单基地雷达系统的多核仿真
本示例模拟单基地雷达系统。它使用Simulink®中的dataflow domain自动将雷达系统的数据驱动部分划分为多个线程,从而通过在桌面的多核上执行万博1manbetx来提高模拟的性能。
介绍
数据流执行域允许您在模拟计算密集型系统时使用多个核心。此示例显示了作为子系统执行域的数据流如何提高模型的模拟性能。要了解更多关于数据流以及如何使用多线程运行Simulink模型的信息,请参阅万博1manbetx使用数据流域的多核执行(DSP系统工具箱)。
单站单目标雷达
此示例模拟了一个简单的端到端单基地雷达。矩形脉冲由发射机模块放大,然后在自由空间中传播到目标和从目标传播。然后在接收机前置放大器模块中将噪声和放大应用到返回信号,然后应用匹配滤波器。补偿距离损失,脉冲为非相干脉冲完全整合。
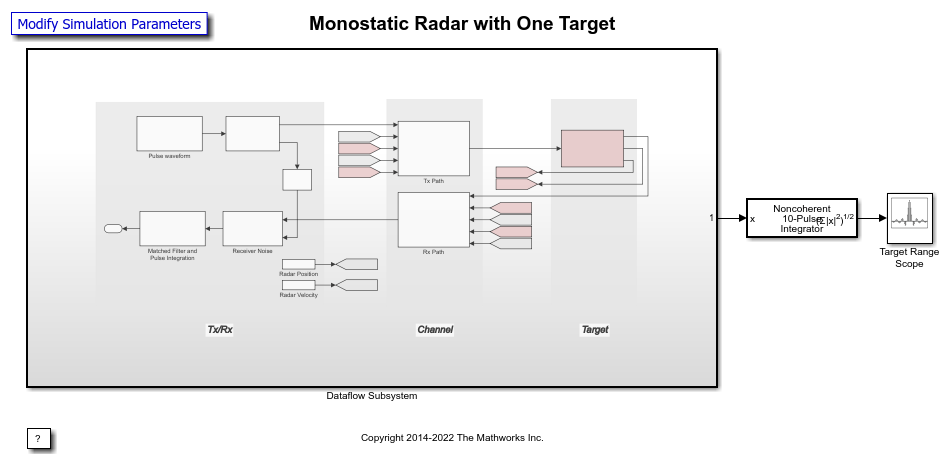
设置数据流子系统
此示例使用Simulink中的dataflow domain来利用桌面上的万博1manbetx多个内核来提高模拟性能。此模型中dataflow子系统的域参数设置为数据流。您可以通过选择子系统,然后选择视图>属性检查器.Dataflow域会自动对模型进行分区,并使用多个线程模拟系统以获得更好的模拟性能。将域参数设置为Dataflow后,可以使用Dataflow simulation Assistant分析模型以获得更好的性能。单击数据流助手按钮下方的自动计算框架尺寸属性检查器中的参数。


数据流子系统的并发性分析
Dataflow Simulation Assistant建议更改模型设置以获得最佳模拟性能。要接受建议的模型设置,请单击旁边的模拟性能的建议模型设置点击全部接受. 或者,您可以展开该部分以单独更改设置。在本例中,模型设置已经是最佳的。在Dataflow Simulation Assistant中,单击分析按钮开始分析数据流域以获得模拟性能。分析完成后,Dataflow Simulation Assistant将显示Dataflow子系统在模拟期间将使用多少线程。
分析模型后,助手显示一个线程,因为模型中块之间的数据依赖关系阻止块并发执行。通过对依赖于数据的块进行流水线处理,数据流子系统可以提高并发性以获得更高的数据吞吐量。Dataflow Simulation Assistant将建议的管道延迟数显示为建议的延迟。计算建议的延迟值以提供最佳性能。
下图显示了Dataflow Simulation Assistant,其中Dataflow子系统当前指定的延迟值为零,系统的建议延迟值为四。

点击接受旁边的按钮建议延迟在Dataflow Simulation Assistant中,使用数据流子系统的建议延迟。
Dataflow Simulation Assistant现在将线程数显示为四个,这意味着Dataflow子系统内的块使用四个线程并行模拟。四个管道延迟的使用增加了数据流子系统内部可以并行运行的块的数量。也可以直接在属性检查器中为“延迟”参数输入延迟值。Simulink使用以下命令显示延迟参数值:万博1manbetx 数据流子系统输出端口上的标记。
数据流子系统输出端口上的标记。

多核仿真性能
我们通过比较在使用和不使用数据流的情况下运行模型所需的执行时间来衡量使用数据流域的性能改进。执行时间是使用sim命令来衡量的,该命令返回模型的模拟执行时间。这些数字和分析是在带有Intel®的Windows桌面计算机上发布的Xeon®CPU W-2133@3.6 GHz 6核12线程处理器。
多线程模型的模拟执行时间=18.95s单线程模型的模拟执行时间=27.52s数据流的实际加速比:1.5x
总结
此示例显示了dataflow execution domain如何通过在桌面上使用多个内核来提高雷达系统仿真的性能。
您还可以从以下列表中选择网站:
