模糊与非模糊逻辑
基本小费问题
要说明模糊逻辑的值,请检查以下问题的线性和模糊方法:
尖端的适当金额是多少?
首先,通过传统的(非模糊的)方法解决这个问题,编写MATLAB®命令拼出线性和分段线性关系。然后,用模糊逻辑看看相同的系统。
基本的提示问题。给定一个从0到10的数字代表一家餐馆的服务质量(10非常棒),小费应该是多少?
这个问题是基于给小费,因为这在美国是典型的做法。在美国,一顿饭平均要付15%的小费,不过实际金额会根据服务质量的不同而有所不同。
Nonfuzzy方法
从最简单的关系开始。假设小费总是帐单总额的15%。
服务= 0:.5:10;提示= 0.15 * 1(大小(服务));情节(服务,小费)包含(“服务”)ylabel('小费')ylim([0.05 0.25])
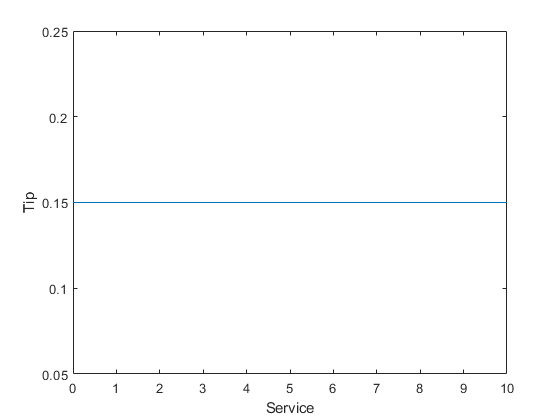
这种关系不考虑服务的质量,因此您必须向等式添加一个术语。由于服务从0到10的等级额定评估,因此如果服务非常好,则尖端从5%线性增加。现在关系看起来像以下情节:
提示=(.20/10)*服务+ 0.05;情节(服务,小费)包含(“服务”)ylabel('小费')ylim([0.05 0.25])

这个公式和你想要的一样,很直接。然而,你可能也想要这个小贴士反映出食物的质量。这个问题的扩展定义如下。
扩展问题。给定从0到10的两组数字(10很好),这两组数字分别代表一家餐馆的服务质量和食物质量,小费应该是多少?
现在您添加了另一个变量,看看该公式是如何受到影响的。
食物= 0:.5:10;[F、S] = meshgrid(食品、服务);提示=(0.20/20)。* (S + F) + 0.05;冲浪(年代,F,小费)包含(“服务”)ylabel(“食物”) zlabel ('小费')

在这种情况下,结果看起来令人满意,但当你仔细看他们,他们似乎不正确。假设你想让服务成为比食物质量更重要的因素。明确服务占总小费等级的80%,食物占其余的20%。
servRatio = 0.8;提示= Servratio *(0.20 / 10 * s + 0.05)+...(1-servRatio) * (0.20/10 * F + 0.05);冲浪(年代,F,小费)包含(“服务”)ylabel(“食物”) zlabel ('小费')
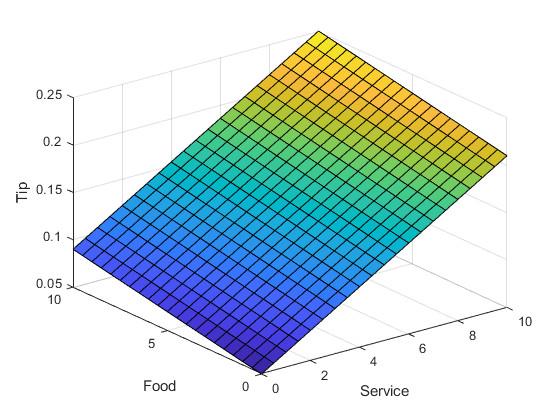
响应仍然是一致线性的。假设你想在中间得到更多平平的反馈,也就是说,你一般想给15%的小费,但如果服务特别好或特别差,你还想指定一个变化。反过来,这个因素意味着以前的线性映射不再适用。您仍然可以使用分段线性结构的线性计算。现在,回到只考虑服务的一维问题。您可以使用逻辑索引创建简单的条件提示赋值。
提示= 0(大小(服务));提示(服务< 3)=(0.10 / 3)*服务(服务< 3)+ 0.05;Tip(服务>=3 &服务<7)= 0.15;Tip (service>=7 & service<=10) =...(0.10 / 3)*(服务(服务> = 7&Service <= 10)-7)+0.15;情节(服务,小费)包含(“服务”)ylabel('小费')ylim([0.05 0.25])
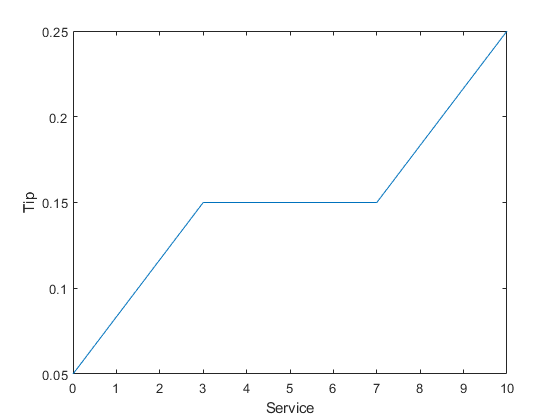
假设您将这种方法扩展到两个维度,在这里您将再次考虑食品质量。
servRatio = 0.8;提示= 0(大小(S));tip(S<3) = ((0.10/3)*S(S<3)+0.05)*servRatio +...(1-servRatio) * (0.20/10 * F (S < 3) + 0.05);提示(S>=3 & S<7) = (0.15)*servRatio +...(1-servRatio) * (0.20/10 * F(> = 3 &年代< 7)+ 0.05);提示(> = 7 &年代< = 10)= ((0.10 / 3)* (S(> = 7 &年代< = 10)7)+ 0.15)* servRatio +...(1-servRatio) * (0.20/10 * F(> = 7 &年代< = 10)+ 0.05);冲浪(年代,F,小费)包含(“服务”)ylabel(“食物”) zlabel ('小费')
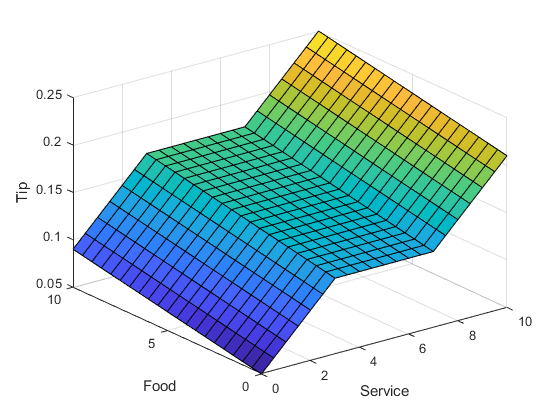
情节看起来不错,但功能却出奇的复杂。对于没有看到原始设计过程的人来说,这个算法是如何工作的甚至是不明显的。
模糊逻辑方法
一般来说,您希望捕获这个问题的本质,而不考虑所有可能是任意的因素。如果您列出了在这个问题中真正重要的东西,您最终可能会得到以下规则描述。
小费问题规则-服务因素
如果服务很差,那么小费就很便宜
如果服务很好,那么小费是平均的
如果服务非常好,那么提示很大
这里列出规则的顺序是任意的。先有哪些规则并不重要。为了包括食物质量对小费的影响,添加以下两条规则。
小费问题规则-食物因素
如果食物变质了,小费就便宜了
如果食物很美味,那么提示很慷慨
您可以像这样将两个不同的规则列表组合成一个由三个规则组成的列表。
小费问题规则-服务和食物因素
如果服务很差或者食物变质了,那么小费就很便宜
如果服务很好,那么小费是平均的
如果服务很好或食物很美味,那么小费是慷慨的
这三个规则是您解决方案的核心,它们对应于模糊逻辑系统的规则。当您向语言变量提供数学意义(例如,平均尖端),您有一个完整的模糊推理系统。模糊逻辑的方法也必须考虑:
这些规则是如何组合在一起的?
我如何从数学上定义平均小费是多少?
问题解决方案
下面的图代表了解决引爆问题的模糊逻辑系统。
gensurf (readfis (“蒂珀”))
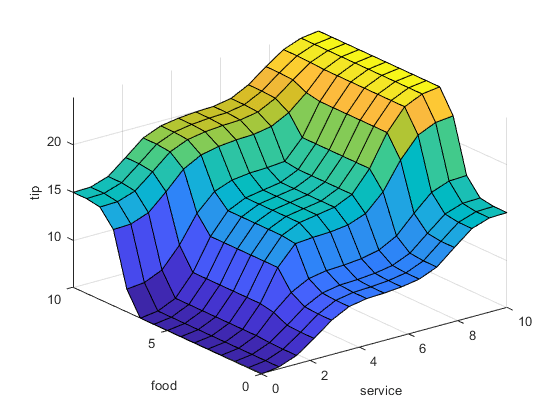
这幅图是由同时考虑服务和食物因素的三个规则生成的。
观察考虑到目前为止关于这个例子的一些观察。你找到了一个分段线性关系来解决这个问题。它是有效的,但它的推导是有问题的,当你把它写成代码时,它是不容易解释的。相反,模糊逻辑系统是基于一些常识陈述。此外,还可以向列表中添加另外两条规则,它们会影响总体输出的形状,而不需要撤销已经完成的操作。
此外,通过使用模糊逻辑规则,算法的结构维护解耦沿着相当清晰的线。每一天、每一个城市、每一个国家的平均小费的概念是不同的。然而,基本的逻辑是一样的:如果服务很好,小费应该是平均的。
调整的方法您可以通过简单地移动定义平均值的模糊集来快速地重新校准该方法,而无需重写模糊逻辑规则。
您可以移动分段线性函数的列表,但有更大的可能性难以重新校准。
在下面的例子中,我们重写了分段线性倾翻问题,使其更具有一般性。它执行与以前相同的功能,只是现在常量可以很容易地改变。
Lowtip = 0.05;AVERIP = 0.15;hightip = 0.25;tipreange = hightip-lowtip;badservice = 0;okayservice = 3;商假= 7;伟大的服务= 10;servicerange = gervservice-badservice;Badfood = 0; greatFood = 10; foodRange = greatFood-badFood;%如果服务是穷人或食物是腐臭的,提示很便宜如果service< service tip = ((((averTip-lowTip)/((冈service - badservice)))...* * servRatio +服务+ lowTip)...(1-servRatio) * (tipRange / foodRange *食品+ lowTip);如果服务好,小费是一般的elseifservice...(tipRange / foodRange *食物+ lowTip);如果服务很好或食物很美味,小费是慷慨的其他的= (((highTip-averTip) /...(greatService-goodService)) *...(Service-MoodyService)+ AVERTIP)* SERVRATIO +...(1-servRatio) * (tipRange / foodRange *食品+ lowTip);结束
与所有代码一样,引入的通用性越强,算法就越不精确。您可以通过添加更多注释来提高清晰度,或者以更明显的方式重写算法。但是,分段线性方法并不是解决这一问题的最佳方法。
如果你从算法中除去除了三条注释之外的所有东西,剩下的就是你之前写下的模糊逻辑规则。
如果服务很差或食物腐臭,小费就很便宜
如果服务好,小费就一般
如果服务是优秀的或食物很美味,提示很慷慨
模糊逻辑使用对您清晰的语言以及计算机对计算机有意义,这就是为什么它是弥合人与机器之间的差距的成功技术。
通过使方程尽可能的简单(线性),你使事情对机器来说更简单,但对你来说更复杂。然而,限制不再是计算机-它是你的心智模式的计算机正在做什么。模糊逻辑让机器按照您的偏好工作,而不是相反。
相关话题
你也可以从以下列表中选择一个网站:
