使用麦克风阵列的声波束形成
本实施例说明麦克风阵列的波束形成在干扰占优,嘈杂的环境中,以提取所需的语音信号。这样的操作是,以增强用于感知或进一步处理的语音信号的质量是有用的。例如,嘈杂的环境可以是一个交易室,和麦克风阵列可被安装在计算机的交易的监视器上。如果交易的计算机必须从一个商人接受语音命令,波束形成器的操作关键是要提高接收的语音质量,实现设计的语音识别的准确性。
这个例子显示了两种类型的时域波束形成器的:时间延迟波束形成器和所述波束合成器冰霜。它说明了一个如何使用对角加载改善冰霜波束形成器的鲁棒性。您可以在每个处理步骤听取语音信号,如果你的系统有完善的支持。万博1manbetx
定义一个均匀线性数组
首先,我们定义的均匀线性阵列(ULA),以接收信号。所述阵列包含10个全向麦克风和元件间隔为5cm。
麦克风=...phased.OmnidirectionalMicrophoneElement (“FrequencyRange”[20 20e3]);NELE = 10;乌拉= phased.ULA(NELE,0.05,'元件',麦克风);C = 340;%声速,m/s
模拟接收信号
接下来,我们模拟麦克风阵列接收到的多通道信号。我们先下载两段演讲录音和一段笑声录音。我们也加载笑声音频部分作为干扰。音频信号的采样频率为8khz。
由于音频信号通常很大,将整个信号读入存储器通常是不实际的。因此,在本例中,我们将以流的方式模拟和处理信号,即,breaking the signal into small blocks at the input, processing each block, and then assembling them at the output.
所述第一语音信号的入射方向是在方位角-30度和在仰角0度。第二语音信号的方向是在方位角-10度和在仰角为10度。干扰来自于方位20度,仰角0度。
ang_dft = [-30;0];ang_cleanspeech = [-10;10];ang_laughter = [20;0];
现在我们可以使用宽带集电极,以模拟由所述阵列接收的3第二多信道信号。注意,这种方法假定每个输入单信道信号是由一个单一麦克风在阵列的原点接收。
fs = 8000;收集器= phased.WidebandCollector ('传感器',乌拉,'PropagationSpeed',C,...'采样率',FS,'NumSubbands',1000,“ModulatedInput”,假);t_duration = 3;%3秒t = 0时:1 / FS:t_duration-1 / FS;
我们产生一个功率为1e-4瓦的白噪声信号来表示每个传感器的热噪声。本地随机数流确保可重复的结果。
prevS = RNG(2008);noisePwr = 1E-4;%噪声功率
现在,我们开始模拟。在输出端,所接收的信号被存储在一个10列的矩阵。该矩阵的每列表示由一个麦克风收集的信号。请注意,我们使用的是模拟在流的方法也播放音频。
% preallocateNSampPerFrame = 1000;NTSample = t_duration * FS;sigArray =零(NTSample,NELE);voice_dft =零(NTSample,1);voice_cleanspeech =零(NTSample,1);voice_laugh =零(NTSample,1);%设置音频设备的作家audioWriter = audioDeviceWriter('采样率',FS,...'万博1manbetxSupportVariableSizeInput',真正的);isAudio万博1manbetxSupported =(长度(getAudioDevices(audioWriter))> 1);dftFileReader = dsp.AudioFileReader('dft_voice_8kHz.wav',...'SamplesPerFrame',NSampPerFrame);speechFileReader = dsp.AudioFileReader('cleanspeech_voice_8kHz.wav',...'SamplesPerFrame',NSampPerFrame);laughterFileReader = dsp.AudioFileReader (“laughter_8kHz.wav”,...'SamplesPerFrame',NSampPerFrame);%模拟对于m = 1时:NSampPerFrame:NTSample sig_idx = M:M + NSampPerFrame-1;X1 = dftFileReader();X2 = speechFileReader();X3 = 2 * laughterFileReader();温度=集电极([X1 X2 X3的],...[ang_dft ang_cleanspeech ang_laughter])+...√noisePwr * randn (NSampPerFrame Nele);如果isAudio万博1manbetxSupported播放(audioWriter,0.5 *温度(:,3));结束sigArray (sig_idx:) = temp;voice_dft (sig_idx) = x1;voice_cleanspeech (sig_idx) = x2;voice_laugh (sig_idx) = x3;结束
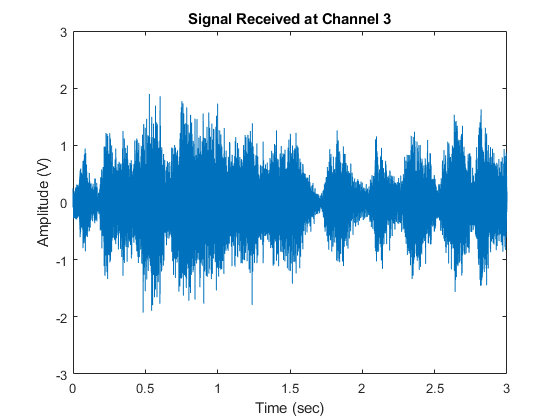
注意,笑声掩盖了语言信号,使它们变得难以理解。我们可以将3频道的信号绘制如下:
情节(T,sigArray(:,3));xlabel(的时间(秒));ylabel('振幅(V)');标题(“信号接收在频道3”);ylim([ - 3 3]);
具有时滞波束形成过程
的时间延迟波束生成器补偿了整个阵列的到达时间差为从特定方向到来的信号。时间对准的多声道信号被相干平均,以提高信噪比(SNR)。现在,定义对应于所述第一语音信号的入射方向上的转向角和构造的时间延迟波束生成器。
angSteer = ang_dft;波束形成器= phased.TimeDelayBeamformer('SensorArray',乌拉,...'采样率',FS,'方向',angSteer,'PropagationSpeed',C)
波束形成器= phased.TimeDelayBeamformer与属性:SensorArray:[1x1的phased.ULA] PropagationSpeed:340 SAMPLERATE:8000 DirectionSource: '属性' 方向:[2×1双] WeightsOutputPort:假
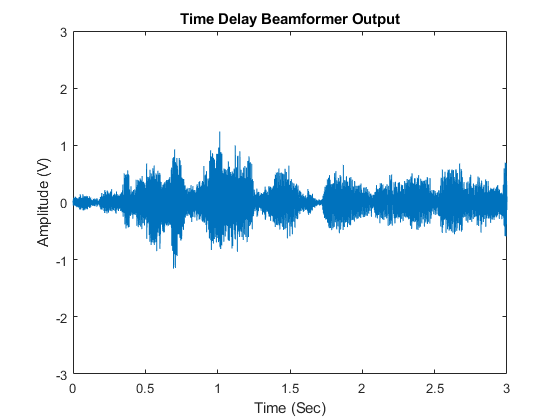
接下来,我们对合成信号进行处理,绘制并监听常规波束形成器的输出。同样,我们在处理过程中回放了波束形成的音频信号。
signalsource = dsp.SignalSource('信号',sigArray,...'SamplesPerFrame',NSampPerFrame);cbfOut =零(NTSample,1);对于m = 1时:NSampPerFrame:NTSample临时=波束形成器(signalsource());如果isAudio万博1manbetxSupported播放(audioWriter,温度);结束cbfOut(M:M + NSampPerFrame-1,:) =温度;结束情节(T,cbfOut);xlabel(“时间(秒)”);ylabel('振幅(V)');标题(“延时波束形成器输出”);ylim([ - 3 3]);
可以测量由阵列增益,这是输出信号与干扰加噪声比(SINR)来输入SINR比语音增强。
agCbf = pow2db(平均值((voice_cleanspeech + voice_laugh)。^ 2 + noisePwr)/...平均((cbfOut - voice_dft)^ 2))
agCbf = 9.5022
第一个语音信号开始出现在延时波束形成器的输出中。我们获得了9.4 dB的信噪比改善。然而,背景的笑声仍可与演讲媲美。要获得更好的波束形成器性能,请使用冰霜波束形成器。
与波束形成器冰霜过程
通过FIR滤波器附接到每个传感器,冰霜波束形成器已经更多波束成形权重来抑制干扰。这是一个自适应算法,在了解到干扰方向,以更好地抑制干扰地空值。在转向方向上,波束形成器冰霜用途失真限制,以确保期望的信号不被抑制。让我们创建一个冰霜波束形成器与每个传感器后20抽头FIR。
frostbeamformer =...phased.FrostBeamformer('SensorArray',乌拉,'采样率',FS,...'PropagationSpeed',C,'FilterLength'20,“DirectionSource”,“输入端口”);
接下来,使用霜波束形成器处理合成的信号。
复位(signalsource);FrostOut =零(NTSample,1);对于m = 1:NSampPerFrame:NTSample FrostOut(m:m+NSampPerFrame-1,:) =...frostbeamformer(signalsource(),ang_dft);结束
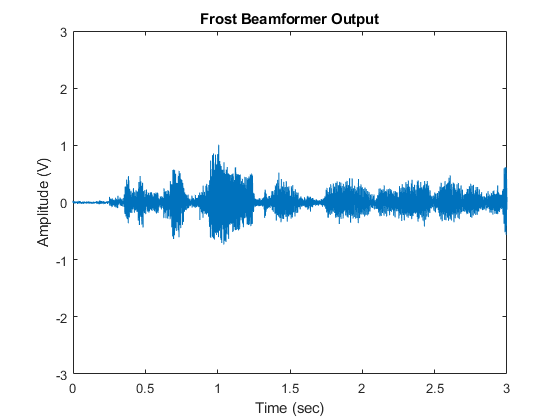
我们可以玩,一旦处理绘制整个音频信号。
如果isAudio万博1manbetxSupported播放(audioWriter,FrostOut);结束情节(T,FrostOut);xlabel(的时间(秒));ylabel('振幅(V)');标题(“弗罗斯特波束成型器输出”);ylim([ - 3 3]);
%计算阵列增益agFrost = pow2db(平均值((voice_cleanspeech + voice_laugh)。^ 2 + noisePwr)/...平均((FrostOut - voice_dft)^ 2))
agFrost = 14.4385
请注意,干扰现在已取消。冰霜波束形成器具有14分贝,这是4.5分贝比的时间延迟波束生成器的更高的阵列增益。性能的提高是令人印象深刻,但具有较高的计算成本。在前面的例子中,顺序20的FIR滤波器被用于每个麦克风。与所有10个传感器,一个需要以反转200通过-200矩阵,其可以是在实时处理昂贵。
使用角加载提高冰霜波束形成器的稳健性
接下来,我们希望以操纵在所述第二语音信号的方向上的阵列。假设我们不知道第二语音信号的精确方向,除了方位-5度和仰角5度的粗略估计。
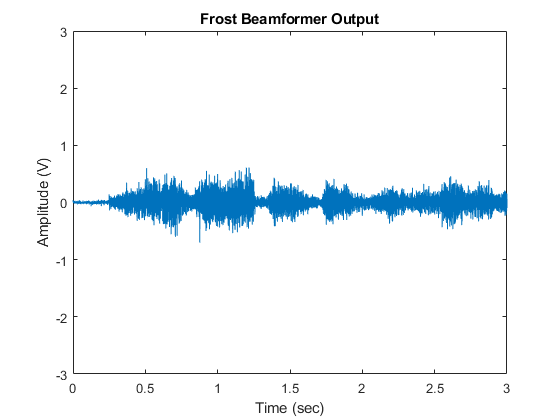
释放(frostbeamformer);ang_cleanspeech_est = [5;5);%估算转向方向复位(signalsource);FrostOut2 =零(NTSample,1);对于m = 1:NSampPerFrame:NTSample FrostOut2(m:m+NSampPerFrame-1,:) = frostbeamformer(signalsource(),...ang_cleanspeech_est);结束如果isAudio万博1manbetxSupported播放(audioWriter,FrostOut2);结束情节(t, FrostOut2);xlabel(的时间(秒));ylabel('振幅(V)');标题(“弗罗斯特波束成型器输出”);ylim([ - 3 3]);
%计算阵列增益agFrost2 = pow2db(意思是((voice_dft + voice_laugh)。^ 2 + noisePwr) /...平均((FrostOut2 - voice_cleanspeech)^ 2)。)
agFrost2 = 6.1927
语音几乎听不见。尽管从波束形成器6.1 dB增益,从性能不准确的转向方向受到影响。以提高冰霜波束形成器的鲁棒性的一种方法是用对角加载。这种方法增加了少量的所估计的协方差矩阵的对角元素。下面我们就用1E-3的对角值。
%指定角加载值释放(frostbeamformer);frostbeamformer.DiagonalLoadingFactor = 1E-3;复位(signalsource);FrostOut2_dl =零(NTSample,1);对于m = 1时:NSampPerFrame:NTSample FrostOut2_dl(M:M + NSampPerFrame-1,:) =...frostbeamformer(signalsource(),ang_cleanspeech_est);结束如果isAudio万博1manbetxSupported播放(audioWriter,FrostOut2_dl);结束情节(T,FrostOut2_dl);xlabel(的时间(秒));ylabel('振幅(V)');标题(“弗罗斯特波束成型器输出”);ylim([ - 3 3]);
%计算阵列增益agFrost2_dl = pow2db(平均值((voice_dft + voice_laugh)。^ 2 + noisePwr)/...意思是((FrostOut2_dl - voice_cleanspeech) ^ 2)。)
agFrost2_dl = 6.4788
现在,输出语音信号的改进,我们获得对角加载技术0.3dB的增益提高。
释放(frostbeamformer);释放(signalsource);如果isAudio万博1manbetxSupported暂停(3);%刷新音频播放器缓冲区释放(audioWriter);结束RNG(prevS);
总结
该示例示出了如何使用时域波束形成器来检索从嘈杂麦克风阵列测量的语音信号。该示例还显示了如何通过模拟麦克风阵列接收到的干扰的主导信号。本例中使用了时间延迟和冰霜波束形成器,并比较了它们的性能。冰霜波束形成器具有更好的抗干扰能力。这个例子也说明了对角加载的改善冰霜波束形成器的鲁棒性。
参考
“线性约束自适应阵列处理的演算法”,《IEEE学报》,第60卷,第8期,1972年8月,第925-935页。
你也可以从以下列表中选择一个网站:
