使用Copulas建模相关的缺省值
此示例探讨如何使用多因素系词模型来模拟相关对手默认值。
潜在的损失估计为交易对手的投资组合,由于其违约风险暴露,违约概率和违约损失率的信息。一个creditDefaultCopula对象用于每个债务人的信用与潜在变量模型。潜变量是由一系列的加权潜在信贷因素,以及每个债务人的信用特质因素。潜变量对应的是债务人的默认或非默认状态下,基于其违约概率每个场景。投资组合风险的措施,在交易对手风险水平的贡献,以及仿真收敛信息的支持万博1manbetxcreditDefaultCopula宾语。
本例还探讨了风险度量对copula类型(高斯copula和高斯copula)的敏感性Ť用于模拟。
加载和检查证券数据
该组合包含在默认的100方和它们相关的信贷风险(含铅),默认的概率(PD)和违约损失率(LGD)。用一个creditDefaultCopula对象,您可以模拟在某个固定时间段(例如,一年)内的默认值和损失。该含铅,PD和LGD输入必须特定于特定的时间范围。
在本例中,每个交易对手都被映射到具有一组权重的两个基础信用因子上。该Weights2F变量是一个NumCounterparties乘3矩阵,其中每一行包含一个单一的对方的权重。前两列是两个信贷因素的权重和最后一列是每个对手的特质权重。对于两个基本因素的相关矩阵也在本示例中提供(FactorCorr2F)。
负载CreditPortfolioData.mat谁是含铅PDLGDWeights2FFactorCorr2F
名称大小字节类属性EAD 100X1 800双FactorCorr2F 2×2 32双LGD 100X1 800双PD 100X1 800双Weights2F 100x3 2400双
初始化creditDefaultCopula与该组合信息和所述因子相关性对象。
RNG('默认');CC = creditDefaultCopula(EAD,PD,LGD,Weights2F,'FactorCorrelation',FactorCorr2F);%变动风险值水平99%。cc.VaRLevel = 0.99;DISP(CC)
creditDefaultCopula with properties: Portfolio: [100x5表]factor - correlation: [2x2 double] VaRLevel: 0.9900 UseParallel: 0 PortfolioLosses: []
:cc.Portfolio (1:5)
ans = 5 x5表ID EAD PD乐金显示器权重__ _____ _____ _____ ____________________ 1 21.627 0.0050092 0.35 0.35 0.65 - 2 0 3 0 3.2595 0.060185 0.35 0.45 - 0.55 20.391 0.11015 0.55 0.15 0.85 0 4 5 0 3.7534 0.0020125 0.35 0.25 0.75 5.7193 0.060185 0.35 0.35 0.65 0
模拟模型和绘制的潜在损失
使用模拟多因素模型模拟函数。默认情况下,使用高斯系词。该函数在内部实现映射潜在变量为默认状态,并计算相应的损失。模拟后,creditDefaultCopula对象填充PortfolioLosses和CounterpartyLosses性能与仿真结果吻合。
CC =模拟(CC,1E5);DISP(CC)
creditDefaultCopula与属性:组合:[100x5表] FactorCorrelation:[2×2双] VaRLevel:0.9900 UseParallel:0 PortfolioLosses:[1x100000双]
该portfolioRisk函数返回总投资组合损失分布的风险度量,以及它们各自的置信区间(可选)。属性中设置的级别报告风险值(VaR)和条件风险值(CVaR)VaRLevel属性为creditDefaultCopula宾语。
[公关,pr_ci] = portfolioRisk (cc);fprintf中(“投资组合风险措施:\ n”);DISP(PR)fprintf中('\ n \ nConfidence区间的风险的措施:\ n');DISP(pr_ci)
投资组合风险的措施:EL标准的VaR CVaR的______ ______ _____ ______ 24.876 23.778 102.4 121.28的风险的措施置信区间:EL标准的VaR CVaR的________________ ________________ ________________ ________________ 24.729 25.023 23.674 23.883 101.19 103.5 120.13 122.42
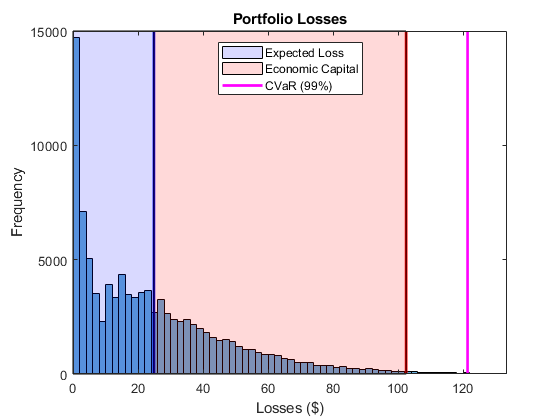
看看投资组合的损失分布。预期的损耗(EL),var和CVaR的被标记为垂直线。经济资本,通过风险价值与EL之间的差给出,显示为EL和VAR的阴影区域。
直方图(cc.PortfolioLosses)标题(“投资组合损失”);xlabel('损失($)')ylabel('频率')保持上在直方图上叠加风险度量。XLIM([0 1.1 * pr.CVaR])的plotline = @(X,颜色)情节([X X],ylim,“线宽”2,'颜色'、颜色);情节(pr.EL'B');情节主线(pr.VaR,'R');cvarline =情节主线(pr.CVaR,'M');%的遮阳预期损失和经济资本的领域。plotband = @(x,color) patch([x fliplr(x)],[0 0 repmat(max(ylim),1,2)],...颜色,'FaceAlpha',0.15);elband = plotband([0 pr.EL]),“蓝”);ulband = plotband([pr.EL pr.VaR]'红色');图例([elband,ulband,cvarline]...{“预期损失”,“经济资本”,'CVaR的(99%)'},...'位置','北');
找到交易对手集中风险
您可以成为投资组合的集中度风险riskContribution函数。riskContribution返回每个交易对手对投资组合EL和CVaR的贡献。这些附加的贡献对相应的组合风险度量的总和。
rc = riskContribution (cc);%的风险贡献报道EL和CVaR的。RC(1:5,:)
ANS = 5x5的表ID EL标准的VaR CVaR的__ ________ __________ _________ _________ 1 0.036031 0.022762 0.083828 0.13625 0.068357 2 0.039295 0.23373 0.24984 3 1.2228 0.60699 2.3184 2.3775 4 0.002877 0.00079014 0.0024248 0.0013137 5 0.12127 0.037144 0.18474 0.24622
通过CVaR贡献找出风险最高的交易对手。
[rc_sorted, idx] = sortrows (rc,'CVaR的',“下”);:rc_sorted (1:5)
ANS = 5x5的表ID EL标准的VaR CVaR的__ _______ ______ ______ 89 2.2647 2.2063 8.2676 8.9997 96 1.3515 1.6514 6.6157 7.7062 66 0.90459 1.474 6.4168 7.5149 22 1.5745 1.8663 6.0121 7.3814 16 1.6352 1.5288 6.3404 7.3462
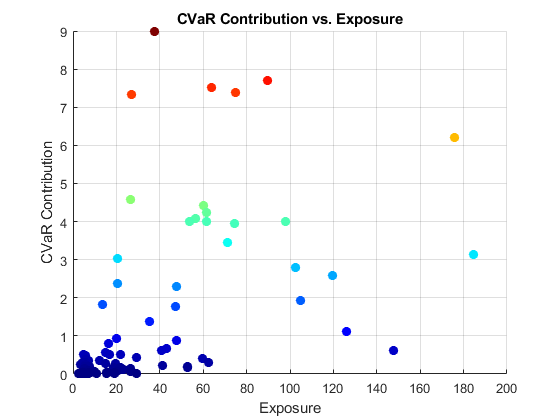
绘制交易对手风险敞口和CVaR贡献。CVaR贡献最高的交易对手方用红色和橙色标出。
图;的pointsize = 50;colorVector = rc_sorted.CVaR;散射(cc.Portfolio(IDX,:)。EAD,rc_sorted.CVaR,...的pointsize,colorVector,'填充')colormap (“喷气机”)标题(“CVaR的贡献与曝光”)xlabel('接触')ylabel(“CVaR的贡献”网格)上
研究具有置信带的仿真收敛性
使用confidenceBands函数的收敛性研究。默认情况下,报告CVaR置信区间,但是使用可选的支持所有风险度量的置信区间万博1manbetxRiskMeasure论点。
CB = confidenceBands(CC);%的置信带都存储在表中。cb (1:5,:)
表1.表2 .表3 .表3 .表3 .表4.表3 .表4.表3 .表4.表4.表4.表5.表4.表5.表4.表5
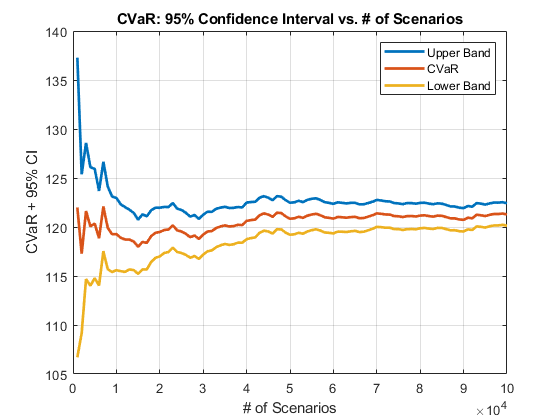
绘制置信区间,看看估计收敛的速度有多快。
图;情节(...cb.NumScenarios,...CB {:,{“上”'CVaR的'“低”}},...“线宽”,2);标题(“CVaR的:情景的95%置信区间对#”);xlabel(“场景#”);ylabel('CVaR的+ 95%CI')传说(“上乐队”,'CVaR的',“较低的乐队”);网格上
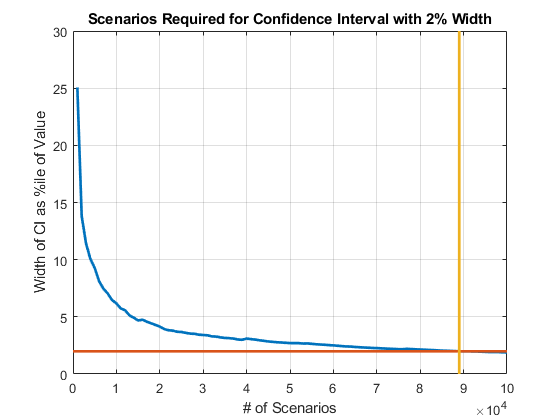
查找的场景必要数量达到置信带的特定宽度。
宽度=(cb.Upper - cb.Lower)./ cb.CVaR;图;情节(cb.NumScenarios,宽度* 100,“线宽”,2);标题('CVaR: 95%置信区间宽度vs.场景# ');xlabel(“场景#”);ylabel(“CI宽度为值的%ile”网格)上找到置信区间在…的1%(两侧)以内的点%CVaR的。THRESH = 0.02;scenIdx =查找(宽度<= THRESH,1,“第一”);scenValue = cb.NumScenarios (scenIdx);widthValue =宽度(scenIdx);保持上plot(xlim,100 * [widthValue widthValue],...[scenValue scenValue],ylim,...“线宽”,2);标题(“2%宽度的置信区间所需的场景”);
比较高斯分布和ŤCopula函数
切换到Ť系词增加交易对手的违约相关性。这导致的投资组合损失胖尾分布,并在强调场景更高的潜在损失。
使用a重新运行模拟Ť系词与计算新的投资组合风险的措施。为默认的自由度(DOF)的Ť连系动词是5。
cc_t =模拟(cc, 1 e5,连系动词的,'T');pr_t = portfolioRisk (cc_t);
查看投资组合风险如何随Ť系词。
fprintf中(“投资组合风险与高斯系词:\ n”);DISP(PR)fprintf中('\ n \ nPortfolio风险与叔系词(DOF = 5):\ N');DISP(pr_t)
组合风险与高斯连接函数:EL标准的VaR CVaR的______ ______ _____ ______ 24.876 23.778 102.4 121.28用叔系词组合风险(DOF = 5):EL标准的VaR CVaR的______ ______ ______ ______ 24.808 38.749 186.08 250.59
比较每个模型的尾部损失。
%画出高斯系词尾巴。图;subplot(2,1,1) p1 = histogram(cc.PortfolioLosses);保持上情节主线(pr.VaR,[1 0.5 0.5]) plotline(pr.CVaR,[1 0 0]) xlim([0.8 * pr.VaR 1.2 * pr_t.CVaR]); ylim([0 1000]); grid上传奇(损失分布的,“风险价值”,'CVaR的')标题(图集损失与高斯系词“);xlabel('损失($)');ylabel('频率');%画出吨系动词尾巴。副区(2,1,2)P2 =直方图(cc_t.PortfolioLosses);保持上情节主线(pr_t.VaR,[1 0.5 0.5])的plotline(pr_t.CVaR,[1 0 0])XLIM([0.8 * pr.VaR 1.2 * pr_t.CVaR]);ylim (1000 [0]);网格上传奇(损失分布的,“风险价值”,'CVaR的');标题(图集损失用叔系词(DOF = 5)');xlabel('损失($)');ylabel('频率');
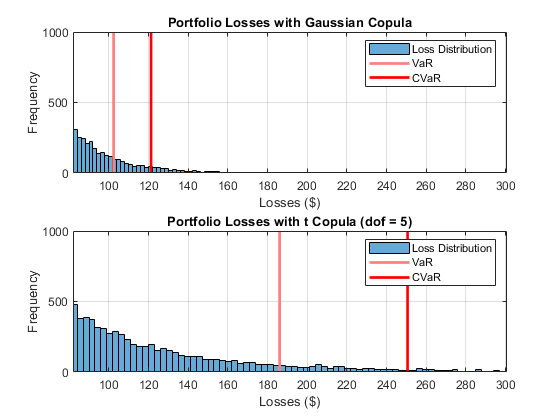
尾部风险指标VaR和CVaR显著高于使用Ť有五个自由度的联结。默认的相关性更高Ť因此,存在更多交易对手违约的情况。自由度的多少起着重要的作用。对于非常高的自由度,结果是ŤCopula函数是类似于高斯系词的结果。五是自由度的一个非常低的数字,并且必然,结果显示显着的差异。此外,这些结果强调,对于极端损失的可能性是系词的选择自由度的数量非常敏感。
您还可以选择从下面的列表中的网站: