信息,请参见获取和管理外接组件.有关如何安装和使用OCR语言数据支持文件的程序万博1manbetxTesseract开源OCR引擎,请参阅安装OCR语言数据文件.
应用程序
| OCR教练 | 训练光学字符识别模型来识别一组特定的字符 |
函数
Rubriques
使用光学字符识别
- 训练光学字符识别自定义字体
培训光学字符识别功能,通过使用OCR应用程序识别自定义语言或字体 - 安装OCR语言数据文件
万博1manbetx支持光学字符识别(OCR)语言的文件。 - 排除ocr函数结果
光学字符识别(OCR) OCR功能故障排除
例子展示



您也可以从以下列表中选择一个网站: