预测公司违约率GydF4y2Ba
这个例子说明了如何建立企业的违约率预测模型。GydF4y2Ba
风险参数本质上是动态,并了解这些参数在时间的变化是风险管理的基本任务。GydF4y2Ba
在这个例子中的第一部分,我们与历史信用数据的迁移工作,构建一些时间序列的兴趣,并以可视化违约率动态。在这个例子中的第二部分,我们使用了一些在第一部分中构建的系列,以及一些额外的数据,以适应公司违约率预测模型,并表现出一定的回溯测试和压力测试的概念。线性回归模型对公司违约率呈现,但描述可以与其他预测方法所使用的工具和概念。在最后的附录参考模型的处理完全转换矩阵。GydF4y2Ba
有兴趣的预测,回溯测试和压力测试的人可以直接进入这个例子中的第二部分。这个例子中的第一部分是谁与信贷数据迁移工作的人更相关。GydF4y2Ba
第一部分:工作与信用迁移数据GydF4y2Ba
我们与企业发行人的历史转移概率(可变工作GydF4y2Ba的TransmatGydF4y2Ba)。这是1981-2005年的年度数据,来自[10]。这些数据包括每一年年初评级机构的数量(变量)GydF4y2BanIssuersGydF4y2Ba),以及每个等级每年新发行的数量(可变GydF4y2BanNewIssuersGydF4y2Ba)。还有一个预测企业利润,从[9],并建立企业蔓延,由[4](变量GydF4y2BaCPFGydF4y2Ba和GydF4y2BaSPRGydF4y2Ba)。一种可变指示衰退年(GydF4y2Ba不景气GydF4y2Ba),与[7]的衰退日期一致,主要用于可视化。GydF4y2Ba
Example_LoadDataGydF4y2Ba
获取不同评级类别的违约率GydF4y2Ba
我们通过对一些聚合获得投资级(IG)和投机级(SG)发行人,以及整体企业违约率公司违约率开始。GydF4y2Ba
聚集和分割是相对而言。IG相对于信用评级的集合,但是从企业的整体投资组合的角度段。其他部分是在实践的兴趣,例如,经济部门,行业或地理区域。我们使用的数据,但是,由信用评级汇总,因此,进一步的分割是不可能的。尽管如此,工具和工作流程在这里讨论可以与其他特定段模型的工作有用。GydF4y2Ba
在金融工具箱™使用的功能,具体而言,功能GydF4y2BatransprobgrouptotalsGydF4y2Ba和GydF4y2BatransprobbytotalsGydF4y2Ba,执行聚合。这些函数以与特定格式信用迁移信息的输入的结构。我们在这里建立了输入和可视化他们下面来了解他们的信息和格式。GydF4y2Ba
%预分配的结构阵列GydF4y2BatotalsByRtg(nYears,1)=结构(GydF4y2Ba'totalsVec'GydF4y2Ba,[]GydF4y2Ba“totalsMat”GydF4y2Ba,[]GydF4y2Ba...GydF4y2Ba'算法'GydF4y2Ba,GydF4y2Ba“队列”GydF4y2Ba);GydF4y2Ba对于GydF4y2Bat = 1时:nYearsGydF4y2Ba每年年初,每个评级的发行人数目%GydF4y2BatotalsByRtg(t)的.totalsVec = nIssuers(T,:);GydF4y2Ba本年度收视率之间的转换数量%GydF4y2BatotalsByRtg(t)的.totalsMat = ROUND(DIAG(nIssuers(T,:))*GydF4y2Ba...GydF4y2Ba(0.01 *的Transmat(:,:,T)));GydF4y2Ba%算法GydF4y2BatotalsByRtg(t)的崔晓军薜永生=GydF4y2Ba“队列”GydF4y2Ba;GydF4y2Ba结束GydF4y2Ba
正是看到的原始数据并且被存储在这些总计结构一侧到另一侧的数据都是有用的。原始数据包括发行人及转移概率每年的数量。例如,对于2005年:GydF4y2Ba
fprintf中(GydF4y2Ba'\ nTransition矩阵为2005:\ n \ n'GydF4y2Ba)GydF4y2Ba
2005年转移矩阵:GydF4y2Ba
Example_DisplayTransitions(挤压(TransMat(:,:,结束),nIssuers(最终,:)GydF4y2Ba...GydF4y2Ba{GydF4y2Ba'AAA'GydF4y2Ba,GydF4y2Ba'AA'GydF4y2Ba,GydF4y2Ba'一个'GydF4y2Ba,GydF4y2Ba'BBB'GydF4y2Ba,GydF4y2Ba'BB'GydF4y2Ba,GydF4y2Ba'B'GydF4y2Ba,GydF4y2Ba'CCC'GydF4y2Ba},GydF4y2Ba...GydF4y2Ba{GydF4y2Ba'AAA'GydF4y2Ba,GydF4y2Ba'AA'GydF4y2Ba,GydF4y2Ba'一个'GydF4y2Ba,GydF4y2Ba'BBB'GydF4y2Ba,GydF4y2Ba'BB'GydF4y2Ba,GydF4y2Ba'B'GydF4y2Ba,GydF4y2Ba'CCC'GydF4y2Ba,GydF4y2Ba'd'GydF4y2Ba,GydF4y2Ba'NR'GydF4y2Ba})GydF4y2Ba
初始化AAA AA A BBB BB乙CCC d NR AAA 98 88.78 9.18 1.02 0 0 0 0 0 1.02 AA 407 0 90.66 4.91 0.49 0 0 0 0 3.93甲1224 0.08 1.63 88.89 4.41 0 0 0 0 4.98 BBB 1535 0 0.2 5.93 84.04 3.060.46 0 0.07 6.25 BB 1015 0 0 0 5.71 76.75 6.9 0.2 0.2 10.25乙1010 0 0 0.1 0.59 8.51 70.59 3.76 1.58 14.85 CCC 126 0 0 0 0.79 0.79 25.4 46.83 8.73 17.46GydF4y2Ba
总计结构存储每个等级发行人的总人数在一年中开始GydF4y2BatotalsVecGydF4y2Ba场,并且总GydF4y2Ba迁移的数量GydF4y2Ba的收视率(而不是转变概率)之间GydF4y2BatotalsMatGydF4y2Ba领域。这里是2005年的信息:GydF4y2Ba
fprintf中(GydF4y2Ba'\ nTransition计数(总计结构)2005年:\ n \ n'GydF4y2Ba)GydF4y2Ba
过渡计数(总计结构)2005年:GydF4y2Ba
Example_DisplayTransitions(totalsByRtg(结束).totalsMat,GydF4y2Ba...GydF4y2BatotalsByRtg(结束).totalsVec,GydF4y2Ba...GydF4y2Ba{GydF4y2Ba'AAA'GydF4y2Ba,GydF4y2Ba'AA'GydF4y2Ba,GydF4y2Ba'一个'GydF4y2Ba,GydF4y2Ba'BBB'GydF4y2Ba,GydF4y2Ba'BB'GydF4y2Ba,GydF4y2Ba'B'GydF4y2Ba,GydF4y2Ba'CCC'GydF4y2Ba},GydF4y2Ba...GydF4y2Ba{GydF4y2Ba'AAA'GydF4y2Ba,GydF4y2Ba'AA'GydF4y2Ba,GydF4y2Ba'一个'GydF4y2Ba,GydF4y2Ba'BBB'GydF4y2Ba,GydF4y2Ba'BB'GydF4y2Ba,GydF4y2Ba'B'GydF4y2Ba,GydF4y2Ba'CCC'GydF4y2Ba,GydF4y2Ba'd'GydF4y2Ba,GydF4y2Ba'NR'GydF4y2Ba})GydF4y2Ba
初始化AAA AA A BBB BB乙CCC d NR AAA 98 87 9 1 0 0 0 0 0 1 AA 407 0 369 20 2 0 0 0 0 16甲1224 1 20 1088 54 0 0 0 0 61 BBB 1535 0 3 91 1290 477 0 1 96 1015 BB 0 0 0 58 779 70 2 2 104 1010乙0 0 1 6 86 713 38 16 150 126 CCC 0 0 0 1 1 32 59 11 22GydF4y2Ba
在总计结构的第三字段,GydF4y2Ba算法GydF4y2Ba,表示我们正在与GydF4y2Ba队列GydF4y2Ba方法 (GydF4y2Ba持续时间GydF4y2Ba也支持,虽然在信万博1manbetx息GydF4y2BatotalsVecGydF4y2Ba和GydF4y2BatotalsMatGydF4y2Ba会有所不同)。这些结构从可选的输出而得到GydF4y2BatransprobGydF4y2Ba,但这个例子显示了如何你可以直接定义这些结构。GydF4y2Ba
用GydF4y2BatransprobgrouptotalsGydF4y2Ba到组的收视率GydF4y2Ba'AAA'GydF4y2Ba至GydF4y2Ba'BBB'GydF4y2Ba(评价1〜4)到IG类别和评分GydF4y2Ba'BB'GydF4y2Ba至GydF4y2Ba'CCC'GydF4y2Ba(评分5-7)到SG类别。该GydF4y2Ba边缘GydF4y2Ba参数告诉其功能的评级是组合在一起(1〜4,图5至7)。我们还组所有非默认等级为一类。这些都是初步的步骤获得的IG,SG,每年整体违约率。GydF4y2Ba
edgesIGSG = [4 7];totalsIGSG = transprobgrouptotals(totalsByRtg,edgesIGSG);edgesAll = 7;GydF4y2Ba%也可以使用edgesAll = 2 totalsIGSGGydF4y2BatotalsAll = transprobgrouptotals(totalsByRtg,edgesAll);GydF4y2Ba
下面是在IG / SG级分组的2005年总计,以及相应的转移矩阵,利用回收的GydF4y2BatransprobbytotalsGydF4y2Ba.GydF4y2Ba
fprintf中(GydF4y2Ba'在IG / SG级别为2005 \ nTransition计数:\ n \ n'GydF4y2Ba)GydF4y2Ba
在IG / SG级别2005转变计数:GydF4y2Ba
Example_DisplayTransitions(totalsIGSG(结束).totalsMat,GydF4y2Ba...GydF4y2BatotalsIGSG(结束).totalsVec,GydF4y2Ba...GydF4y2Ba{GydF4y2Ba'IG'GydF4y2Ba,GydF4y2Ba'SG'GydF4y2Ba},GydF4y2Ba...GydF4y2Ba{GydF4y2Ba'IG'GydF4y2Ba,GydF4y2Ba'SG'GydF4y2Ba,GydF4y2Ba'd'GydF4y2Ba,GydF4y2Ba'NR'GydF4y2Ba})GydF4y2Ba
初始化IG SG d NR IG 3264 3035 54 1 174 SG 2151 66 1780 29 276GydF4y2Ba
fprintf中(GydF4y2Ba2005年IG/SG级别的\nTransition矩阵:\n\n'GydF4y2Ba)GydF4y2Ba
转换矩阵2005年在IG / SG级别:GydF4y2Ba
Example_DisplayTransitions(transprobbytotals(totalsIGSG(结束)),[]GydF4y2Ba...GydF4y2Ba{GydF4y2Ba'IG'GydF4y2Ba,GydF4y2Ba'SG'GydF4y2Ba},GydF4y2Ba...GydF4y2Ba{GydF4y2Ba'IG'GydF4y2Ba,GydF4y2Ba'SG'GydF4y2Ba,GydF4y2Ba'd'GydF4y2Ba,GydF4y2Ba'NR'GydF4y2Ba})GydF4y2Ba
IG SG d NR IG 92.98 1.65 0.03 5.33 3.07 SG 82.75 1.35 12.83GydF4y2Ba
现在得到每年都在IG / SG和非缺省的/默认级别过渡矩阵,只存储违约率(我们不使用转移概率的其余部分)。GydF4y2Ba
DefRateIG =零(nYears,1);DefRateSG =零(nYears,1);DefRate =零(nYears,1);GydF4y2Ba对于GydF4y2Bat = 1时:nYearsGydF4y2Ba在IG / SG级别和提取IG违约率和%比例转移矩阵GydF4y2Ba%为t年SG违约率GydF4y2BatmIGSG = transprobbytotals(totalsIGSG(T));DefRateIG(T)= tmIGSG(1,3);DefRateSG(T)= tmIGSG(2,3);GydF4y2Ba最多总体水平和提取总%比例转移矩阵GydF4y2Ba%为第t年企业违约率GydF4y2Ba天猫= transprobbytotals(totalsAll(T));DefRate(T)=天猫(1,2);GydF4y2Ba结束GydF4y2Ba
这里是IG,SG,和公司整体违约率的动态可视化在一起。为了强调自己的模式,而不是它们的大小,使用对数刻度。阴影带表明经济衰退年。SG和IG的模式略有不同。例如,IG率在1994比1995年较高,但正好相反为SG。更值得注意的是,IG违约率2001年的衰退后达到顶峰,在2002年,而对于SG高峰是在2001年这与工作时提出了的IG和SG违约率的动态建模可能有重要的区别,一个常见的情况不同的段。公司的总违约率是建设另外两个的组合,其模式更接近SG,很可能是由于SG与IG的相对大小。GydF4y2Ba
minIG =分钟(DefRateIG(DefRateIG〜= 0));图图(十年来,日志(DefRateSG)GydF4y2Ba“间*”GydF4y2Ba)举行GydF4y2Ba在GydF4y2Ba情节(年,日志(DefRate),GydF4y2Ba“这”GydF4y2Ba)图(十年来,日志(MAX(DefRateIG,minIG-0.001)),GydF4y2Ba'R- +'GydF4y2Ba)Example_RecessionBands举行GydF4y2Ba离GydF4y2Ba格GydF4y2Ba在GydF4y2Ba标题(GydF4y2Ba'{\ BF默认价格(对数标度)}'GydF4y2Ba)ylabel (GydF4y2Ba“日志%”GydF4y2Ba)图例({GydF4y2Ba'SG'GydF4y2Ba,GydF4y2Ba'总体'GydF4y2Ba,GydF4y2Ba'IG'GydF4y2Ba},GydF4y2Ba'位置'GydF4y2Ba,GydF4y2Ba“西北”GydF4y2Ba)GydF4y2Ba
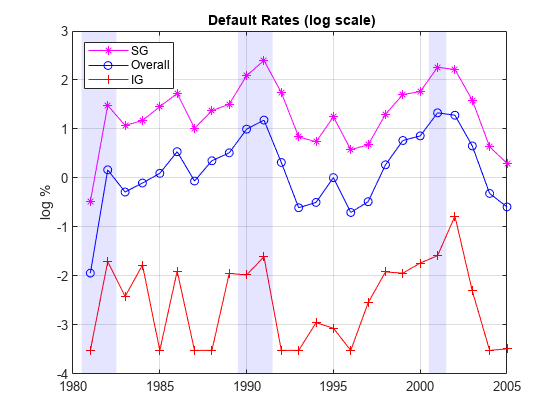
获取违约率不同的时间段GydF4y2Ba
获得的默认率是时间点(PIT)率的示例,仅使用最新的信息来估计它们。在另一个极端,我们可以使用数据集在25年内观察到的所有迁移来估计长期的或贯穿整个周期(TTC)的违约率。其他利率是衰退或扩张时期的平均违约率。GydF4y2Ba
所有这些都是容易,我们有数据和相同的工具来估算。例如,为了在经济衰退年估计平均转移概率,传GydF4y2BatransprobbytotalsGydF4y2Ba仅对应于经济衰退年总计结构。我们使用下面的逻辑索引,以优势GydF4y2Ba不景气GydF4y2Ba变量。GydF4y2BatransprobbytotalsGydF4y2Ba聚集随着时间的推移,并返回对应的转换矩阵的信息。GydF4y2Ba
tmAllRec = transprobbytotals(totalsAll(衰退));DefRateRec = tmAllRec(1,2);tmAllExp = transprobbytotals(totalsAll(〜衰退));DefRateExp = tmAllExp(1,2);tmAllTTC = transprobbytotals(totalsAll);DefRateTTC = tmAllTTC(1,2);GydF4y2Ba
下图显示了估计PIT率,TTC率,经济衰退和扩张率。GydF4y2Ba
DefRateTwoValues = DefRateExp *酮(nYears,1);DefRateTwoValues(衰退)= DefRateRec;图图(年,DefRate,GydF4y2Ba“博:”GydF4y2Ba,GydF4y2Ba'行宽'GydF4y2Ba1.2)保持GydF4y2Ba在GydF4y2Ba楼梯(年-0.5,DefRateTwoValues,GydF4y2Ba“间”GydF4y2Ba,GydF4y2Ba'行宽'GydF4y2Ba1.5)图(年,DefRateTTC *一(nYears,1),GydF4y2Ba'R-'。GydF4y2Ba,GydF4y2Ba'行宽'GydF4y2Ba,1.5)Example_RecessionBandsGydF4y2Ba离GydF4y2Ba格GydF4y2Ba在GydF4y2Ba标题(GydF4y2Ba'{\ BF违约率}'GydF4y2Ba)ylabel (GydF4y2Ba'%'GydF4y2Ba)图例({GydF4y2Ba“点在时间(PIT)”GydF4y2Ba,GydF4y2Ba“经济衰退/扩张Avg”GydF4y2Ba,GydF4y2Ba...GydF4y2Ba“通的周期(TTC)”GydF4y2Ba},GydF4y2Ba'位置'GydF4y2Ba,GydF4y2Ba“西北”GydF4y2Ba)GydF4y2Ba
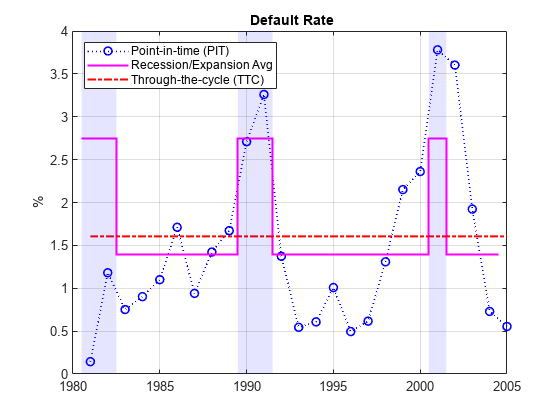
一些分析(参见,例如,[11])使用模拟其中默认速率是在经济的一般状态的条件,例如,衰退诉扩张。获得的衰退和扩展估计值能在这样的框架是有用的。这些都是历史平均水平,但是,如果作为预测的预期任何特定年份的实际违约率可能无法正常工作。在这个例子中的第二部分,我们重温在回溯测试演习中使用这些类型的历史平均值作为预测工具的。GydF4y2Ba
大厦预测因素使用信用评级数据GydF4y2Ba
利用信贷数据,你可以建立新的时间序列的兴趣。我们开始与被用作预测的预测模型在这个例子中的第二部分的年龄代理。GydF4y2Ba
时代被称为是在预测违约率的重要因素;参见,例如,[1]和[5]。这里指年龄,因为债券发出的年数。推而广之,一个投资组合的年龄是其债券的平均年龄。某些模式已经历史上观测。许多低质量的借款人发行债券违约后短短几年。当陷入困境的企业发行债券,借入的款额帮助他们作出了一两年支付。除了这一点,他们的钱唯一来源是他们的现金流,如果他们是不够的,默认情况下会发生。GydF4y2Ba
我们无法计算投资组合的确切年龄,因为在数据集中发行人级别的信息。我们遵循[6],然而,和利用在新的一年发行的数量GydF4y2BaŤGydF4y2Ba-3除以年末的发行机构总数GydF4y2BaŤGydF4y2Ba作为年龄的代表。由于滞后,年龄指标开始于1984年。对于分子,我们有关于新发行人数量的明确信息。分母上,年末的发行者数量等于明年年初的发行者数量。这是所有年份都知道的,除了最后一个,它被设置为总过渡到非违约评级加上当年新发行人的数量。GydF4y2Ba
在今年年底发行的百分比总数GydF4y2BanEOY =零(nYears,1);GydF4y2Ba%nIssuers是每个评级发行人的数量在今年年初GydF4y2Ba%nEOY(1981)= SUM nIssuers(1982年),等等直到2004年GydF4y2BanEOY(1:结束-1)=总和(nIssuers(2:端,:),2);GydF4y2Ba% nEOY(2005) =发行人在2005年底的非违约状态加上GydF4y2Ba2005%的新发行GydF4y2BanEOY(结束)= totalsAll(结束).totalsMat(1,1)+ SUM(nNewIssuers(端,:));GydF4y2Ba%年龄代理GydF4y2Ba年龄= 100 * (nan (3,1);sum (nNewIssuers (1: end-3,:), 2)。/ nEOY(4:结束)];GydF4y2Ba
其他时间序列的兴趣例子是SG的发行人在每年年底的比例,或SG年龄代理。GydF4y2Ba
% nSGEOY: SG发行人的数量在年底GydF4y2Ba%nSGEOY类似于nEOY,但对于仅SG,从图5( 'BB')至7( 'CCC')GydF4y2BaindSG = 7;nSGEOY = 0 (nYears, 1);nSGEOY (1: end-1) =总和(nIssuers(2:结束,indSG), 2);nSGEOY(end) = sum(totalsIGSG(end).totalsMat(:,2)) +GydF4y2Ba...GydF4y2Basum (nNewIssuers(结束,indSG));GydF4y2BaSG发行人的比例%GydF4y2BaSG = 100 * nSGEOY / nEOY。GydF4y2Ba%SG年龄代理:在T-3 /总发行人新发行SG在t年年底GydF4y2BaAGESG = 100 * [楠(3,1);总和(nNewIssuers(1:结束-3,indSG),2)./ nEOY(4:结束)];GydF4y2Ba
第二部分:一个预测模型违约率GydF4y2Ba
我们用下面的线性回归模型为企业违约率工作GydF4y2Ba
哪里GydF4y2Ba
年龄:年龄代理上述定义GydF4y2Ba
CPF:企业盈利预测GydF4y2Ba
SPR:在国债企业传播GydF4y2Ba
这与[6]中的模型相同,只是[6]中的模型仅适用于IG。GydF4y2Ba
如前所述,年龄被称为是关于拖欠率的重要因素。该企业的利润提供了有关经济环境的信息。企业传播是信贷质量的代理。年龄,环境和质量都在信用分析模型中经常发现的三个维度。GydF4y2Ba
inSample = 4:nYears-1;T =长度(inSample);varNames = {GydF4y2Ba'年龄'GydF4y2Ba,GydF4y2Ba'CPF'GydF4y2Ba,GydF4y2Ba'SPR'GydF4y2Ba};X = [年龄CPF SPR];X = X(inSample,:);Y = DefRate(inSample + 1);GydF4y2Ba%DefaultRate,今年T + 1GydF4y2Ba统计= regstats (y、X);fprintf中(GydF4y2Ba'\ nConst AGE CPF SPR行政裁决法^ 2 \ N'GydF4y2Ba)GydF4y2Ba
保存时间CPF SPR adjR^2GydF4y2Ba
fprintf中(GydF4y2Ba'%1.2F%1.2F%1.2F%1.2F%1.4F \ N'GydF4y2Ba,GydF4y2Ba...GydF4y2Ba[stats.beta; stats.adjrsquare])GydF4y2Ba
-1.19 -0.10 0.15 0.71 0.7424GydF4y2Ba
该系数具有预期的符号:违约率趋于增加与3年期发行人比例较高,下降凭借良好的企业利润,当企业产量较高增长。调整后的R平方显示一个不错的选择。GydF4y2Ba
样本内拟合,即模型预测与用于拟合模型的样本点之间的距离,如下图所示。GydF4y2Ba
BHAT = stats.beta;yHat = [一(T,1),X] * BHAT;图图((三年inSample + 1),DefRate(inSample + 1),GydF4y2Ba“柯”GydF4y2Ba,GydF4y2Ba'行宽'GydF4y2Ba,1.5%,GydF4y2Ba...GydF4y2Ba“MarkerSize”GydF4y2Ba10,GydF4y2Ba'MarkerFaceColor'GydF4y2Ba,GydF4y2Ba'G'GydF4y2Ba)举行GydF4y2Ba在GydF4y2Ba积((三年inSample + 1),yHat,GydF4y2Ba'B-S'GydF4y2Ba,GydF4y2Ba'行宽'GydF4y2Ba,1.2,GydF4y2Ba“MarkerSize”GydF4y2Ba10)保持GydF4y2Ba离GydF4y2Ba格GydF4y2Ba在GydF4y2Ba传说({GydF4y2Ba'实际'GydF4y2Ba,GydF4y2Ba“模型”GydF4y2Ba},GydF4y2Ba'位置'GydF4y2Ba,GydF4y2Ba“西北”GydF4y2Ba)标题(GydF4y2Ba“{\ BF企业违约率模型:在-拟合效果}”GydF4y2Ba)包含(GydF4y2Ba'年'GydF4y2Ba)ylabel (GydF4y2Ba“百分比”GydF4y2Ba)GydF4y2Ba
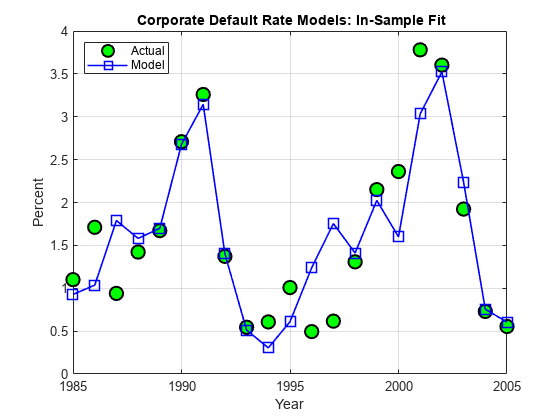
可以看出,没有强有力的统计证据得出的结论是线性回归的假设被违反。很明显,违约率不是正态分布。该模型,然而,这并不做这样的假设。在模型中唯一的正态假设是,鉴于预测值,预测的和观察到的缺省率通常分布之间的误差。通过查看样品中配合,这似乎不是不合理的。该误差的大小当然似乎独立的违约率是高还是低。2001年有很高的违约率和高误差,但多年的1991年或2002年也有高利率,但误差很小。同样,低违约率十年如1996年和1997年显示出相当大的错误,但多年的2004或2005年也有类似的低利率和微小的错误。GydF4y2Ba
该模型的详尽的统计分析是超出范围在这里,但在统计和机器学习工具箱™和计量经济学工具箱™几个具体的例子。GydF4y2Ba
回溯测试GydF4y2Ba
来评估这个模型进行了样本外,我们成立了一个回测锻炼。在1995年年底开始,我们拟合线性回归模型与信息提供在那个日期,并比较模型预测实际违约率观察来年。我们重申对所有随后几年不变,直到试样结束。GydF4y2Ba
回溯测试,模型的相对表现,相较于替代品的时候,是很容易,在隔离模型的性能进行评估。在这里,我们有两个选择,以确定明年的违约率,在实践中,两种可能的候选人。一个是TTC违约率,从样品到本年度,非常稳定的违约率估计的开始处的数据估算。另一种是PIT率,使用只从最近一年的数据估计,更敏感于最近发生的事件。GydF4y2Ba
XBT =(年龄、论坛、SPR)准确性;yBT = DefRate;iYear0 =找到(= = 1984年);GydF4y2Ba第一年%指数在样品中,1984年GydF4y2BaT =找到(年== 1995);GydF4y2Ba%IND“当前”的一年,开始在1995年,更新循环GydF4y2BaYearsBT = 1996:2005;GydF4y2Ba%年BT的运动预测GydF4y2BaiYearsBT =找到(年== 1996):查找(年== 2005);GydF4y2Ba%对应的指数GydF4y2BanYearsBT =长度(YearsBT);GydF4y2Ba多年从事BT锻炼%数量GydF4y2BaMethodTags = {GydF4y2Ba“模型”GydF4y2Ba,GydF4y2Ba'坑'GydF4y2Ba,GydF4y2Ba'TTC'GydF4y2Ba};NMETHODS =长度(MethodTags);PredDefRate =零(nYearsBT,NMETHODS);ErrorBT =零(nYearsBT,NMETHODS);阿尔法= 0.05;PredDefLoBnd =零(nYearsBT,1);PredDefUpBnd =零(nYearsBT,1);GydF4y2Ba对于GydF4y2BaK = 1:nYearsBTGydF4y2Ba预测因子从1984年到“最后一年”(T-1)样本年的百分比GydF4y2BainSampleBT = iYear0:T-1;GydF4y2Ba%方法1:线性回归模型GydF4y2Ba%适合回归模型与数据上升到“当前”年(T)GydF4y2Bas = regstats (yBT (inSampleBT + 1), XBT (inSampleBT,:))准确性;GydF4y2Ba%预测违约率为“下一个”年(T + 1)GydF4y2BaPredDefRate(K,1)= [1 XBT(T,:)] * s.beta;GydF4y2Ba%计算预测间隔GydF4y2BaTCRIT = TINV(1-α/ 2,s.tstat.dfe);PredStd = SQRT([1 XBT(T,:)] * s.covb * [1 XBT(T,:)]'+ s.mse);PredDefLoBnd(K)= MAX(0,PredDefRate(K,1) - * TCRIT PredStd);PredDefUpBnd(K)= PredDefRate(K,1)+ TCRIT * PredStd;GydF4y2Ba%方法2:点在时间(PIT)默认速率GydF4y2BaPredDefRate(K,2)= DefRate(T);GydF4y2Ba%方法3:通的周期(TTC)默认速率GydF4y2Ba淘宝商城= transprobbytotals (totalsAll (iYear0: T));PredDefRate (k, 3) =淘宝商城(1、2);GydF4y2Ba%更新错误GydF4y2BaErrorBT(k,:) = PredDefRate(k,:) - DefRate(T+1);GydF4y2Ba%移动到明年GydF4y2BaT = T + 1;GydF4y2Ba结束GydF4y2Ba
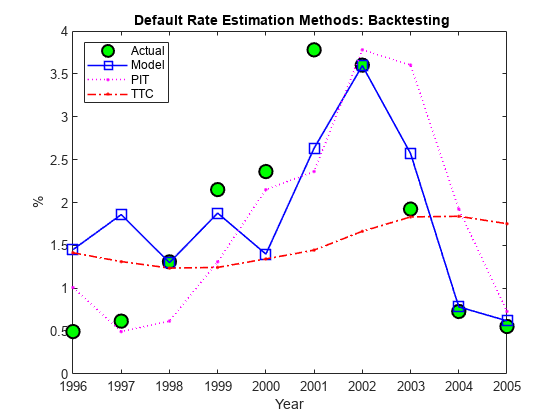
这里有三个替代方法的预测相比,观察到的实际违约率。不出所料,TTC显示了非常差的预测能力。然而,这不是明摆着PIT或线性回归模型是否使得这10年的时间跨度更准确的预测。GydF4y2Ba
Example_BacktestPlot(YearsBT,DefRate(iYearsBT),PredDefRate,GydF4y2Ba'年'GydF4y2Ba,GydF4y2Ba'%'GydF4y2Ba,GydF4y2Ba...GydF4y2Ba“{\ BF违约率估算方法:回溯测试}”GydF4y2Ba,GydF4y2Ba...GydF4y2Ba[GydF4y2Ba'实际'GydF4y2BaMethodTags]GydF4y2Ba“西北”GydF4y2Ba)GydF4y2Ba
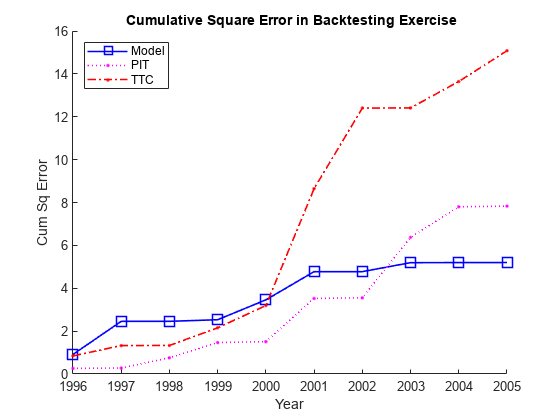
下面的情节跟踪累积误差平方,通常用于在回测练习比较的措施。这证实了TTC作为一个贫穷的替代品。PIT显示低于九十年代后期线性回归模型累积误差,但2001年的经济衰退之后,情况正好相反。累积误差平方,但是,是不是一个直观的指标,它是很难得到的感觉是什么在实际中这些替代方法之间的差异。GydF4y2Ba
CumSqError = cumsum(ErrorBT ^ 2);Example_BacktestPlot(YearsBT,[],CumSqError,GydF4y2Ba'年'GydF4y2Ba,GydF4y2Ba“暨广场错误”GydF4y2Ba,GydF4y2Ba...GydF4y2Ba“{在回溯测试练习\ BF累计方差}”GydF4y2Ba,GydF4y2Ba...GydF4y2BaMethodTags,GydF4y2Ba“西北”GydF4y2Ba)GydF4y2Ba
这是有道理的预测误差换算成金钱衡量。在这里,我们测量所述预测误差对用于在机构产生损失准备的简化框架的影响。GydF4y2Ba
我们假设一个均匀的组合,所有学分都默认的概率相同,相同的违约损失率(LGD),在默认情况下,相同的曝光(EAD)。无论LGD和EAD被认为是已知的。为简单起见,我们把这些值常数10年的锻炼。我们在100万台LGD为45%,而每EAD债券。该组合被认为有一千债券,因此投资组合的总价值,总EAD,为100十亿。GydF4y2Ba
对于今年预测的违约率GydF4y2BaŤGydF4y2Ba,确定在今年年底GydF4y2BaŤGydF4y2Ba-1,是用于计算年预期损失GydF4y2BaŤGydF4y2Ba
这是在今年年初加入亏损储备量GydF4y2BaŤGydF4y2Ba.在年底,实际损失是已知的GydF4y2Ba
我们假设未使用的损失准备留在储备基金。在练习的开始储备起始余额为零。如果实际损失超过预期损失,多年积累的未使用的储备首次使用,且仅当这些用完,资金是用于支付的缺口。这一切都转化为下面的公式GydF4y2Ba
或等价GydF4y2Ba
下图显示了损失准备金余额为每个在回溯测试演习三个备选方案。GydF4y2Ba
EAD = 100吨*酮(nYearsBT,1);GydF4y2Ba%在数十亿美元GydF4y2BaLGD = 0.45 *酮(nYearsBT,1);GydF4y2Ba%违约损失率,45%GydF4y2Ba%超额准备金不足或每年,数十亿GydF4y2BaReservesExcessShortfall = bsxfun (o @times。*乐金显示器,ErrorBT / 100);GydF4y2Ba每年的累积准备金余额,以十亿计GydF4y2BaReservesBalanceEOY = cumsum(ReservesExcessShortfall);Example_BacktestPlot(YearsBT,[],ReservesBalanceEOY,GydF4y2Ba'年'GydF4y2Ba,GydF4y2Ba...GydF4y2Ba“数十亿美元”GydF4y2Ba,GydF4y2Ba...GydF4y2Ba'{\ BF储备余额(EOY):回测}'GydF4y2Ba,GydF4y2Ba...GydF4y2BaMethodTags,GydF4y2Ba'SW'GydF4y2Ba)网格GydF4y2Ba在GydF4y2Ba
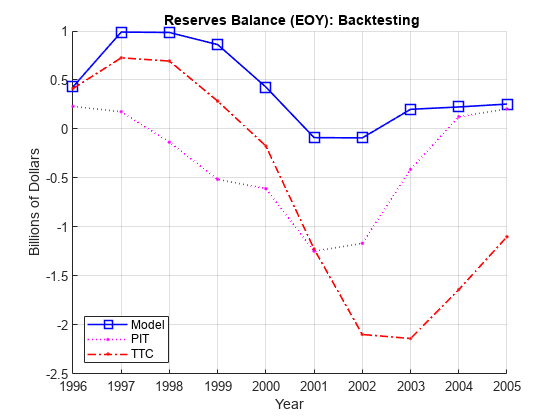
使用线性回归模型中,我们只观察储备赤字两头在外十年,最大的赤字,2001年为0.09十亿,只有九个投资组合价值的基点。GydF4y2Ba
相比之下,TTC和PIT均达到1.2十亿到2001年,事情变得更糟了TTC在未来两年,到2003年达到2.1十亿赤字赤字PIT不改正的2001年后迅速,到2004年储备有盈余。然而,TTC和PIT都导致更多的赤字比多年盈余年这项工作。GydF4y2Ba
线性回归模型显示更多的不是本练习的替代品的反周期效果。一边用线性回归模型达到接近一十亿在未使用的储备1997年和1998年的高水平钱集转化为贷款的放缓(不仅仅体现在运动,因为我们外生强加的投资组合的价值)。此外,资本只是稍微2001年经济衰退的感谢累计比上年扩大储备过程中的影响。这相当于如果需要的话,在经济复苏过程中可用于备份进一步借贷更多资金。GydF4y2Ba
我们讨论的最后一个回溯测试工具是预测区间的使用。线性回归模型提供了计算新观测值置信区间的标准公式。在下一个图中显示的是反测试活动中跨度为10年的时间间隔。GydF4y2Ba
图图(YearsBT,DefRate(iYearsBT)GydF4y2Ba“柯”GydF4y2Ba,GydF4y2Ba'行宽'GydF4y2Ba,1.5%,GydF4y2Ba“MarkerSize”GydF4y2Ba10,GydF4y2Ba...GydF4y2Ba'MarkerFaceColor'GydF4y2Ba,GydF4y2Ba'G'GydF4y2Ba)举行GydF4y2Ba在GydF4y2Ba情节(YearsBT,PredDefRate(:,1),GydF4y2Ba'B-S'GydF4y2Ba,GydF4y2Ba'行宽'GydF4y2Ba,1.2,GydF4y2Ba“MarkerSize”GydF4y2Ba,10)情节(YearsBT,[PredDefLoBnd PredDefUpBnd]GydF4y2Ba'B:'GydF4y2Ba,GydF4y2Ba'行宽'GydF4y2Ba1.2)保持GydF4y2Ba离GydF4y2BastrConf = num2str((1-α)* 100);标题([GydF4y2Ba“{\ BF回溯测试结果与”GydF4y2BastrConfGydF4y2Ba“%预测间隔}”GydF4y2Ba])xlabel(GydF4y2Ba'年'GydF4y2Ba);ylabel (GydF4y2Ba'%'GydF4y2Ba);传说({GydF4y2Ba'实际'GydF4y2Ba,GydF4y2Ba'预料到的'GydF4y2Ba,GydF4y2Ba“CONF边界”GydF4y2Ba},GydF4y2Ba'位置'GydF4y2Ba,GydF4y2Ba“西北”GydF4y2Ba);GydF4y2Ba
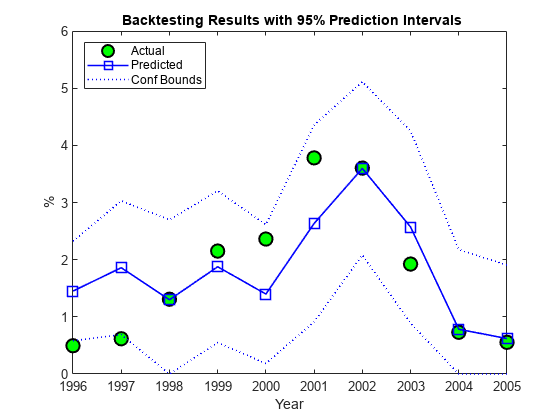
观察到的违约率落在预测区间之外的两年,1996年和1997年,在非常低的违约率观察。对于95%的置信水平,三分之二的10看起来很高。然而,在这些情况下,所观察到的值落入勉强外预测区间,其是用于模型中的正号。它也为正,预测间隔包含围绕2001年衰退所观察到的值。GydF4y2Ba
压力测试GydF4y2Ba
压力测试是远远超出了计算工具面广;参见,例如,[3]。我们展示了一些工具,可以被纳入到全面的压力测试框架。我们建立上面给出的线性回归模型,但其概念和工具,与其他预测方法兼容。GydF4y2Ba
所述第一工具是利用预测间隔,以限定一个最坏的情况下的预测。这是只占,而不是在预测值模型中的不确定性。GydF4y2Ba
我们使用预测器的基线场景,在我们的例子中,是我们的年龄代理的最新已知值GydF4y2Ba年龄GydF4y2Ba,企业盈利预测,GydF4y2BaCPFGydF4y2Ba和企业传播,GydF4y2BaSPRGydF4y2Ba.然后,我们用线性回归模型来计算95%的置信度上界预测默认速率。这样做的动机在回测部分,其中95%的置信上限作为一个保守的束缚,当预测低估了实际违约率的最后情节所示。GydF4y2Ba
TCRIT = TINV(1-α/ 2,stats.tstat.dfe);XLast = [AGE(结束),CPF(结束),SPR(端)];yPred = [1 XLast] * stats.beta;PredStd = SQRT([1 XLast] * stats.covb * [1 XLast]'+ stats.mse);yPredUB = yPred + TCRIT * PredStd;fprintf中(GydF4y2Ba'\ nPredicted违约率:\ n'GydF4y2Ba);GydF4y2Ba
预计违约率:GydF4y2Ba
fprintf中(GydF4y2Ba'基准:%4.2f %% \ n'GydF4y2Ba,yPred);GydF4y2Ba
基线:1.18%GydF4y2Ba
fprintf中(GydF4y2Ba'%克%%上界:%4.2f %% \ N'GydF4y2Ba中,(1-α)* 100,yPredUB);GydF4y2Ba
95%的上界:2.31%GydF4y2Ba
下一步是将强调在分析中预测的情景。GydF4y2BaCPFGydF4y2Ba和GydF4y2BaSPRGydF4y2Ba可以在短期内改变,而GydF4y2Ba年龄GydF4y2Ba不能。这个很重要。预计该公司利润和企业的传播是由世界的事件,其中包括,例如,自然灾害的影响。这些预测可以显著一夜之间改变。另一方面,GydF4y2Ba年龄GydF4y2Ba取决于可以改变新老贷款在时间比例管理的决定,但这些决定需要几个月,甚至几年,在反映GydF4y2Ba年龄GydF4y2Ba时间序列。情景GydF4y2Ba年龄GydF4y2Ba与较长期的分析兼容。下面我们来看一下提前一年而已,并保持GydF4y2Ba年龄GydF4y2Ba定的本节的其余部分。GydF4y2Ba
为方便起见,定义预测默认率和置信区间为函数GydF4y2BaCPFGydF4y2Ba和GydF4y2BaSPRGydF4y2Ba简化了情景分析。GydF4y2Ba
yPredFn = @(CPF,SPR)[1 AGE(结束)CPF SPR] * stats.beta;PredStdFn = @(CPF,SPR)SQRT([1 AGE(结束)CPF SPR] * stats.covb *GydF4y2Ba...GydF4y2Ba[1 AGE(结束)CPF SPR]'+ stats.mse);yPredUBFn = @(CPF,SPR)(yPredFn(CPF,SPR)+ TCRIT * PredStdFn(CPF,SPR));yPredLBFn = @(CPF,SPR)(yPredFn(CPF,SPR) - TCRIT * PredStdFn(CPF,SPR));GydF4y2Ba
有两种极端的情况会引起人们的兴趣,一种是企业利润预期相对于基准水平下降4%,另一种是企业利差较基准水平上升100个基点。GydF4y2Ba
在一次移动一个预测是不是在这种情况下,不合理的,因为之间的相关性GydF4y2BaCPFGydF4y2Ba和GydF4y2BaSPRGydF4y2Ba是非常低的。中度相关水平可能需要扰动预测在一起,得到更可靠的结果。高度相关的预测通常不会在同一模型中共存,因为它们提供的冗余信息。GydF4y2Ba
fprintf中(GydF4y2Ba'\ n \ n假设分析\ n'GydF4y2Ba);GydF4y2Ba
假设分析GydF4y2Ba
fprintf中(GydF4y2Ba'方案LB泼尼松UB \ N'GydF4y2Ba);GydF4y2Ba
情景LB强的松UBGydF4y2Ba
CPF = CPF(结束)-4;SPR = SPR(端);yPredRange = [yPredLBFn(CPF,SPR),yPredFn(CPF,SPR),yPredUBFn(CPF,SPR)];fprintf中(GydF4y2Ba'CPF下降4 %%%4.2f %%%4.2f %%%4.2f %% \ N'GydF4y2Ba,yPredRange);GydF4y2Ba
CPF下降4%0.42%1.57%2.71%GydF4y2Ba
CPF = CPF(端);SPR = SPR(结束)+1;yPredRange = [yPredLBFn(CPF,SPR),yPredFn(CPF,SPR),yPredUBFn(CPF,SPR)];fprintf中(GydF4y2Ba'SPR上升1 %%%4.2f %%%4.2f %%%4.2f %% \ N'GydF4y2Ba,yPredRange);GydF4y2Ba
SPR上涨1%0.71%1.88%3.05%GydF4y2Ba
CPF = CPF(端);SPR = SPR(端);yPredRange = [yPredLBFn(CPF,SPR),yPredFn(CPF,SPR),yPredUBFn(CPF,SPR)];fprintf中(GydF4y2Ba'基线%4.2f %%%4.2f %%%4.2f %% \ N'GydF4y2Ba,yPredRange);GydF4y2Ba
基线0.04% 1.18% 2.31%GydF4y2Ba
fprintf中(GydF4y2Ba'CPF和SPR之间\ nCorrelation:%4.3f \ N'GydF4y2Ba,科尔(CPF,SPR));GydF4y2Ba
CPF和SPR之间的相关性:0.012GydF4y2Ba
现在我们从全局的角度来分析场景。我们将违约率预测可视化为的函数,而不是一次分析一个场景GydF4y2BaCPFGydF4y2Ba和GydF4y2BaSPRGydF4y2Ba.更确切地说,我们在一个整体网格划分违约率轮廓GydF4y2BaCPFGydF4y2Ba和GydF4y2BaSPRGydF4y2Ba值。我们使用上界保守的95%。GydF4y2Ba
如果我们假设的值的特定二元分布GydF4y2BaCPFGydF4y2Ba和GydF4y2BaSPRGydF4y2Ba,我们可以绘制其分布的轮廓在同一个人物。这将使上飘落在每个区域的概率视觉信息。缺乏这样的分布,我们只需添加到情节GydF4y2BaCPFGydF4y2Ba-GydF4y2BaSPRGydF4y2Ba在我们的样本中观察到的配对,是一个历史的、经验的分布。示例中的最后一个观察结果,即基线场景,用红色标记。GydF4y2Ba
gridCPF = 2 *分钟(CPF):0.1:最大(CPF);gridSPR =分钟(SPR):0.1:2 *最大(SPR);nGridCPF =长度(gridCPF);nGridSPR =长度(gridSPR);DefRateUB =零(nGridCPF,nGridSPR);GydF4y2Ba对于GydF4y2BaI = 1:nGridCPFGydF4y2Ba对于GydF4y2BaJ = 1:nGridSPR DefRateUB(I,J)= yPredUBFn(gridCPF(i)中,gridSPR(J));GydF4y2Ba结束GydF4y2Ba结束GydF4y2BaExample_StressTestPlot(gridCPF,gridSPR,DefRateUB,CPF,SPR,GydF4y2Ba...GydF4y2Ba“企业盈利预测(%)”GydF4y2Ba,GydF4y2Ba'企业传播(%)'GydF4y2Ba,GydF4y2Ba...GydF4y2Ba[GydF4y2Ba'{\ BF'GydF4y2BastrConfGydF4y2Ba'%UB默认率区域(以%计)}'GydF4y2Ba])GydF4y2Ba
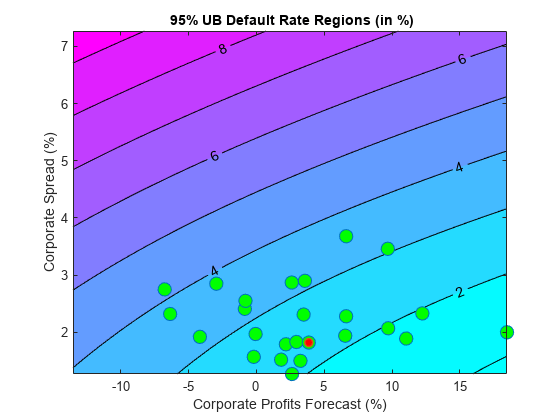
非常不同的预测值,导致类似的违约率水平。例如,考虑一个利润预计在10%左右有3.5%的价差和利润有2%的价差预测的-2.5%,它们都导致略有3%以上的违约率。此外,在现有的历史上唯一的一个点产生超过4%以上的违约率。GydF4y2Ba
货币方面,再一次,可能更有意义。我们采用巴塞尔II资本要求公式(见[2])的违约率换算成金钱衡量。巴塞尔II公式是方便,因为它是分析的(没有必要模拟估算资本要求),而且还因为它仅仅取决于违约的概率。我们定义的新巴塞尔协议资本要求的功能GydF4y2BaķGydF4y2Ba.GydF4y2Ba
%相关作为PD的函数GydF4y2BaW = @(PD)(1-EXP(-50 * PD))/(1-EXP(-50));GydF4y2Ba重量%GydF4y2BaR = @(PD)(0.12 * W(PD)+ 0.24 *(1-W(PD)));GydF4y2Ba%的相关性GydF4y2Ba%的Vasicek式GydF4y2BaV = @(PD)normcdf(NORMINV(PD)+ R(PD)* NORMINV(0.999)./ SQRT(1-R(PD))。);GydF4y2Ba%参数b为成熟调整GydF4y2BaB = @(PD)(0.11852-0.05478 *日志(PD))^ 2。GydF4y2Ba%巴塞尔II资本要求,LGD=45%,到期M=2.5(分子GydF4y2Ba%在到期调整项变为1)GydF4y2BaK = @(PD)0.45 *(V(PD)-β)*(1./(1-1.5*b(pd)))。GydF4y2Ba
最坏情况下的违约率的整个网格GydF4y2BaCPFGydF4y2Ba-GydF4y2BaSPRGydF4y2Ba对存储在GydF4y2BaDefRateUBGydF4y2Ba.通过应用功能GydF4y2BaķGydF4y2Ba至GydF4y2BaDefRateUBGydF4y2Ba我们可以想像在同一电网的资金需求。GydF4y2Ba
CapReq = 100 * K(DefRateUB / 100);Example_StressTestPlot(gridCPF,gridSPR,CapReq,CPF,SPR,GydF4y2Ba...GydF4y2Ba“企业盈利预测(%)”GydF4y2Ba,GydF4y2Ba'企业传播(%)'GydF4y2Ba,GydF4y2Ba...GydF4y2Ba{GydF4y2Ba'{\bf资本需求区域(价值的%)}'GydF4y2Ba;GydF4y2Ba...GydF4y2Ba[GydF4y2Ba{\高炉使用的GydF4y2BastrConfGydF4y2Ba'% UB违约率}'GydF4y2Ba]})GydF4y2Ba
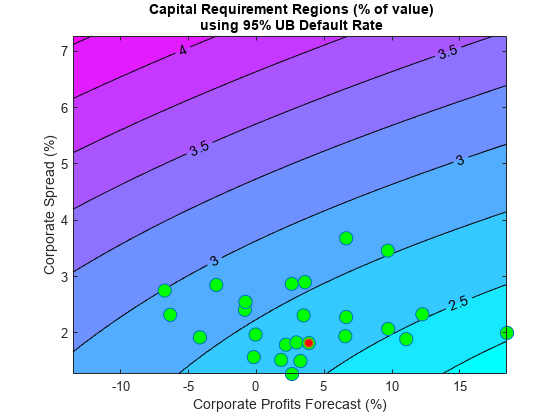
轮廓水平现在显示的资本要求,投资组合价值的百分比。这两个场景以上,为3.5%价差10%的利润,和-2.5%利润和2%的价差,导致近2.75%的资本金要求。从历史数据的最坏情况点产生约3%的资本要求。GydF4y2Ba
该可视化也可使用,例如,作为反向压力测试分析的一部分。资本的临界水平可以首先确定,这一数字可以被用来确定在这种情况下,风险因素值(区GydF4y2BaCPFGydF4y2Ba和GydF4y2BaSPRGydF4y2Ba)产生这些临界水平。GydF4y2Ba
而不是历史观察GydF4y2BaCPFGydF4y2Ba和GydF4y2BaSPRGydF4y2Ba为危险因素的经验分布可以使用模拟,例如,一个矢量自回归(VAR)从计量经济学模型工具箱™。对应于每个默认概率水平的资本需求可以通过模拟来发现如果一个封闭形式的式不可用,并且可以产生相同的曲线图。对于大型模拟,采用并行计算工具箱™或MATLAB®并行服务器分布式计算的实现™可以使过程更加高效。GydF4y2Ba
附录:建模全部转移矩阵GydF4y2Ba
转移矩阵的时间而改变,它们的动态的完整说明,需要用多维度的时间序列的工作。有,但是,即利用转移矩阵的特定结构,以减少问题的维数的技术。[8]中,例如,关系到下调的比例单个参数被使用,并且两者[6]和[8]描述了使用一个单一的参数来换档转变概率的方法。后一种方法被示出本附录英寸GydF4y2Ba
该方法采用的TTC转换矩阵作为基线。GydF4y2Ba
tmTTC = transprobbytotals(totalsByRtg);Example_DisplayTransitions(tmTTC,[],GydF4y2Ba...GydF4y2Ba{GydF4y2Ba'AAA'GydF4y2Ba,GydF4y2Ba'AA'GydF4y2Ba,GydF4y2Ba'一个'GydF4y2Ba,GydF4y2Ba'BBB'GydF4y2Ba,GydF4y2Ba'BB'GydF4y2Ba,GydF4y2Ba'B'GydF4y2Ba,GydF4y2Ba'CCC'GydF4y2Ba},GydF4y2Ba...GydF4y2Ba{GydF4y2Ba'AAA'GydF4y2Ba,GydF4y2Ba'AA'GydF4y2Ba,GydF4y2Ba'一个'GydF4y2Ba,GydF4y2Ba'BBB'GydF4y2Ba,GydF4y2Ba'BB'GydF4y2Ba,GydF4y2Ba'B'GydF4y2Ba,GydF4y2Ba'CCC'GydF4y2Ba,GydF4y2Ba'd'GydF4y2Ba,GydF4y2Ba'NR'GydF4y2Ba})GydF4y2Ba
AAA AA A BBB BB乙CCC d NR AAA 88.2 7.67 0.49 0.09 0.06 0 0 0 3.49 AA 0.58 87.16 7.63 0.58 0.06 0.11 0.02 0.01 3.85 0.05 1.9 87.24 5.59 0.42 0.15 0.03 0.04 4.58 BBB 0.02 0.16 3.85 84.13 4.27 0.76 0.17 0.27 6.37 BB0.03 0.04 0.25 5.26 75.74 7.36 0.9 1.12 9.29乙0 0.05 0.19 0.31 5.52 72.67 4.21 5.38 11.67 CCC 0 0 0.28 0.41 1.24 10.92 47.06 27.02 13.06GydF4y2Ba
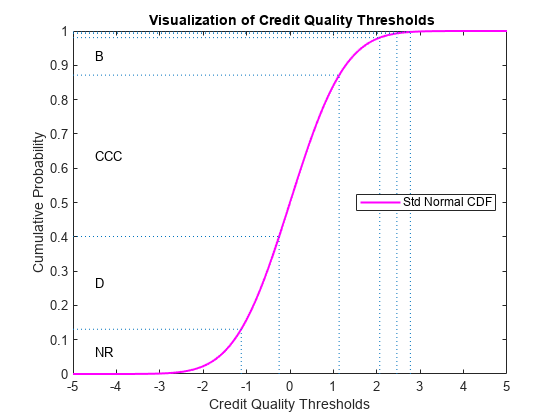
来表示该矩阵的等效方法是通过将其转化成信用质量阈值,即,标准正态分布,其产生相同的过渡概率(逐行)的临界值。GydF4y2Ba
thresholdMat = transprobtothresholds (tmTTC);Example_DisplayTransitions (thresholdMat [],GydF4y2Ba...GydF4y2Ba{GydF4y2Ba'AAA'GydF4y2Ba,GydF4y2Ba'AA'GydF4y2Ba,GydF4y2Ba'一个'GydF4y2Ba,GydF4y2Ba'BBB'GydF4y2Ba,GydF4y2Ba'BB'GydF4y2Ba,GydF4y2Ba'B'GydF4y2Ba,GydF4y2Ba'CCC'GydF4y2Ba},GydF4y2Ba...GydF4y2Ba{GydF4y2Ba'AAA'GydF4y2Ba,GydF4y2Ba'AA'GydF4y2Ba,GydF4y2Ba'一个'GydF4y2Ba,GydF4y2Ba'BBB'GydF4y2Ba,GydF4y2Ba'BB'GydF4y2Ba,GydF4y2Ba'B'GydF4y2Ba,GydF4y2Ba'CCC'GydF4y2Ba,GydF4y2Ba'd'GydF4y2Ba,GydF4y2Ba'NR'GydF4y2Ba})GydF4y2Ba
AAA AA A BBB BB乙CCC d NR AAA Inf文件-1.19 -1.74 -1.8 -1.81 -1.81 -1.81 -1.81 -1.81 AA Inf文件2.52 -1.16 -1.68 -1.75 -1.75 -1.76 -1.77 -1.77甲Inf文件3.31 2.07 -1.24-1.62 -1.66 -1.68 -1.68 -1.69 BBB Inf文件3.57 2.91 1.75 -1.18 -1.43 -1.49 -1.5 -1.52 BB Inf文件3.39 3.16 2.72 1.59 -0.89 -1.21 -1.26 -1.32乙Inf文件Inf文件3.28 2.82 2.54 1.55 -0.8 -0.95-1.19 CCC天道酬勤天道酬勤天道酬勤2.77 2.46 2.07 1.13 -0.25 -1.12GydF4y2Ba
信用质量阈值在如下图所示。在垂直轴上的区段代表转移概率,并且它们之间的界限确定横轴的临界值,通过标准的正态分布。在转移矩阵的每一行确定一组阈值。该图显示了阈值GydF4y2Ba'CCC'GydF4y2Ba评分。GydF4y2Ba
xliml = 5;xlimr = 5;一步= 0.1;x = xliml:步骤:xlimr;:thresCCC = thresholdMat(7日);centersY = (normcdf([thresCCC(2:end) xliml])+GydF4y2Ba...GydF4y2Banormcdf([xlimr thresCCC(2:结束)]))/ 2;标签= {GydF4y2Ba'AAA'GydF4y2Ba,GydF4y2Ba'AA'GydF4y2Ba,GydF4y2Ba'一个'GydF4y2Ba,GydF4y2Ba'BBB'GydF4y2Ba,GydF4y2Ba'BB'GydF4y2Ba,GydF4y2Ba'B'GydF4y2Ba,GydF4y2Ba'CCC'GydF4y2Ba,GydF4y2Ba'd'GydF4y2Ba,GydF4y2Ba'NR'GydF4y2Ba};图积(X,normcdf(x)的GydF4y2Ba'M'GydF4y2Ba,GydF4y2Ba'行宽'GydF4y2Ba1.5)GydF4y2Ba对于GydF4y2BaI = 2:长度(标签)= VAL thresCCC(ⅰ);线([VAL VAL],[0 normcdf(VAL)],GydF4y2Ba'的LineStyle'GydF4y2Ba,GydF4y2Ba':'GydF4y2Ba);线([X(1)VAL],[normcdf(VAL)normcdf(VAL)],GydF4y2Ba'的LineStyle'GydF4y2Ba,GydF4y2Ba':'GydF4y2Ba);GydF4y2Ba如果GydF4y2Ba(centersY第(i-1)-centersY(ⅰ))> 0.05文本(-4.5,centersY(i)中,标签{I});GydF4y2Ba结束GydF4y2Ba结束GydF4y2Baxlabel(GydF4y2Ba“信贷质量门槛”GydF4y2Ba)ylabel (GydF4y2Ba“累积概率”GydF4y2Ba)标题(GydF4y2Ba“{\bf信用质量阈值可视化}”GydF4y2Ba)图例(GydF4y2Ba“标准普通CDF”GydF4y2Ba,GydF4y2Ba“位置”GydF4y2Ba,GydF4y2Ba'E'GydF4y2Ba)GydF4y2Ba
向右或向左移动临界值会改变转移概率。例如,这里是将TTC阈值向右移动0.5得到的转换矩阵。注意违约概率增加了。GydF4y2Ba
shiftedThresholds = thresholdMat + 0.5;Example_DisplayTransitions(transprobfromthresholds(shiftedThresholds)GydF4y2Ba...GydF4y2Ba[],{GydF4y2Ba'AAA'GydF4y2Ba,GydF4y2Ba'AA'GydF4y2Ba,GydF4y2Ba'一个'GydF4y2Ba,GydF4y2Ba'BBB'GydF4y2Ba,GydF4y2Ba'BB'GydF4y2Ba,GydF4y2Ba'B'GydF4y2Ba,GydF4y2Ba'CCC'GydF4y2Ba},GydF4y2Ba...GydF4y2Ba{GydF4y2Ba'AAA'GydF4y2Ba,GydF4y2Ba'AA'GydF4y2Ba,GydF4y2Ba'一个'GydF4y2Ba,GydF4y2Ba'BBB'GydF4y2Ba,GydF4y2Ba'BB'GydF4y2Ba,GydF4y2Ba'B'GydF4y2Ba,GydF4y2Ba'CCC'GydF4y2Ba,GydF4y2Ba'd'GydF4y2Ba,GydF4y2Ba'NR'GydF4y2Ba})GydF4y2Ba
AAA AA A BBB BB乙CCC d NR AAA 75.34 13.84 1.05 0.19 0.13 0 0 0 9.45 AA 0.13 74.49 13.53 1.21 0.12 0.22 0.04 0.02 10.24 0.01 0.51 76.4 10.02 0.83 0.31 0.06 0.08 11.77 BBB 0 0.03 1.2 74.03 7.22 1.39 0.32 0.51 15.29 BB0 0.01 0.05 1.77 63.35 10.94 1.47 1.88 20.52 B 0,0.01 0.04 0.07 1.91 59.67 5.74 8.1 24.46 CCC 0 0 0.05 0.1 0.36 4.61 35.06 33.18 26.65GydF4y2Ba
给定特定PIT矩阵,在[6]和[8]的想法是改变移位参数施加到TTC阈值,使得所得到的转移矩阵是尽可能接近到PIT矩阵。接近程度作为对应转变概率之差的平方的总和进行测定。最优偏移值称为信用索引。信用索引用于分析样品中的每PIT转移矩阵来确定。GydF4y2Ba
这里我们使用GydF4y2BafminuncGydF4y2Ba从优化工具箱™找到信用指数。GydF4y2Ba
CreditIndex =零(nYears,1);ExitFlag =零(nYears,1);选项= optimset(GydF4y2Ba'大规模'GydF4y2Ba,GydF4y2Ba“关”GydF4y2Ba,GydF4y2Ba'显示'GydF4y2Ba,GydF4y2Ba“关”GydF4y2Ba);GydF4y2Ba对于GydF4y2Bai=1:nYears errorfun = @(z)norm(squeeze(TransMat(:,:,i))-GydF4y2Ba...GydF4y2Batransprobfromthresholds(GydF4y2Ba...GydF4y2Batransprobtothresholds(tmTTC)+ Z),GydF4y2Ba“回回”GydF4y2Ba);[CreditIndex(ⅰ),〜,ExitFlag(I)] = fminunc(errorfun,0,选项);GydF4y2Ba结束GydF4y2Ba
在一般情况下,人们期望较高的信用指数对应于风险较高的年。该系列信用指数的发现并不完全符合这种模式。有可能是这种不同的原因。首先,转移概率可以从他们以不同的方式,可能会导致混淆的单个参数影响试图捕捉这些差异,信用指数长期平均值偏离。具有IG和SG单独的信用指数,例如,可以帮助独立混杂影响。二,5个基点的差异可能是非常显著GydF4y2Ba'BBB'GydF4y2Ba违约率,但不能作为重要GydF4y2Ba'CCC'GydF4y2Ba违约率,但规范使用它们的权重相等。其他规范可以考虑。此外,它始终是一个好主意,检查优化求解器的出口标志,如果该算法无法找到解决的办法。在这里,我们得到有效的解决方案,每年万博 尤文图斯可为(全部退出标志GydF4y2Ba1GydF4y2Ba)。GydF4y2Ba
图图(年,CreditIndex,GydF4y2Ba'-d'GydF4y2Ba)举行GydF4y2Ba在GydF4y2BaExample_RecessionBands保持GydF4y2Ba离GydF4y2Ba格GydF4y2Ba在GydF4y2Baxlabel(GydF4y2Ba'年'GydF4y2Ba)ylabel (GydF4y2Ba'转移'GydF4y2Ba)标题(GydF4y2Ba'{\ BF信用指数}'GydF4y2Ba)GydF4y2Ba
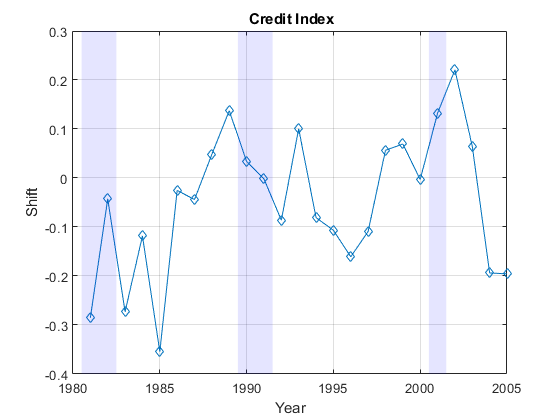
工作流上面可以适应工作与信贷系列指数的,而不是一系列的公司违约率。模型可以适合预测信用指数下一年,并预测转移矩阵可以推断,并用于风险分析。GydF4y2Ba
参考GydF4y2Ba
[1]奥特曼,E.,和E.霍奇基斯,GydF4y2Ba企业财务困境和破产GydF4y2Ba,第三版,新泽西州:威利财务,2006年。GydF4y2Ba
[2]巴塞尔银行监理委员会,“资本计量和资本标准的国际协议:修订框架”,国际清算银行(BIS),全面的版本,2006年6月可在:GydF4y2Bahttps://www.bis.org/publ/bcbsca.htmGydF4y2Ba.GydF4y2Ba
[3]巴塞尔银行监督委员会,“为合理的压力测试实践和监管原则 - 期末论文,”国际清算银行(BIS),2009年可日在:GydF4y2Bahttps://www.bis.org/publ/bcbs155.htmGydF4y2Ba.GydF4y2Ba
[4] FRED,圣路易斯联储,美联储经济数据库,GydF4y2Bahttps://research.stlouisfed.org/fred2/GydF4y2Ba.GydF4y2Ba
[5] Helwege,J.,和P.克莱曼,纽约联邦储备银行,目前在经济问题和金融,第2卷,6号,1996年5月“高收益债券,认识总违约率”。GydF4y2Ba
[6]吕弗勒,G。,和P. N. POSCH,GydF4y2Ba信用风险建模使用Excel和VBAGydF4y2Ba,西苏塞克斯,英格兰:威利金融,2007年。GydF4y2Ba
[7]国家经济研究局,经济研究,经济周期的扩张和收缩的国家局,GydF4y2Bahttps://www.nber.org/cycles/GydF4y2Ba.GydF4y2Ba
[8]大谷A.,S. Shiratsuka,R.鹤居,和T.山田,日本的“宏观压力测试对日本银行的贷款组合,”银行工作文件系列No.09-E-1,三月2009年。GydF4y2Ba
[9]专业预测,费城联邦储备银行调查,GydF4y2Bahttps://www.philadelphiafed.org/GydF4y2Ba.GydF4y2Ba
[10] Vazza,D,D极光和R.施内克,“2005年度全球企业违约研究与评级转变,”标准普尔全球固定收益研究,纽约,2006年1月。GydF4y2Ba
[11]威尔逊,T C., “组合信用风险,” FRBNY经济政策评论,1998年10月。GydF4y2Ba
选择网站GydF4y2Ba
选择一个网站,以获得翻译的内容,其中可看到当地的活动和优惠。根据您的位置,我们建议您选择:GydF4y2Ba.GydF4y2Ba
选择GydF4y2Ba网站GydF4y2Ba您还可以选择从下面的列表中的网站:GydF4y2Ba
美洲GydF4y2Ba
- 美洲拉丁GydF4y2Ba(西班牙语)GydF4y2Ba
- 加拿大GydF4y2Ba(英语)GydF4y2Ba
- 美国GydF4y2Ba(英语)GydF4y2Ba
欧洲GydF4y2Ba
- 比利时GydF4y2Ba(英语)GydF4y2Ba
- 丹麦GydF4y2Ba(英语)GydF4y2Ba
- 五金GydF4y2Ba(德语)GydF4y2Ba
- 西班牙GydF4y2Ba(西班牙语)GydF4y2Ba
- 芬兰GydF4y2Ba(英语)GydF4y2Ba
- 法国GydF4y2Ba(法语)GydF4y2Ba
- 爱尔兰GydF4y2Ba(英语)GydF4y2Ba
- 意大利GydF4y2Ba(意大利语)GydF4y2Ba
- 卢森堡GydF4y2Ba(英语)GydF4y2Ba
- 荷兰GydF4y2Ba(英语)GydF4y2Ba
- 挪威GydF4y2Ba(英语)GydF4y2Ba
- ÖsterreichGydF4y2Ba(德语)GydF4y2Ba
- 葡萄牙GydF4y2Ba(英语)GydF4y2Ba
- 瑞典GydF4y2Ba(英语)GydF4y2Ba
- 瑞士GydF4y2Ba
- 英国GydF4y2Ba(英语)GydF4y2Ba
亚太GydF4y2Ba
- 澳大利亚GydF4y2Ba(英语)GydF4y2Ba
- 印度GydF4y2Ba(英语)GydF4y2Ba
- 新西兰GydF4y2Ba(英语)GydF4y2Ba
- 中国GydF4y2Ba
- 日本GydF4y2Ba(日本语)GydF4y2Ba
- 한국GydF4y2Ba(한국어)GydF4y2Ba
