办公室由二进制整数规划作业:Solver-Based
这个例子展示了如何解决分配问题的二进制整数规划使用intlinprog函数。具体问题具体分析的方法这个问题,看到的办公室由二进制整数规划作业:具体问题具体分析。
办公室分配问题
你想安排6人,马塞洛,拉克什,彼得,汤姆,马约莉,和玛丽安,七个办事处。每个办公室可以有不超过一个人,每一人一个办公室。所以将会有一个空的办公室。人们可以给偏好的办公室,他们的偏好被认为是基于他们的资历。他们一直在MathWorks时间越长,资历越高。有些办公室窗户,一些不,一个窗口小于其他人。此外,彼得和汤姆经常一起工作,所以应该在相邻的办公室。马塞洛和拉克什经常一起工作,应在相邻的办公室。
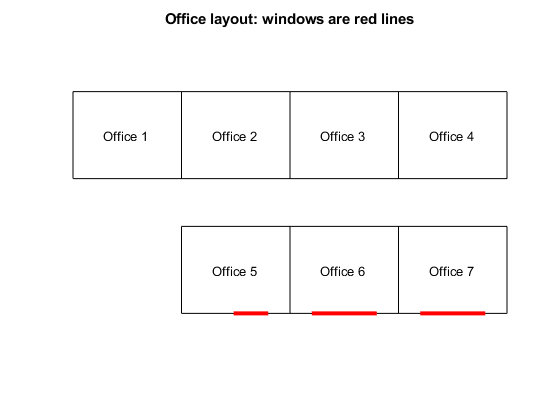
办公室布局
办公室1、2、3和4在办公室没有窗户。办公室5、6和7有窗户,但办公室5中的窗口小于其他两个。这里是办公室是如何安排的。
name = {办公室1 ',《办公室2》,办公室3 ',“办公室4”,办公室5 ',“办公室6”,“办公室7”};printofficeassign(名字)
问题公式化
你需要制定数学问题。首先,选择您的解决方案的每个元素变量x代表的问题。因为这是一个二进制整数的问题,一个不错的选择,每个元素代表一个人分配到一间办公室。如果这个人是分配给办公室,变量值1。如果一个人没有分配到办公室,变量值0。人数量如下:
玛丽安
马约莉
汤姆
彼得
马塞洛
拉克什
x是一个向量。的元素x (1)来x (7)对应于玛丽安被分配到办公室,办公室2,等等,办公室7。接下来的七个元素对应于马约莉被分配到7个办事处,等等。,x矢量有42个元素,因为6人被分配到7个办事处。
资历
你想减肥首选项基于资历,这样你在MathWorks的时间越长,越多你的喜好。资历如下:玛丽安9年,马约莉10年,汤姆5年,3年,彼得马塞洛1.5年,Rakesh 2年。创建一个基于资历的归一化权重向量。
资历= (9 10 5 3 1.5 - 2);weightvector =资历/笔(工龄);
人们的办公室偏好
建立一个偏好矩阵的行对应于办公室和列对应于人。每个办公室问每个人给值,这样他们的选择的总和,即。,他们的列,金额为100。数字越大,意味着喜欢办公室的人。每个人的喜好列出一个列向量。
玛丽安= [0;0;0;0;10;40;50);马约莉= [0;0;0; 0; 20; 40; 40]; Tom = [0; 0; 0; 0; 30; 40; 30]; Peter = [1; 3; 3; 3; 10; 40; 40]; Marcelo = [3; 4; 1; 2; 10; 40; 40]; Rakesh = [10; 10; 10; 10; 20; 20; 20];
第i个元素的一个人的偏好向量是他们高度重视的第i个办公室。因此,合并后的偏好矩阵如下。
prefmatrix =[玛丽安马约莉汤姆彼得拉克什]马塞洛;
体重的偏好矩阵weightvector规模列资历。也更方便重塑这个矩阵作为一个向量列顺序对应x向量。
点= prefmatrix *诊断接头(weightvector);c =点(,);
目标函数
目标是最大限度地满足偏好权重的资历。这是一个线性目标函数
马克斯c ' * x
或者同样的
min - c ' * x。
约束
第一组约束要求每一个人一个办公室,这是对于每一个人,的总和x值对应于那个人就是一个。例如,由于马约莉是第二位,这意味着和(x (14)) = 1。在一个平等的矩阵表示这些线性约束Aeq和向量说真的,在那里Aeq * x =说真的,通过建立适当的矩阵。矩阵Aeq由1和0组成。例如,第二行Aeq将对应于马乔里得到一个办公室,所以行是这样的:
0 0 0 0 0 0 0 1 1 1 1 1 1 1 0 0 0 0 0 0 0 0 0 0 0 0…0 0 0
有七个0列8到14和1。然后Aeq (2) * x = 1相当于和(x (14)) = 1。
numOffices = 7;numPeople = 6;numDim = numOffices * numPeople;numOffices onesvector = 1 (1);
每一行的Aeq对应于一个人。
Aeq = blkdiag (onesvector onesvector、onesvector onesvector,…onesvector onesvector);说真的= 1 (numPeople, 1);
第二组的约束是不平等。这些约束指定每个办公室都有不超过一个人,即。,每个办公室都有一个人,或者是空的。构建矩阵一个和向量b这样A * x < =捕捉这些约束。每一行的一个和b对应于一个办公室,所以第一行对应于分配给办公室1人。这一次,行有这种类型的模式,第一行:
1 0 0 0 0 0 0 1 0 0 0 0 0 0 1 0 0 0 0 0 0…1 0 0 0 0 0 0
每一行后这是相似但(圆)向右移一个位置。例如,第三行对应于办公室3和说(3:)* x < = 1,即,office 3 cannot have more than one person in it.
= repmat(眼(numOffices), 1, numPeople);b = 1 (numOffices, 1);
下一组约束也不平等,所以将它们添加到矩阵一个和向量b从上面已经包含了不平等。你想要汤姆和彼得不超过一个办公室远离彼此,和相同的马塞洛和拉克什。首先,建立办公室的距离矩阵根据他们的物理位置和使用近似的曼哈顿距离。这是一个对称矩阵。
D = 0 (numOffices);
右上角设置矩阵的一半。
D(1、2:结束)= (1 2 3 2 3 4);D(2、3:结束)= (1 2 1 2 3);D(3、4:结束)= [1 2 1 2];D(4、5:结束)= (3 2 1);D(5、6:结束)= (1 - 2);D (6) = 1;
左下角是一样的右上角的一半。
D = triu (D) + D;
找到多个距离单元的办公室。
[officeA, officeB] =找到(D > 1);numPairs =长度(officeA)
numPairs = 26
这个发现numPairs对不相邻的办公室。对于这些配对,如果汤姆对占有一个办公室,彼得不能占领的其他办公室。如果他这么做了,他们将不相邻。马塞洛和拉克什的也是如此。这给了2 * numPairs你添加更多的不等式约束一个和b。
添加足够的行一个以适应这些约束。
numrows = 2 * numPairs + numOffices;((numOffices + 1): numrows, 1: numDim) = 0 (2 * numPairs numDim);
每一对的办公室numPairs,x(我)对应于汤姆的officeA和x (j)对应于彼得OfficeB,
(我)+ x (j) < = 1。
这意味着汤姆或彼得可以占据其中的一个办公室,但是他们都不能。
汤姆是人3和彼得是4。
汤姆= 3;彼得= 4;
马塞洛是人拉克什是5和6。
马塞洛= 5;拉克什= 6;
下面的匿名函数返回相对应的指数x汤姆,彼得,马塞洛和Rakesh分别在我办公室。
tom_index = @ (officenum) (tom-1) * numOffices + officenum;peter_index = @ (officenum)(后一)* numOffices + officenum;marcelo_index = @ (officenum) (marcelo-1) * numOffices + officenum;rakesh_index = @ (officenum) (rakesh-1) * numOffices + officenum;为i = 1: numPairs tomInOfficeA = tom_index (officeA(我));peterInOfficeB = peter_index (officeB (i));(i + numOffices [tomInOfficeA peterInOfficeB]) = 1;%重复拉克什,马塞洛和添加更多的行A和b。marceloInOfficeA = marcelo_index (officeA (i));rakeshInOfficeB = rakesh_index (officeB (i));(i + numPairs + numOffices [marceloInOfficeA rakeshInOfficeB]) = 1;结束b (numOffices + 1: numOffices + 2 * numPairs) = 1 (2 * numPairs, 1);
解决使用intlinprog
配方由一个线性目标函数的问题
min - c ' * x
线性约束
Aeq * x =说真的
A * x < =
所有变量的二进制
你已经做了一个,b,Aeq,说真的条目。现在设置目标函数。
f = - c;
确保变量是二进制的,下界为0,1的上界,集intvars代表所有的变量。
磅= 0(大小(f));乌兰巴托=磅+ 1;intvars = 1:长度(f);
调用intlinprog来解决这个问题。
[x, fval exitflag、输出]= intlinprog (f intvars A、b Aeq,说真的,磅,乌兰巴托);
LP:最优的客观价值是-33.868852。减少生成:应用1 Gomory削减。下界是-33.836066。相对差距是0.00%。找到最优解。Intlinprog停在根节点,因为客观价值差距公差内的最优值,选择。AbsoluteGapTolerance = 0(默认值)。在宽容intcon变量是整数,选项。IntegerTolerance = 1 e-05(默认值)。
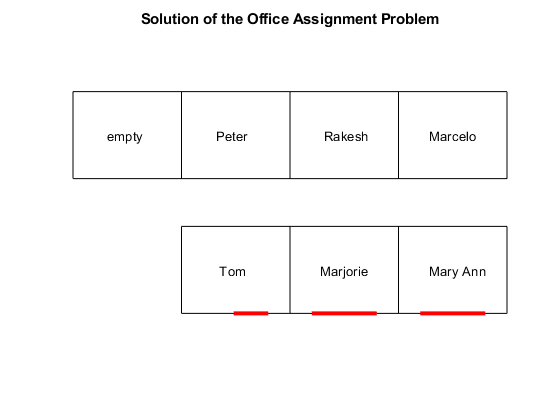
查看解决方案——每个办公室了?
numPeople = 7;办公室=细胞(numPeople, 1);为i = 1: numPeople办公室{我}=找到(x(我:numPeople:结束);%的人指数结束人= {“玛丽安”,“马约莉”,“汤姆”,“彼得”,“马塞洛”,拉克什的};为我= 1:numPeople如果办公室isempty({})名称{我}=“空”;其他的名字{}=人办公室({});结束结束printofficeassign(名称);标题(办公室分配问题的解决方案);
解决方案质量
对于这个问题,满足偏好的资历是最大化的价值-fval。exitflag= 1告诉你intlinprog聚集到一个最优的解决方案。输出结构使信息解决方案过程,如探索有多少节点和之间的差距的上下边界计算分支。在这种情况下,没有生成和节点,这意味着没有和步骤,问题就迎刃而解了。差距是0,这意味着解决方案是最优的,在没有内部差异计算低,目标函数上界。
fval exitflag,输出
fval = -33.8361
exitflag = 1
输出=结构体字段:relativegap: 0 absolutegap: 0 numfeaspoints: 1 numnodes: 0 constrviolation: 0消息:“找到最优解。↵↵Intlinprog停在根节点,因为客观价值差距公差内的最优值,选择。AbsoluteGapTolerance = 0(默认值)。在宽容intcon变量是整数,选项。IntegerTolerance = 1 e-05(默认值)。
