火车AC代理商使用并行计算平衡车杆系统
这个例子展示了如何使用异步并行训练训练一个行动者-评论家(AC)代理平衡一个在MATLAB®中建模的车杆系统。有关如何在不使用并行训练的情况下训练代理的示例,请参见训练空调代理人平衡车杆系统.
演员并行训练
使用与AC代理的并行计算时,每个工作人员从其代理和环境的副本生成体验。毕竟N步骤,工作人员根据经验计算梯度,并将计算的梯度发送回主机代理。主机代理更新其参数如下。
对于异步训练,主机代理应用接收到的梯度,而不需要等待所有的worker发送梯度,并将更新后的参数发送回提供梯度的worker。然后,工作人员继续使用更新后的参数从其环境中生成经验。
对于同步训练,主机代理等待从所有工作人员接收梯度并使用这些梯度更新其参数。然后,主机将更新后的参数同时发送给所有工作人员。然后,所有工作人员使用更新后的参数继续生成体验。
创建购物车MATLAB环境界面
为购物车系统创建一个预定义的环境界面。有关此环境的更多信息,请参阅负载预定义控制系统环境.
Env = Rlpredefinedenv(“CartPole-Discrete”);env.penaltyforafaling = -10;
从环境界面获取观察和行动信息。
ObsInfo = GetobservationInfo(ENV);numobservations = Obsinfo.dimension(1);Actinfo = GetActionInfo(Env);
修复随机生成器种子的再现性。
RNG(0)
创建AC代理
AC代理使用批判值函数表示来近似给定的观察和行动的长期回报。要创建批评家,首先创建一个深度神经网络,它有一个输入(观察)和一个输出(状态值)。由于环境提供了4个观测结果,所以评价网络的输入大小为4。有关创建深度神经网络值函数表示的更多信息,请参见创建策略和值函数表示.
批评= [featureInputLayer(4,'正常化'那'没有任何'那'名称'那“状态”)全连接列(32,'名称'那“CriticStateFC1”)剥离('名称'那“CriticRelu1”)全康连接层(1,'名称'那'批评'));criticOpts = rlRepresentationOptions ('学习',1e-2,'gradientthreshold'1);评论家= rlValueRepresentation (criticNetwork obsInfo,'观察', {“状态”}, criticOpts);
AC代理商决定使用演员代表的观察到进行哪些行动。要创建演员,请创建一个具有一个输入(观察)和一个输出(动作)的深神经网络。Actor网络的输出大小为2,因为代理可以将2力值应用于环境,-10和10。
[featureInputLayer(4,'正常化'那'没有任何'那'名称'那“状态”)全连接列(32,'名称'那'ActorstateFC1')剥离('名称'那“ActorRelu1”)全连接列(2,'名称'那'行动'));Actoropts = RlRepresentationOptions('学习',1e-2,'gradientthreshold'1);演员= rlStochasticActorRepresentation (actorNetwork obsInfo actInfo,......'观察', {“状态”},actoropts);
要创建AC代理,请先使用AC代理选项指定使用rlACAgentOptions.
代理= rlacagentoptions(......“NumStepsToLookAhead”,32,......'entropylossweight',0.01,......“DiscountFactor”,0.99);
然后使用指定的Actor表示和代理选项创建代理。有关更多信息,请参阅rlacagent..
代理= rlacagent(演员,批评者,代理商);
并行培训选项
要培训代理,首先指定培训选项。对于本示例,请使用以下选项。
每次训练最多跑一次
1000剧集,每一集最多持久500.时间步骤。在Episode Manager对话框中显示培训进度(设置
绘图选项)并禁用命令行显示(设置详细的选项)。停止训练时,代理收到的平均累积奖励大于
500.超过10.连续发作。此时,代理可以在直立位置平衡摆锤。
训练= rltrainingOptions(......“MaxEpisodes”,1000,......“MaxStepsPerEpisode”, 500,......'verbose'假的,......'plots'那'培训 - 进步'那......'stoptrinaincriteria'那'AverageReward'那......“StopTrainingValue”,500,......'scoreaveragingwindowlength',10);
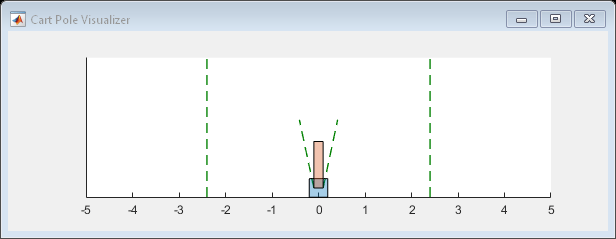
您可以可视化的车杆系统可以在训练或模拟使用阴谋函数。
情节(env)
要使用并行计算训练代理,请指定以下培训选项。
设定
使用指α.选项真正的.通过设置培训代理
ParallelizationOptions。模式选项“异步”.在每32步之后,每个工人根据经验计算梯度,并将它们发送给主机。
AC代理需要工人发送“
渐变“到主人。AC代理要求
“StepsUntilDataIsSent”等于AgentOptions.NumStepStolookahead..
trainOpts。UseParallel = true;trainOpts.ParallelizationOptions.Mode =“异步”;trainOpts.ParallelizationOptions.DataToSendFromWorkers =“梯度”;trainOpts.ParallelizationOptions.StepsUntilDataIsSent = 32;
有关更多信息,请参阅rlTrainingOptions.
火车代理
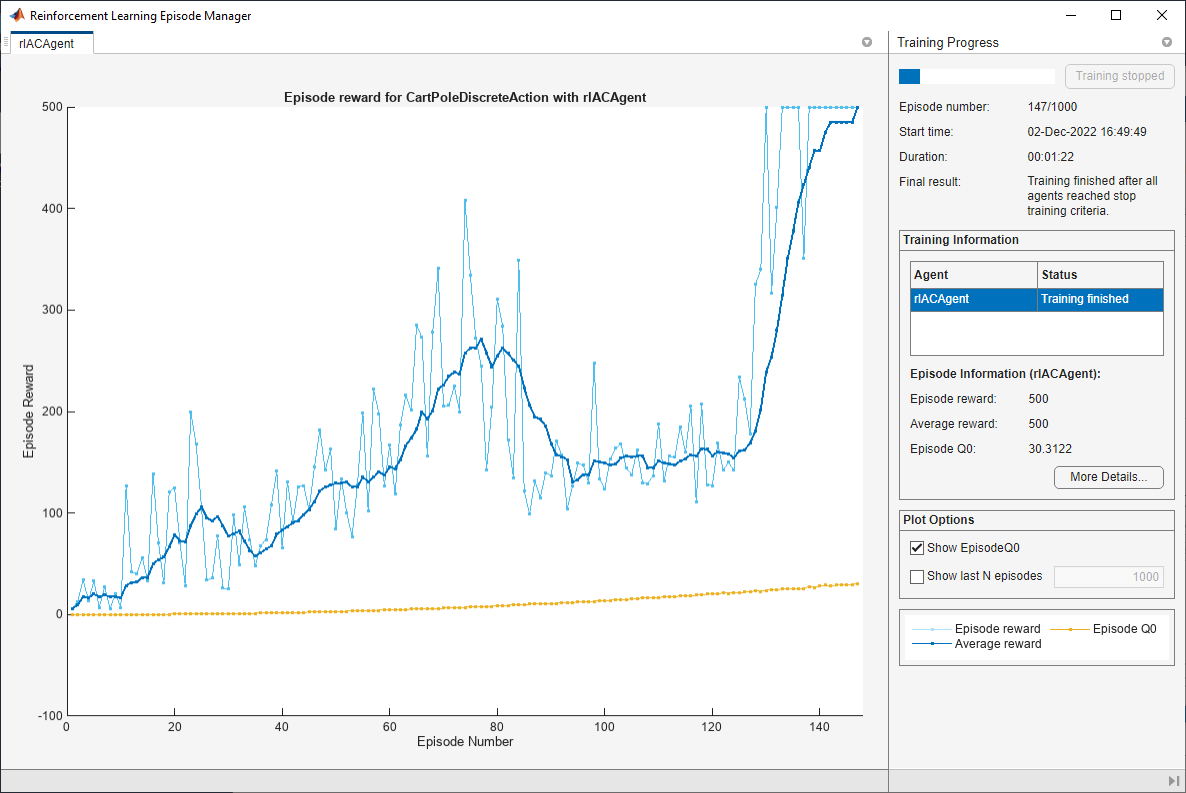
训练代理人使用火车函数。训练代理是一个计算密集型的过程,需要几分钟才能完成。为了节省运行此示例的时间,请通过设置加载预先训练过的代理用圆形到错误的.自己训练代理人,设置用圆形到真正的.由于异步并行培训中的随机性,您可以期待以下培训情节的不同培训结果。情节显示培训与六名工人的结果。
doTraining = false;如果用圆形%训练代理人。trainingStats =火车(代理,env, trainOpts);别的%加载预磨料的代理。加载('matlabcartpoleplac.mat'那'代理人');结尾
模拟交流代理
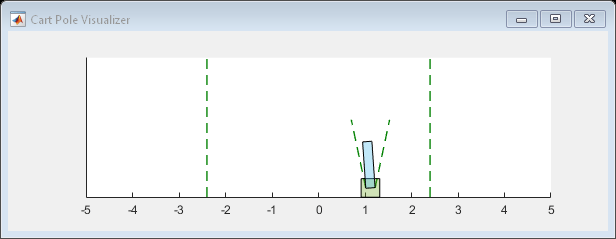
在模拟过程中,您可以使用绘图功能可视化车杆系统。
情节(env)
要验证培训的代理的性能,请在推车杆环境中模拟它。有关代理模拟的更多信息,请参阅rlSimulationOptions和SIM.
simOptions = rlSimulationOptions (“MaxSteps”,500);体验= SIM(ENV,Agent,SimOptions);
TotalReward = Sum(经验.Rward)
totalReward = 500
参考文献
[1] Mnih, Volodymyr, Adrià Puigdomènech Badia, Mehdi Mirza, Alex Graves, Timothy P. lilliicrap, Tim Harley, David Silver, Koray Kavukcuoglu。“深度强化学习的异步方法”。arxiv:1602.01783 [CS],2016年6月16日。https://arxiv.org/abs/1602.01783.
也可以看看
相关的话题
你也可以从以下列表中选择一个网站: