使用稳定的季节过滤器进行季节调整
这个例子展示了如何使用一个稳定的季节过滤器(使用加法分解)去季节化时间序列。时间序列是1973年至1978年美国每月的意外死亡人数(Brockwell和Davis, 2002)。
加载数据。
载入意外死亡数据集
负载(“Data_Accidental.mat”) y = Data;T =长度(y);图图(y/1000) h1 = gca;h1。XLim = [0, T];h1。XTick = 1:12: T;h1。XTickLabel = datestr(日期(1:12:T), 10);标题“月意外死亡”;ylabel“死亡人数(千)”;持有在
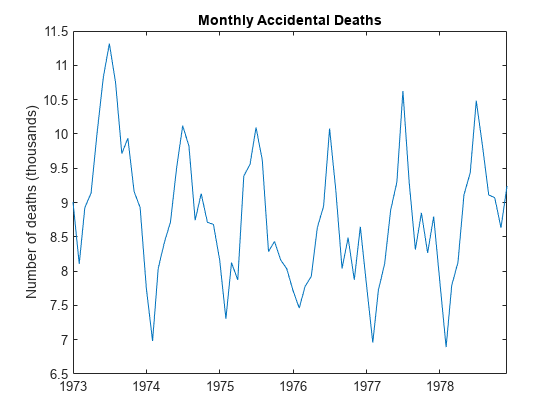
该数据显示出强烈的季节性成分,具有周期性。
应用13期移动平均线。
使用13项移动平均线平滑数据。为了防止观测损失,重复第一个和最后一个平滑值六次。从原始级数中减去平滑级数以消除数据的趋势。将移动平均趋势估计加到观测到的时间序列图上。
sW13 = (1/24; repmat(1) 1/12, 11日,1/24);y = conv (y, sW13,“相同”);y (1:6) = y (7);y (T-5: T) = y (T-6);xt =等号左边;h =情节(yS / 1000,“r”,“线宽”2);传奇(h,13任移动平均的)举行从

非趋势时间序列为xt.
使用形状参数“相同”当调用conv返回一个平滑的级数,其长度与原始级数相同。
步骤3。创建季节性指数。
创建一个单元格数组,sidx,存储每个周期对应的索引。数据是按月的,周期是12,所以第一个元素sidx是一个包含元素1,13,25,…,61 (corresponding to January observations). The second element ofsidx是一个包含元素2,14,16,…,62 (corresponding to February observations). This is repeated for all 12 months.
s = 12;sidx =细胞(s, 1);为i = 1:s sidx{i,1} = i:s:T;结束sidx {1:2}
ans =1×61 13 25 37 49 61
ans =1×62 14 26 38 50 62
使用单元格数组来存储索引,可以考虑到在观察序列的范围内,每个周期发生的次数不相同的可能性。
步骤4。使用稳定的季节性过滤器。
对非趋势序列应用稳定的季节过滤器,xt.使用步骤3中构造的指标,对每个时期对应的非趋势数据求平均值。也就是说,对所有1月份的值求平均值(在指数1、13、25、……、61处),然后对所有2月份的值求平均值(在指数2、14、26、……、62处),以此类推。把平滑的值放回到一个单一的矢量。
中心的季节估计波动在零附近。
SST = cellfun(@(x)均值(xt(x)),sidx);将平滑后的值返回到长度为N的向量中数控=地板(T / s);%。完成年rm = mod (T, s);%。额外的月海温= [repmat (sst、数控、1);海温(1:rm)];季节估计的百分比(加性)条形=意味着(sst);%归心海温= sst-sBar;图绘制(sst / 1000)标题“稳定的季节性组件”;甘氨胆酸h2 =;h2。XLim = [0 T];ylabel“死亡人数(千)”;h2。XTick = 1:12: T;h2。XTickLabel = datestr(日期(1:12:T), 10);
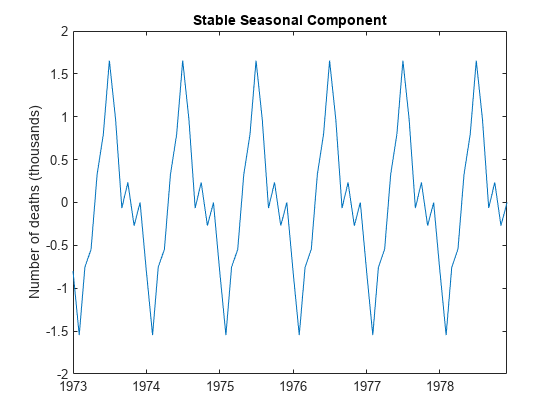
稳定的季节分量在整个序列中具有恒定的振幅。季节估计值居中,并在零附近波动。
第5步。延长的销售季节。
从原始数据中减去估计的季节成分。
Dt = y - sst;图绘制(dt / 1000)标题“延长的销售季节系列”;ylabel“死亡人数(千)”;甘氨胆酸h3 =;h3。XLim = [0 T];h3。XTick = 1:12: T;h3。XTickLabel = datestr(日期(1:12:T), 10);
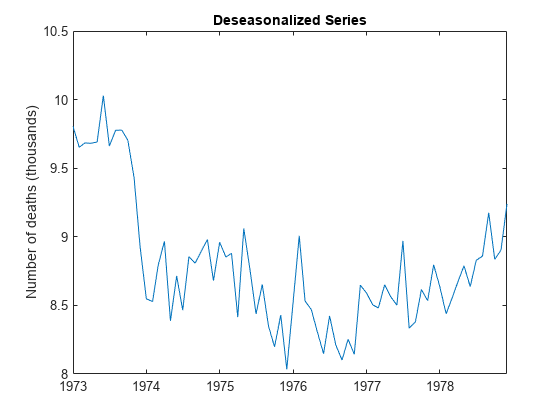
去季节化序列由长期趋势和不规则成分组成。剔除季节性因素后,意外死亡人数明显呈大规模二次型趋势。
引用:
Brockwell, P. J.和R. A. Davis。时间序列与预测导论.第二版。纽约,纽约:施普林格,2002。
另请参阅
相关的例子
更多关于
你也可以从以下列表中选择一个网站:
