基于减法聚类的郊区通勤模型
此示例演示如何使用根菲斯功能。人口和出行数据来自特拉华州纽卡斯尔县的100个交通分析区。考虑了五个人口因素:人口、居住单元数量、车辆所有权、家庭收入中值和总就业。因此,该模型有五个输入变量和一个输出变量。
加载并绘制数据。
mytripdata子批次(2,1,1)绘图(datin)ylabel(“输入”)子地块(2,1,2)绘图(datout)标签(“输出”)
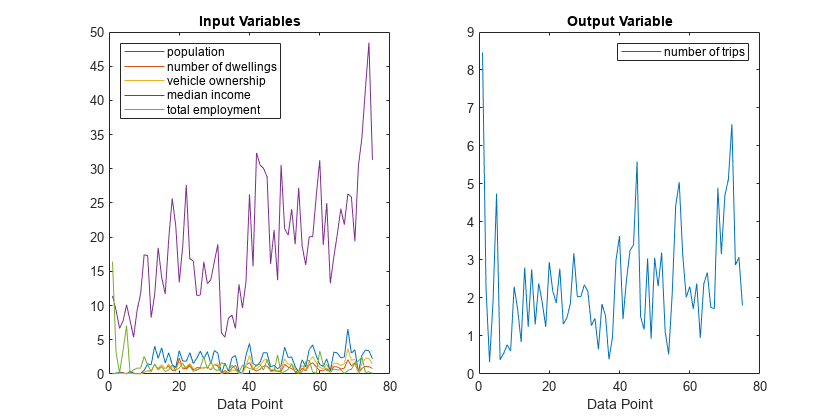
这个mytripdata命令在工作区中创建多个变量。在最初的100个数据点中,使用75个数据点作为训练数据(达汀和数据)和25个数据点作为检查数据(以及验证模型的测试数据)。检查数据输入/输出对变量为chkdatin和奇达图.
使用根菲斯命令
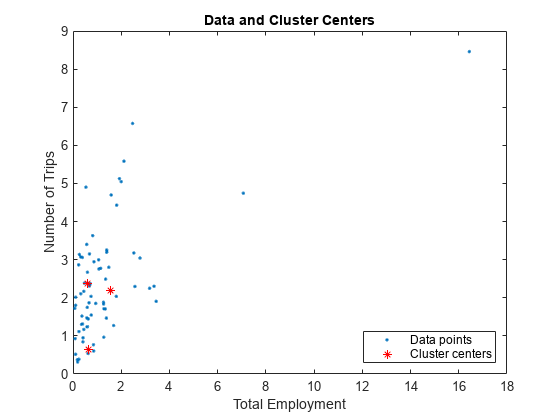
首先,创建一个Genfis选项用于减法聚类的选项集,指定群集影响范围范围属性群集影响范围属性表示当将数据空间看作单位超立方体时,簇的影响范围。指定小簇半径通常会在数据中产生许多小簇,并产生许多规则。指定大的簇半径通常会在数据中产生几个大的簇,并导致较少的规则。
opt=genfis选项(“减法聚类”,“ClusterInfluenceRange”,0.5);
使用培训数据和指定选项生成FIS模型。
fismat=genfis(datin、datout、opt);
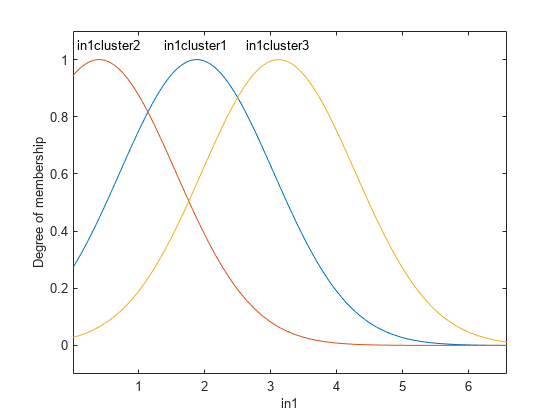
这个根菲斯命令使用不执行任何迭代优化的一次传递方法。生成的FIS对象的模型类型是具有三条规则的一阶Sugeno模型。
验证模型。在这里,trnRMSE是由训练数据生成的系统的均方根误差。
fuzout=评估值(fismat,datin);trnRMSE=标准(引信输出数据)/sqrt(长度(引信输出))
trnRMSE=0.5276
接下来,将测试数据应用于FIS以验证模型。在本例中,验证数据用于检查和测试FIS参数。此处,chkRMSE是由验证数据生成的系统的均方根误差。
chkfuzout=评估值(fismat,chkdatin);chkRMSE=标准值(chkfuzout chkdatout)/sqrt(长度(chkfuzout))
chkRMSE=0.6179
绘制模型的输出,chkfuzout,对照验证数据,奇达图.
图2:图(chkdatout)保持在…上绘图(chkfuzout,“哦”)持有关
模型输出和验证数据分别显示为圆圈和蓝色实线。图中显示模型在验证数据上表现不佳。
此时,您可以使用自适应神经模糊推理系统改进模型。首先,尝试在不使用验证数据的情况下使用相对较短的训练周期(20个时期),然后根据测试数据测试生成的FIS模型。
anfisOpt=anfisOptions(“InitialFIS”,菲斯马特,“EpochNumber”,20,...“初始步长”裂隙2=anfis([datin-Datut],anfisOpt);
ANFIS信息:节点数:44个线性参数数:18个非线性参数数:30个参数总数:48个训练数据对数:75个检查数据对数:0个模糊规则数:3个开始训练ANFIS…1 0.527607 2 0.513727 3 0.492996 4 0.499985 5 0.490585 6 0.492924 7 0.48733步长减小到0.0第7纪元后90000.80.485036 9 0.480813 10 0.475097步长在第10纪元后增加到0.099000.11 0.469759 12 0.462516 13 0.451177 14 0.447856步长在第14纪元后增加到0.108900.15 0.444356 16 0.433904 17 0.433739 18 0.420408步长在第18纪元后增加到0.119790.19 0.420512 20 0.420275指定纪元数达到d-->ANFIS训练在第20纪元完成。最小训练RMSE=0.420275
培训完成后,验证模型。
fuzout2=评估值(fismat2,datin);trnRMSE2=标准值(fuzout2 datout)/sqrt(长度(fuzout2))
trnRMSE2=0.4203
chkfuzout2=评估值(fismat2,chkdatin);chkRMSE2=标准值(chkfuzout2 chkdatout)/sqrt(长度(chkfuzout2))
chkRMSE2=0.5894
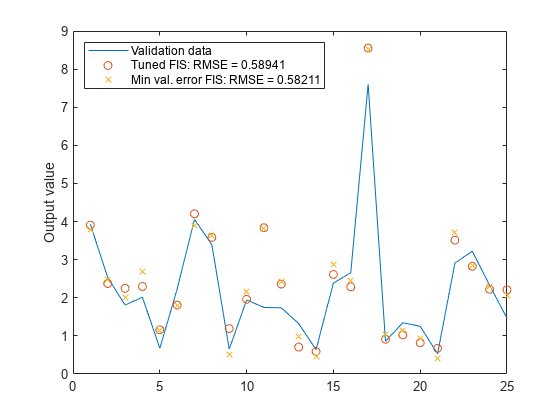
该模型在训练数据方面有了很大的改进,但在验证数据方面只有一点点改进。绘制使用以下方法获得的改进模型输出:自适应神经模糊推理系统对照测试数据。
图2:图(chkdatout)保持在…上地块(chkfuzout2,“哦”)持有关
模型输出和验证数据分别显示为圆形和蓝色实线。该图显示了具有根菲斯可以用作从数据生成模糊模型的独立、快速方法,也可以用作确定初始规则的预处理器自适应神经模糊推理系统训练使用聚类方法查找规则的一个重要优点是,与未经聚类生成的FIS相比,生成的规则更适合输入数据。这一结果减少了当输入数据具有高维时规则过度传播的问题。
当检查错误开始增加而训练错误继续减少时,可以检测到过度拟合。
要检查模型是否过度安装,请使用自适应神经模糊推理系统使用验证数据对模型进行200个时代的训练。
首先,通过修改现有的ANFIS培训选项来配置ANFIS培训选项安菲斯顿选项集。指定历元数和验证数据。由于训练历元数较大,因此禁止在命令窗口显示训练信息。
anfisOpt.EpochNumber=200;anfisOpt.ValidationData=[chkdatin chkdatout];anfisOpt.DisplayANFISInformation=0;anfisOpt.DisplayErrorValues=0;anfisOpt.DisplayStepSize=0;anfisOpt.DisplayFinalResults=0;
培训金融机构。
[fismat3,trnErr,步长,fismat4,chkErr]=anfis([datin Datut],anfisOpt);
在这里
第3节是训练误差达到最小值时的FIS对象。第四节验证数据错误达到最小值时的快照FIS对象。步长是训练步长的历史记录。trnErrRMSE是否使用培训数据切克尔是使用每个训练历元的验证数据的RMSE。
培训完成后,验证模型。
fuzout4=评估值(fismat4,datin);trnRMSE4=标准值(fuzout4 datout)/sqrt(长度(fuzout4))
trnRMSE4=0.3393
CHKfuzut4=评估值(fismat4,chkdatin);chkRMSE4=标准(chkfuzout4 chkdatout)/sqrt(长度(chkfuzout4))
chkRMSE4=0.5834
训练数据的误差是迄今为止最低的,验证数据的误差也比以前略低。这一结果表明可能存在过度拟合,当模糊系统与训练数据拟合得如此之好,以至于无法很好地拟合验证数据时,就会出现这种情况。结果是失去了通用性。
查看改进的模型输出。根据检查数据绘制模型输出。
图2:图(chkdatout)保持在…上地块(chkfuzout4,“哦”)持有关

模型输出和验证数据分别显示为圆形和蓝色实线。
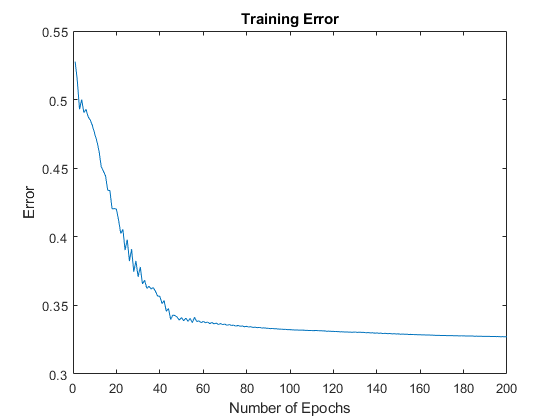
接下来,绘制训练错误,trnErr.
图形绘图(trnErr)标题(“训练错误”)xlabel(“纪元数”)伊拉贝尔(“训练错误”)

该图显示,训练误差大约在第60个历元点处稳定下来。
绘制检查错误,切克尔.
地物图(chkErr)标题(“检查错误”)xlabel(“纪元数”)伊拉贝尔(“检查错误”)
图中显示,验证数据误差的最小值出现在第52个历元。在这一点之后,即使在自适应神经模糊推理系统一直到第200个历元,都将训练数据的误差降至最低。根据指定的误差容限,该图还表明模型概括测试数据的能力。
您还可以比较第二节和fistmat4根据验证数据,奇达图.
图2:图(chkdatout)保持在…上地块(chkfuzout4,“ob”)地块(chkfuzout2,“+r”)
另见
相关话题
您还可以从以下列表中选择网站:
