实现硬件高效的实突发矩阵求解
此示例演示如何使用嵌入Simulink®模型中的硬件高效MATLAB®代码求解方程组。本例中使用的模型适用于定点输入的HDL代码生成。该算法使用计算架构,在解算器算法的不同步骤中共享计算和内存单元。这在将定点算法部署到资源万博1manbetx受限的FPGA或ASIC设备时非常有用。虽然此解算器的吞吐量小于完全流水线实现,但它的片上占地面积也更小,因此适合于资源意识强的设计。
方程组的求解
任何线性方程组都可以用矩阵形式表示为

在哪里 是一个
是一个 -借-
-借- 已知数据的矩阵,
已知数据的矩阵, 是一个-未知量的乘-1向量,以及
是一个-未知量的乘-1向量,以及 是一个1的向量。
是一个1的向量。
一般来说,线性系统的求解最有效的方法是先将系统分解为下三角形式,然后通过反代换直接找到未知量。这种方法在数值上既稳定又高效。因此,它是嵌入式应用的良好选择。
任何矩阵可以分解为

在哪里 ,
, 是一个-借-上三角矩阵,以及
是一个-借-上三角矩阵,以及 是-借-恒等矩阵。这允许我们将方程组转换为上三角形式
是-借-恒等矩阵。这允许我们将方程组转换为上三角形式

该方程可通过反代换求解是是非奇异的。这种方法的一个好处是 不需要计算。相反,需要进行的转换来可同时应用于.这与前面的等式形式相同,内存和计算量更小。
不需要计算。相反,需要进行的转换来可同时应用于.这与前面的等式形式相同,内存和计算量更小。
CORDIC QR分解算法
QR分解通过一系列Givens旋转来执行。这些旋转使用坐标旋转数字计算机(CORDIC)技术在硬件中实现。有关CORDIC QR算法的详细说明,请参见示例使用CORDIC进行QR分解。.
硬件高效的不动点矩阵计算
使用QR分解的实突发矩阵求解支持二进制点比例定点数据的HDL代码生成。它的设计考虑了此应用程序万博1manbetx,并采用了特定于硬件的语义和优化。这些优化之一是资源共享。
当将复杂的算法部署到FPGA或ASIC设备上时,常常需要在计算的资源使用和总吞吐量之间进行权衡。虽然完全流水线和并行化的算法具有最大的吞吐量,但它们往往过于资源密集,无法部署在实际设备上。通过围绕一个或多个核心计算电路实现调度逻辑,可以在整个计算过程中重用资源。结果是实现了占用空间小得多的功能,尽管这是以总吞吐量为代价的。这通常是一个可接受的权衡,因为资源共享设计仍然可以满足总体延迟要求。
在整个计算生命周期中,使用QR分解求解实突发矩阵的所有关键计算单元都被重用。这不仅包括在QR分解过程中用于执行Givens旋转的CORDIC电路,还包括在后代换过程中使用的加法器和乘法器。这在部署到FPGA或ASIC设备时既节省了DSP资源,又节省了结构资源。
万博1manbetx支持的数据类型
在模拟中,支持单、双、二进制点缩放固定点和二进制点缩放双数据。但是,对于HDL代码生成,仅支持二进制点缩放固定点类型。万博1manbetx
实突发矩阵求解的参数
用矩阵QR分解求解实突发矩阵一个和B从模型或基工作空间来定义方程组来求解。它在掩码上接受四个输入参数:矩阵的行数一个和B,矩阵的列数一个,矩阵的列数B,以及输出数据类型。块掩码如下所示。
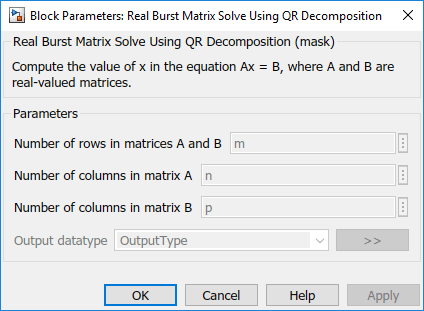
这些参数是由变量在工作区中定义的米,n,p和输出类型,分别。此外,该变量样本数需要在模型或基本工作空间中定义。
建立模型数据
首先,我们需要求解一系列方程组。现实世界的数据通常来自高斯集合,因此本例将使用从标准正态分布中提取的随机矩阵。标准正态分布的平均值为0,方差为1。其特性描述了许多(但不是全部)随机源正因为如此,我们将使用从该分布中提取的数据作为示例来演示如何使用QR分解来求解实突发矩阵。
首先,为正在求解的系统选择一个大小。
m=4;n=4;p=1;样本数=100;
接下来,生成随机的双精度数据。该数据被用作所需动态范围的数值基准。这对转换为固定点很有帮助。
A=randn(m,n,num_样本);B=randn(m,p,num_样本);
这里,前两个索引对应于每个样本中的矩阵索引,而第三个索引对应于样本编号A(1,2,3)对应于第三个示例的第一行和第二列中的元素。
生成浮点算术示例模型
在转换为定点之前,我们将用浮点算法对系统进行求解。然后,我们将使用从该模拟中获得的范围信息为模型的定点版本选择合适的输入和输出数据类型。
要生成模型的浮点版本,请使用下面的函数调用。
mdl=fixed.getMatrixSolveModel(A,B);
此函数用于在模型工作区中设置数据或 ,则必须修改模型工作区中的数据,或使用定点数据生成新模型。在本例后面,我们将使用后一种方法。
,则必须修改模型工作区中的数据,或使用定点数据生成新模型。在本例后面,我们将使用后一种方法。
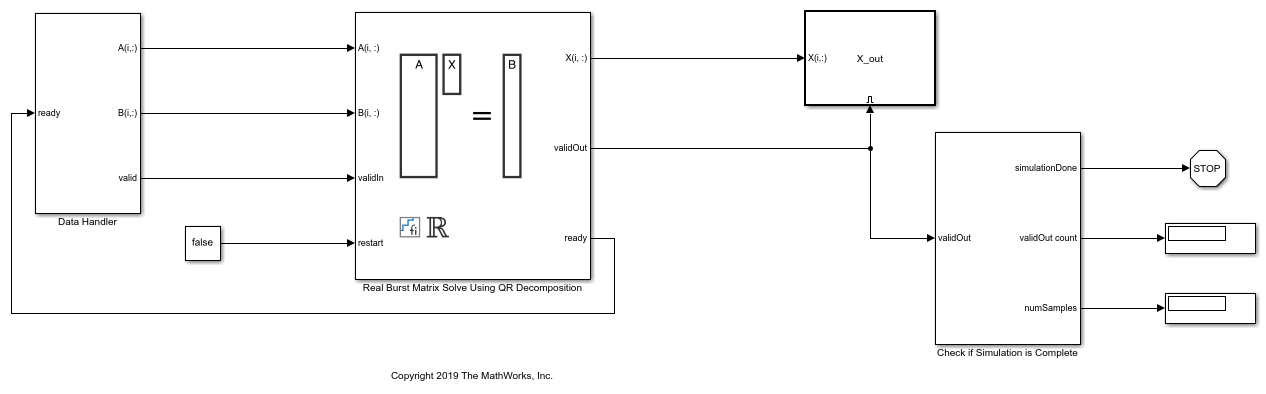
将数据从源传递到矩阵解算块
上述函数生成的模型已经配置为无需修改即可模拟。生成的模型使用名为Data Handler的块将数据发送给矩阵求解器。它通过监听矩阵解算器的就绪端口,并在就绪的上升边缘拉出validIn高电平来与矩阵解算器进行通信。这告诉Real Burst Matrix Solve using QR Decomposition,当前行的端口A(i,:)和B(i,:)是有效的。当ready和valid同时高时,这些端口的数据被视为矩阵的下一个有效行。
每当求解器看到ready和validIn都为真时,它就消耗端口A(i,:)和端口B(i,:)的数据输入。它必须保持有效,如果它想这样做的话。然后,使用QR分解的真实突发矩阵求解将保持这一行在缓冲区,直到它准备好处理它。该操作模式如下所示,其中消耗了两个样本。
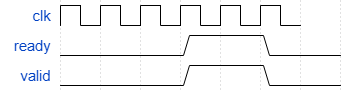
每当ready变大时,它可以消耗两行。如果发送了两行,Real Burst Matrix solving using QR Decomposition将第二行存储在一个内部缓冲区中。当断言ready时,并不是强制发送两行,如果因为validIn被取消断言而只发送了一个样本,ready将取消断言,只在计算需要更多数据时才重新断言。
请注意,在从ready到Data Handler的路径中,或在Data Handler到validIn的路径之间添加额外的延迟,都会增加预期不到的背压。在此场景中,将丢弃样本。我们建议您只在ready的前缘发送数据,或者不要在块和数据源之间插入额外的延迟。此外,如果您计划使用此块生成HDL代码,我们建议关闭管道优化,因为这会在这些路径上增加延迟。
模拟模型
要模拟模型,请单击“模拟”按钮或使用sim卡命令。
= sim (mdl);
处理输出
使用QR分解的实突发矩阵解算每次输出一行数据。每当块输出结果行时,它断言瓦利多特.在现场输出解决方案X_out在变量中出来。此数据仍存储为1-借-p-借-n*num_样本数组的行。在评估MATLAB®中解的精度之前,方便地将其转换为an-借-p-借-样本数这可以通过实用程序函数来完成matrixSolveOutputToMatrix.
X=矩阵SolveOutputToMatrix(out.X_out,n,p,num_样本);
在MATLAB®中计算预期解
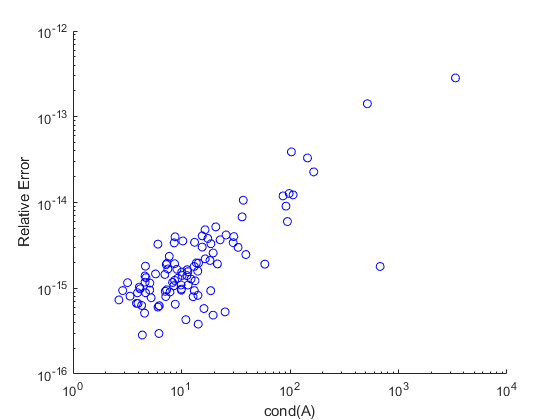
在我们的Simulink®模型中计算的解决方案的准确性可以很容易地在MATLAB®中计算。万博1manbetx注意,理论期望系统解的相对误差随矩阵的条件数而增加。为了看到这一点,我们将画出给出的误差

反条件数.
condNumber=零(1,num_样本);relativeError=零(1,num_样本);为idx=1:num_samples condNumber(idx)=cond(A(:,:,idx));relativeError(idx)=范数(B(:,:,idx)-A(:,,:,idx)*X(:,:,idx))/范数(B(:,:,idx));终止
策划的输出
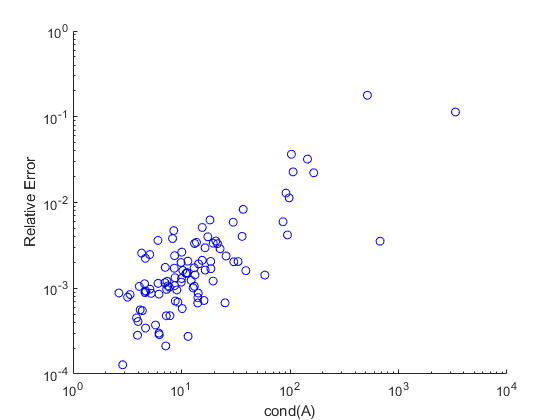
现在,绘制误差计算的输出。请注意,两个轴上都使用对数刻度,因为条件数和误差都跨越几个数量级。这两个值之间的正相关性在这里非常明显。
图(1);clf;h1 =轴();持有在;情节(condNumber relativeError,“波”); h1.XScale=“日志”; h1.YScale=“日志”; xlabel("条件(A)");ylabel (的相对误差);
制作模型的定点版本
上面模拟的双精度算法是相当精确的。在该设计的定点版本中保持高数值精度要求输入和输出数据类型足够大,以避免溢出,这可能由于QR分解或回代步骤中出现的幅度增长而发生。
选择输入数据类型
对于实突发QR分解,类型为R(我,:)是同类型的吗(我,:). 类似地,该类型的C(i,:)是同类型的吗B(i,:).这些类型在整个计算中使用。因此,输入数据类型需要容纳在每一个计算中可能需要的最大值R(我,:)和C(i,:).
在计算过程中,有两种影响会导致输入数据在数量上增长:元素在数量上的增长一个由于QR分解中使用的旋转的欧几里德范数保持性质,以及这些旋转的CORDIC实现的内在内部增长。这两种效应在数量上限制了输出元素
天花板(log2(1.65*sqrt(m)*最大值(abs(A)(:)))))
为R(我,:)和
装天花板(log2 (1.65 * sqrt (m) *马克斯(abs (B (:)))))
为C(i,:).在这个例子中,since一个和B根据相同的统计分布,我们给出了相同的字长和分数长度。一般来说一个和B不需要有相同的分数长度,只要它们有相同的单词长度。
maxumabsvalueindataset = max(max(abs(A(:)),max(abs(B(:)))) inputIntegerLength = cei2 (log2(1.65*sqrt(m)*maximumAbsValueInDataset)))
maximumAbsValueInDataset=3.5784输入长度=4
我们将使用18位字长类型作为输入。这可以更改以适应不同的应用程序。该变量输入类型下面计算对NumericType对象中的类型信息进行编码。
inputWordLength = 18 inputFractionLength = 18 - inputIntegerLength - 1 inputType = numerictype(1, inputWordLength, inputFractionLength)
inputWordLength=18 inputFractionLength=13 inputType=DataTypeMode:定点:二进制点缩放符号性:符号字长:18 FractionLength:13
有关CORDIC QR分解算法中增长边界的详细描述,请参见防止定点R溢出。
计算Back替换所需的动态范围
由于被小值除法,数据也可以在算法的后代部分增长。通过使用相关的输入数据进行模拟,可以做出良好的输出数据类型选择。对于这一步,输出值的大小X(我,:)以
1.65 * sqrt (m) *马克斯(abs (B (:))) / sigma_min,
在哪里西格玛_min是在所有样本矩阵中观察到的最小奇异值。这些值计算如下。
= 0 (1, num_samples);为idx=1:num_样本sigma(idx)=min(svd(A(:,:,idx));终止sigma_min = min(σ);backsubstituteWordlengthGrowth =装天花板(log2 (1.65 * sqrt (m) / sigma_min));
这将给出如下所示的输出数据类型
outputWordlength = inputWordLength + backsubstituteWordlengthGrowth outputFractionLength = inputFractionLength OutputType = numerictype(1, outputWordlength, outputFractionLength)
outputWordlength=30 outputFractionLength=13 OutputType=DataTypeMode:定点:二进制点缩放符号性:符号字长:30 FractionLength:13
创建模型的定点版本
要在定点进行模拟,首先将输入数据转换为计算的输入类型。
A_Fixed = fi(A, inputType);B_Fixed = fi(B, inputType);
通过更新变量,可以更新现有模型一个,B和输出类型在模型工作区中。但是,模型创建函数还可以选择创建具有指定输出类型的版本。
mdl_fi=fixed.getMatrixSolveModel(A_fixed,B_fixed,OutputType);

在定点模拟模型
out_fi = sim (mdl_fi);
将定点输出存储在MATLAB®阵列中
X_fi = matrixSolveOutputToMatrix (out_fi.X_out, n, p, num_samples);
在MATLAB®中计算预期解
由于我们已经从输入计算中知道了输入矩阵的条件数,所以我们可以利用这些值计算不动点解的相对误差。
relativeErrorFixedPoint=零(1,num_样本);为idx = 1: num_samples relativeErrorFixedPoint (idx) =标准(双(B_Fixed (:,:, idx) - A_Fixed (:,:, idx) * X_fi (:,:, idx)))。/规范(双(B_Fixed (:,:, idx)));终止
策划的输出
我们将再次绘制计算误差图,这次使用定点结果。注意,由于量化,这里的误差要大得多。
图(2);clf;h2=轴();持有在;绘图(条件编号、相对错误固定点、,“波”); h2.XScale=“日志”;h2。YScale =“日志”; xlabel("条件(A)");ylabel (的相对误差);
您还可以从以下列表中选择网站: