使用外部存储器执行矩阵运算
这个例子展示了如何生成一个高密度脂蛋白与AXI4主接口IP核,在高密度脂蛋白IP核心执行矩阵乘法,输出结果写入DDR内存。
在你开始之前
要运行这个示例,您必须安装以下软件和硬件和设置:
Xilinx®Vivado®设计套件,支持版本中列出万博1manbetxHDL语言支持,支持第三方万博1manbetx工具和硬件。
Xilinx Zynq®ZC706评估工具
高密度脂蛋白编码器™X万博1manbetxilinx Zynq平台支持包
高密度脂蛋白校验™Xilin万博1manbetxx FPGA板支持包
这个例子也可以运行在Xilinx Zynq Ultrascale + MPSoC ZCU102评估工具
介绍
在本例中,您:
生成一个高密度脂蛋白与AXI4主接口IP核。
从外部访问大型矩阵DDR3内存Xilinx Zynq ZC706董事会使用AXI4主界面。
执行矩阵向量乘法的HDL IP核心和输出结果写回DDR内存使用AXI4主界面。
这个例子也可以运行在Xilinx Zynq Ultrascale + MPSoC ZCU102评价工具,来访问外部DDR4记忆。
这个示例模型矩阵向量乘法算法并实现了算法在Xilinx Zynq FPGA板上。大型矩阵可能不会有效地映射到块FPGA结构上公羊。相反,我们可以将矩阵存储在外部DDR内存FPGA板上。AXI4主界面可以通过与供应商提供的内存访问数据和DDR内存接口IP核接口。此功能使您能够模型算法,包括大型数据处理和需要高通量DDR访问,如矩阵运算,计算机视觉算法,等等。
矩阵向量乘法模块支持定点矩阵向量乘法,矩阵与一个可配置的大小从2到4000。万博1manbetx矩阵的大小是通过AXI4访问运行时配置寄存器。
modelname =“hdlcoder_external_memory”;open_system (modelname);
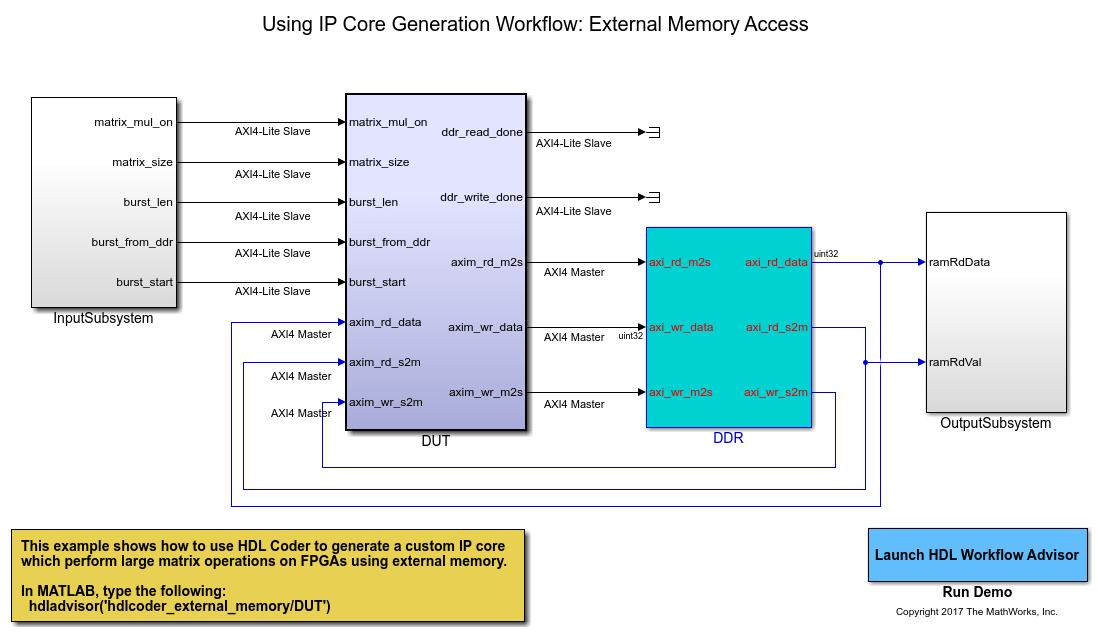
模型算法使用AXI4主协议
这个示例模型包括FPGA实现DUT测试(设计)块,DDR功能行为块和测试环境来驱动输入和验证预期的输出。
的DUT子系统包含AXI4主读/写控制器模块和矩阵向量乘法。使用AXI4主界面DUT子系统从外部DDR内存读取数据,给数据Matrix_Vector_Multiplication模块,然后写入输出数据到外部DDR内存使用AXI4主界面。的DUT模块也有几个参数港口。这些端口会被映射到AXI4-Lite访问寄存器,所以您可以调整这些参数从MATLAB®,即使你在FPGA设计实现。
的DDR在仿真环境中模块代表了外部DDR内存。之间的接口DUT和DDR模块简化AXI4主协议。
端口的参数之一matrix_mul_on控制是否运行Matrix_Vector_Multiplication模块。当输入matrix_mul_on是真的,DUT上面描述的子系统执行矩阵向量乘法。当输入matrix_mul_on是假的,DUT子系统执行数据回环模式。在这种模式下,DUT子系统从外部DDR内存读取数据,把它写进Internal_Memory模块,然后写相同的数据返回到外部DDR内存。数据回环模式是一个简单的方法来验证的功能AXI4掌握外部DDR内存访问。
open_system (“hdlcoder_external_memory / DUT”);

在DUT子系统,DDR_Access模块模型简化AXI4主协议,并使用它在DDR读取和写入数据。在IP核心代工作流,高密度脂蛋白编码器将生成简化之间的翻译AXI4主协议和实际AXI4主协议在生成的HDL IP核心。简化AXI4主协议上的更多信息,参见模型设计AXI4主界面的一代。
还在DUT子系统,Matrix_Vector_Multiplication模块使用multiply-add块实现一个流点积运算的内积矩阵向量乘法。
让说,一个是一个矩阵的大小NxN和B是一个向量的大小资料片
然后,矩阵向量乘法输出将:Z=一个*B大小的资料片
DDR第N值被视为资料片大小向量,其次是NxN矩阵数据大小。前N值(矢量数据)存储到内存。从N + 1的值开始,数据是直接流矩阵数据。矢量数据会读的Vector_RAM并行执行。矩阵和向量的输入被送入Matrix_mul_top子系统。第一个矩阵输出之后可用N时钟周期,并将输出存储在RAM中。再次,向量RAM读地址重新初始化以0开始阅读相同的向量数据对应于新矩阵流。重复这个操作矩阵的行。
下图表显示的架构Matrix_Vector_Multiplication模块。

功能仿真模型万博1manbetx
你这个例子可以模拟模型,并验证在MATLAB仿真结果通过运行以下脚本:
hdlcoder_external_memory_simulation;
通过:DDR初始化数据匹配。通过:矩阵向量乘法输出与预期的数据匹配
该脚本首先初始化参数Matrix_Size。默认情况下,Matrix_Size是64,这意味着一个64 x64矩阵。默认的Matrix_Size保持小的模拟速度更快。DUT到FPGA实现董事会后,大Matrix_Size然后可以使用FPGA计算要快得多。在脚本中你也可以调整这些参数。
然后脚本模拟模型,并通过比较验证结果记录的仿真结果与期望值。
默认情况下,Matrix_Multiplication_On是真的,该脚本验证矩阵向量乘法的结果。
Matrix_Multiplication_On是假的时,脚本验证循环模式,这意味着DUT阅读Burst_Length从DDR的数据量,并回到DDR写数据。
如果你有一个DSP系统工具箱的许可证,您可以查看模型随着时间的推移,使用逻辑分析仪的信号。

生成与AXI4 HDL IP核心主界面
接下来,我们开始HDL工作流顾问和使用IP核心代工作流Zynq硬件上部署这个设计。更详细的一步一步的指导,请参阅开始使用针对Xilinx Zynq平台。
1。设置Xilinx Vivado合成工具路径使用以下命令在MATLAB命令窗口。使用自己的Vivado安装路径,当你运行该命令。
hdlsetuptoolpath (“ToolName”、“Xilinx Vivado”、“路径”,“C: \ Xilinx \ Vivado \ 2018.2 \ bin \ vivado.bat”)
2。开始的高密度脂蛋白工作流顾问DUT子系统,hdlcoder_external_memory / DUT。对模型目标接口设置保存。请注意,目标工作流程是IP核心代,目标平台是Xilinx Zynq ZC706评估工具,参考设计是默认系统与外部DDR3内存访问,目标平台接口表设置如下所示。
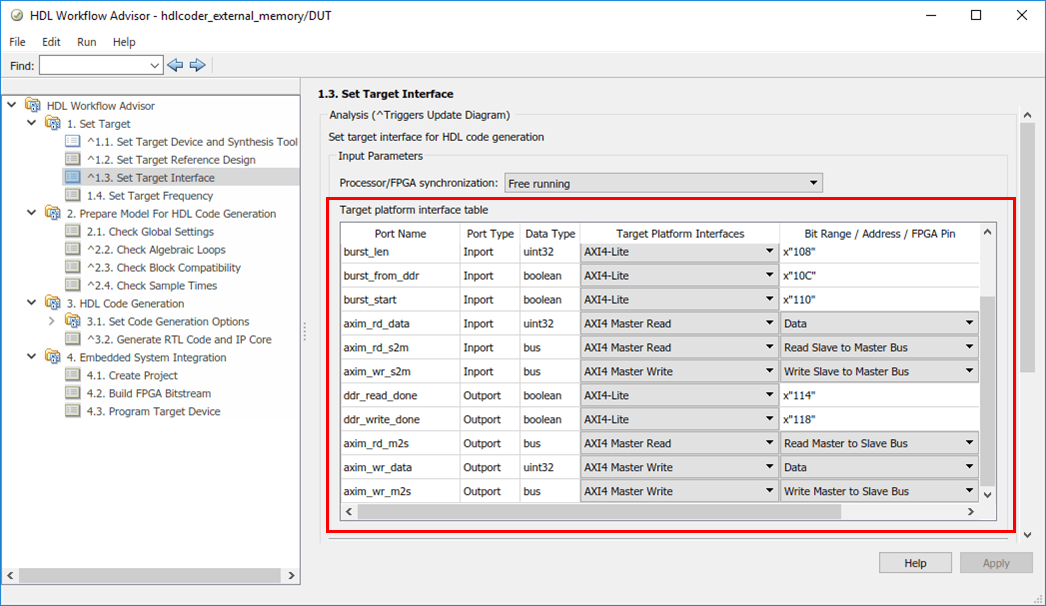
在本例中,输入参数的端口matrix_mul_on,matrix_size,burst_len,burst_from_ddr和突然开始映射到AXI4-Lite接口。高密度脂蛋白编码器将生成AXI4接口访问这些端口的寄存器。之后,您可以使用MATLAB优化这些参数在运行时,当设计FPGA板上运行。
AXI4主接口有独立的读写通道。读通道端口axim_rd_data,axim_rd_s2m,axim_rd_m2s被映射到AXI4主读接口。写通道端口axim_wr_data,axim_wr_s2m,axim_wr_m2s被映射到AXI4大师写接口。
3所示。右键单击任务3.2,生成RTL代码和IP核心,并选择选择任务运行生成IP核。你可以找到寄存器地址映射和其他文档的IP核心IP核生成报告。
4所示。现在右键单击任务4.2构建FPGA比特流,并选择选择任务运行生成Vivado项目,然后构建FPGA比特流。
在项目创建,生成的核心是集成到DUT的IP默认系统与外部DDR3内存访问参考设计。这个引用Xilinx内存接口生成器的设计包括IP与车载通信外部DDR3内存ZC706平台。MATLAB作为AXI主IP也添加到使MATLAB控制DUT的IP,并初始化并验证DDR内存的内容。
你可以点击链接在结果窗口在任务4.1“创建项目”来查看生成Vivado项目。如果你打开Vivado块设计,生成的参考设计项目类似于这个架构图。

运行在Xilinx FPGA实现Zynq ZC706评估工具
FPGA比特流生成后,您可以运行任务4.3项目目标设备通过JTAG电缆项目FPGA板。
然后您可以运行FPGA实现和验证结果通过运行以下脚本在MATLAB的硬件
hdlcoder_external_memory_hw_run
该脚本首先初始化Matrix_Size到500年,这意味着一个500 x500矩阵。你可以调整Matrix_Size到4000。
AXI4主读写通道基本地址配置。这些地址定义DUT的基地址读取,并写入外部DDR内存。在这个脚本中,基地址的DUT在读“80000000”,和基地址写“81000000”。
MATLAB的阿喜主功能是用来初始化外部DDR3内存和输入向量和矩阵数据,也清晰的DDR内存位置的输出。
DUT的计算是通过控制AXI4-Lite开始访问的寄存器。DUT的IP核心首先读取输入数据的DDR内存,执行矩阵向量乘法,然后把结果写回DDR内存。
最后,输出结果是读回MATLAB,并与期望值。通过这种方式,结果验证了在MATLAB的硬件。

访问外部DDR4内存Xilinx Zynq Ultrascale + MPSoC ZCU102评估工具
1。使用相同的模型hdlcoder_external_memory访问外部DDR4内存ZCU102 HDL编码器使用IP核心代工作流。
2。开始的高密度脂蛋白工作流顾问DUT子系统,hdlcoder_external_memory / DUT。在任务1.1目标平台作为Xilinx Zynq Ultrascale + MPSoC ZCU102评估工具在1.2任务集参考设计作为默认系统与外部DDR4内存访问
3所示。现在右键单击任务4.2构建FPGA比特流,并选择选择任务运行生成Vivado项目,然后构建FPGA比特流。
4所示。您可以运行任务4.3项目目标设备项目设备和硬件验证结果在MATLAB通过运行以下脚本:
hdlcoder_external_memory_hw_run_ZCU102
该脚本首先初始化Matrix_Size到2000年,这意味着一个2000 x2000矩阵。在这个脚本中,基地址的DUT在读“80000000”,和基地址写“90000000”。
最后,输出结果是读回MATLAB,并与期望值。通过这种方式,结果验证了在MATLAB的硬件。
