创建万博1manbetx环境中的强化学习
在强化学习的场景,你在哪里训练的代理来完成任务,环境模型的动态与该代理进行交互。如图下图,环境:
接收来自代理操作。
观察输出响应行动。
生成奖励测量行动有助于实现任务有多好。
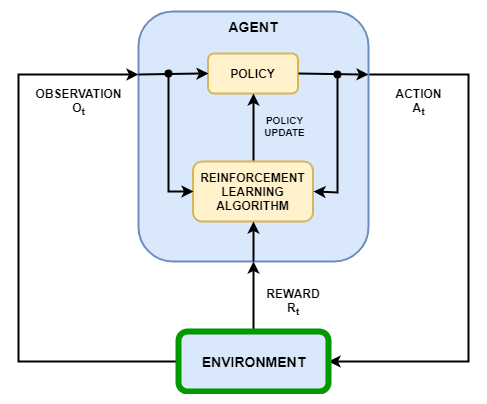
创建环境模型包括定义如下:
操作和观察信号代理使用与环境互动。
奖赏信号代理使用来衡量其成功。欲了解更多信息,请参阅定义奖赏信号。
环境动态行为。
行动和观测信号
当你创建一个环境对象,必须指定动作和观察信号代理使用与环境互动。您可以创建离散和连续动作的空间。欲了解更多信息,请参阅rlNumericSpec和rlFiniteSetSpec, 分别。
什么信号选择的动作和观察取决于你的应用。例如,对于控制系统的应用,误差信号的积分(有时衍生物)通常是有用的观测。另外,对于参考跟踪应用中,具有随时间变化的基准信号作为观察是有帮助的。
当你定义你的观察信号,确保所有的系统状态是通过观察观察到。例如,回转摆的图像观察具有位置信息,但不具有足够的信息来确定摆速度。在这种情况下,您可以指定摆速度作为一个单独的观察。
预定义万博1manbetx环境
强化学习工具箱™软件提供了预定义的Simulink万博1manbetx®行动,观察,奖励和动态已经为其定义的环境。您可以使用这些环境:
学习强化学习的概念。
增益熟悉强化学习工具箱软件功能。
测试你自己的强化学习代理商。
欲了解更多信息,请参阅加载预定义的Simulink环境万博1manbetx。
习惯万博1manbetx环境
要指定自己的自定义强化学习环境,营造与Simulink模型万博1manbetxRL代理块。在这个模型中,连接动作,观察和奖励信号到RL代理块。对于一个示例,请参见水箱强化学习环境模型。
对于动作和观察信号,必须使用规范创建对象rlNumericSpec对于连续信号和rlFiniteSetSpec对于离散信号。对于总线信号,创建使用规范bus2RLSpec。
对于回报信号,在模型中构建的标量信号和该信号连接到RL代理块。欲了解更多信息,请参阅定义奖赏信号。
配置Simulink模型后,创建使用模型中的万博1manbetx环境对象rl万博1manbetxSimulinkEnv功能。
如果你有一个适当的动作输入端口,观察输出端口,和标量奖励输出端口的参考模型,可以自动创建一个Simulink模型,包括这个参考模型和万博1manbetxRL代理块。欲了解更多信息,请参阅createIntegratedEnv。该函数返回环境对象,操作规范,并为模型的观察指标。
你的环境可以包括第三方功能。欲了解更多信息,请参阅与现有的模拟或环境集成(万博1manbetxSIMULINK)。
也可以看看
createIntegratedEnv|rlPredefinedEnv|rl万博1manbetxSimulinkEnv
相关话题
您还可以选择从下面的列表中的网站: