使用减法聚类建模交通模式
这个例子展示了如何使用减法聚类来基于区域的人口统计数据对区域的交通模式进行建模。
问题:理解交通模式
在这个例子中,我们试图理解从一个地区产生的汽车出行数量和该地区的人口统计学之间的关系。人口统计和出行数据收集自特拉华州纽卡斯尔县的交通分析区。我们考虑了五个人口因素:人口、居住单元数量、车辆拥有量、家庭收入中位数和总就业人数。
在此,人口因素将作为输入处理,而产生的行程将作为输出处理。因此,我们的问题有5个输入变量(5个人口统计因素)和1个输出变量(产生的出行次数)。
数据
将本示例中使用的输入和输出变量加载到工作区中。
tripdata
在工作区中加载了两个变量,达汀和datout.达汀有5列表示5个输入变量和datout有一列表示1个输出变量。
子地块(2,1,1)地块(大田)图例(“人口”,“住宅单位数目”,“车辆所有权”,...‘家庭收入中位数’,“总就业”)头衔(输入变量的,“字体大小”,10)子地块(2,1,2)绘图(datout)图例(“旅行的num”)头衔(输出变量的,“字体大小”, 10)

图1:输入和输出变量
行数达汀和datout, 75,表示可用的观察、样本或数据点的数量。一行在达汀,例如第11行,由5个输入变量(人口、居住单元数量、车辆拥有量、家庭收入中位数和总就业)和相应的第11行的观测值组成datout表示给定输入变量的观测结果所产生的行程数的观测值。
我们将首先对数据进行聚类,以建立输入变量(人口统计)和输出变量(旅行)之间的关系模型。然后,聚类中心将被用作定义模糊推理系统(FIS)的基础,该系统可用于探索和理解交通模式。
为什么是聚类和模糊逻辑?
聚类是一种非常有效的技术,可以从大型数据集中识别数据中的自然分组,从而可以简洁地表示数据中嵌入的关系。在本例中,集群允许我们将流量模式分为广泛的类别,因此更易于理解。
模糊逻辑是处理不精确的有效范式。它可以用来对输入进行模糊或不精确的观察,而对输出却得到清晰而精确的值。此外,模糊推理系统是一种不使用复杂的解析方程来构建系统的方法。
在本例中,模糊逻辑用于捕获在聚类到模糊推理系统(FIS)期间识别的广泛类别。然后,FIS将作为一个模型,反映人口统计和汽车旅行之间的关系。
聚类和模糊逻辑一起提供了一种简单而强大的方法来建模我们想要研究的流量关系。
集群的数据
subclust是实现了一种称为减法集群的集群技术的函数。[1]是一种快速、一次性的聚类算法,用于估计数据集中的聚类数量和聚类中心。
在本节中,我们将看到如何在数据集上执行减法聚类,在下一节中,我们将独立探索如何使用聚类来构建模糊推理系统(FIS)。
[C,S]=亚群([datin-datut],0.5);
的第一个参数subclust函数是要聚集的数据。函数的第二个参数是半径它标记了簇在中的影响半径输入空间.
变量C现在拥有所有被识别的星团中心subclust.每一行的C包含集群的位置。
C
C=1.8770 0.7630 0.9170 18.7500 1.5650 2.1830 0.3980 0.1510.1320 8.1590 0.6250 0.6480 3.1160 1.1930 1.4870 19.7330 0.6030 2.3850
在这种情况下,C有3行表示3个簇,6列表示簇在每个维度中的位置。
subclust因此,在正在考虑的人口统计旅行数据集中确定了3个自然分组。下图显示了集群是如何在输入空间的“总就业”和“旅行”维度中确定的。
clf图(datin(:,5),datout(:,1),“。”C (:, 5), C (:, 6),“r*”)传说(“数据点”,“集群中心”,“位置”,‘东南’)包含(“总就业”,“字体大小”(10) ylabel“旅行的num”,“字体大小”10)标题(“输入空间中选定的两个维度的数据和集群”,“字体大小”, 10)

图2:输入空间“总就业”和“出行”维度中的集群中心
变量年代包含指定集群中心在每个数据维中的影响范围的西格玛值。所有的集群中心共享相同的西格玛值。
年代
S = 1.1621 0.4117 0.6555 7.6139 2.8931 1.4395
年代在本例中,有6列表示集群中心对每个维度的影响。
模糊推理系统(FIS)的生成
根菲斯是使用减法集群创建FIS的函数。根菲斯雇用subclust在后台对数据进行聚类,并使用聚类中心及其影响范围构建FIS,然后使用该FIS来探索和理解流量模式。
datout myfis = genfis(数据输入器,...Genfis选项(“SubtractiveClustering”,“ClusterInfluenceRange”, 0.5));
第一个参数是输入变量矩阵达汀,第二个参数是输出变量矩阵datout第三个论点是半径应在使用时使用subclust.
根菲斯为输入、输出和成员函数指定默认名称。对于我们的理解,有意义地重命名输入和输出是有益的。
为输入和输出分配名称。
myfis.Inputs(1).名称=“人口”;myfis.Inputs(2)。Name =“住宅单位”;myfis.Inputs(3)。Name =“num工具”;myfis.Inputs(4)。Name =“收入”;myfis.输入(5).名称=“就业”;myfis.Outputs(1)。Name =“行程数”;
理解cluster - fis关系
FIS由输入、输出和规则组成。每个输入和输出可以有任意数量的成员函数。这些规则规定了基于输入、输出和隶属函数的模糊系统的行为。根菲斯构建FIS,试图捕获每个集群在输入空间中的位置和影响。
myfis是FIS吗根菲斯已生成。由于数据集有5个输入变量和1个输出变量,根菲斯构造具有5个输入和1个输出的FIS。每个输入和输出具有与集群数量相同的成员函数subclust已经确定了。如前所述,对于当前数据集subclust确定了3个簇。因此,每个输入和输出将由3个成员函数表示。此外,规则的数量等于簇的数量,因此创建了3个规则。
我们现在可以探测FIS,以了解集群如何使用Fuzzy Logic Designer应用程序在内部转换为成员函数和规则。
fuzzyLogicDesigner (myfis)

图3:构建模糊推理系统(FIS)的图形编辑器
可以看出,FIS有5个输入和1个输出,输入通过规则库映射到输出(图中的白色框)。
现在让我们来分析集群中心和成员函数是如何关联的。
mfedit (myfis)

图4:图形化成员函数编辑器
mfedit (myfis)启动图形成员资格函数编辑器。也可以通过单击由启动的FIS编辑器中的输入或输出来启动该编辑器fuzzyLogicDesigner.
请注意,所有输入和输出正好有3个成员函数。3个成员函数表示由subclust.
FIS中的每个输入表示输入数据集中的一个输入变量达汀FIS中的每个输出表示输出数据集中的一个输出变量datout.
默认情况下,第一个成员函数,in1cluster1,第一个输入人口将在成员函数编辑器中选择。注意,成员函数类型为高斯型(高斯型隶属函数),隶属函数的参数为(1.162 - 1.877),在那里1.162表示高斯曲线的扩散系数,以及1.877表示高斯曲线的中心。in1cluster1捕获输入变量的第一个簇的位置和影响人口.(C(1,1)=1.877,S(1)=1.1621)
同样,输入变量的其他2个簇的位置和影响人口被其他两个成员函数捕获in1cluster2和in1cluster3.
其余4个输入遵循精确的模式,模拟3个集群在数据集中各自维度上的位置和影响。
现在,让我们探讨一下模糊规则是如何构建的。
ruleedit (myfis)

图5:图形化规则编辑器
ruleedit是图形模糊规则编辑器。正如你所注意到的,有三条规则。每个规则都试图将输入空间中的集群映射到输出空间中的集群。
第一条规则可以简单地解释如下。如果输入到FIS,人口,住宅单位,num车辆,收入和就业,强烈属于各自的cluster1成员函数,然后输出,num的旅行,必须强烈地属于其cluster1隶属函数。规则末尾的(1)表示规则的权重或重要性为“1”。权重可以取0到1之间的任何值。权重较小的规则在最终输出中的计算量较小。
该规则的意义在于,它简单地将输入空间中的聚类1映射到输出空间中的聚类1。类似地,其他两个规则将输入空间中的集群2和集群3映射到输出空间中的集群2和集群3。
如果一个更接近第一个集群的数据点,或者换句话说,具有第一个集群的强成员关系,作为输入myfis然后规则1将发射更多发射强度类似地,对第二个集群具有强成员身份的输入将触发第二个规则,其触发强度将高于其他两个规则,依此类推。
然后使用规则的输出(发射强度)通过输出成员函数生成FIS的输出。
FIS的一个输出,num的旅行,有3个线性隶属函数表示由subclust.线性隶属函数的系数并不是直接从聚类中心取的。相反,它们是使用最小二乘估计技术从数据集估计的。
在这种情况下,所有3个成员函数的形式如下a*人口+b*居住单元+c*车辆数量+d*收入+e*就业+f,在那里一个,b,c,d,e和f表示线性隶属函数的系数。单击num的旅行隶属函数编辑器中的隶属函数,以观察这些线性隶属函数的参数。
使用FIS进行数据探索
您现在可以使用已经构造好的FIS来理解建模关系的底层动态。
surfview(myfis)

图6:输入-输出表面查看器
surfview是帮助查看模糊系统的输入-输出曲面的曲面查看器。换句话说,该工具模拟了模糊系统对整个输入范围的响应,该系统被配置为工作。之后,FIS对输入的输出或响应被作为一个曲面绘制在输入上。这种可视化非常有助于理解系统在输入空间的整个范围内的行为。
在上面的绘图中,曲面查看器显示两个输入的输出曲面人口和居住单元数.你可以看到,随着人口和居住单元的增加,汽车出行的数量也在增加,这听起来非常合理。您可以更改X和Y下拉框中的输入,以根据您选择的输入观察输出面。
ruleview (myfis)
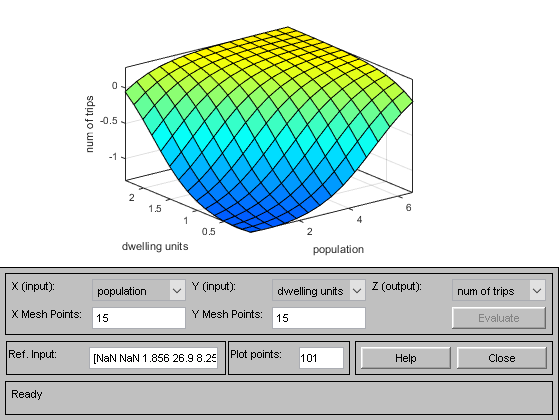
图7:规则查看器,模拟整个模糊推理过程
ruleview是一个图形模拟器,用于模拟FIS对输入变量特定值的响应。现在,建立了模糊系统,如果我们想了解一个人口统计设置(例如具有特定人口的区域、一定数量的住宅单元等)的出行次数,该工具将帮助您模拟FIS响应nse供您选择输入。
这个GUI工具的另一个特性是,它为您提供了整个模糊推理过程的快照,从如何满足每个规则中的成员函数到如何生成最终输出解模糊.
结论
这个例子试图说明如何将聚类和模糊逻辑作为有效的数据建模和分析技术来使用。
模糊逻辑在其他技术领域也有广泛的应用,如非线性控制、自动控制、信号处理、系统识别、模式识别、时间序列预测、数据挖掘、金融应用等。
参考
[1] -S.Chiu,“基于聚类估计的模糊模型识别,”智能与模糊系统, 1994年第2卷第3期。
另请参阅
相关的话题
您还可以从以下列表中选择网站:
