向量操作优化
此示例显示了Simulink®Coder™如何万博1manbetx通过设置为标量生成向量的块输出来优化生成的代码。这种优化通过用局部变量替换临时本地阵列来减少堆栈内存。
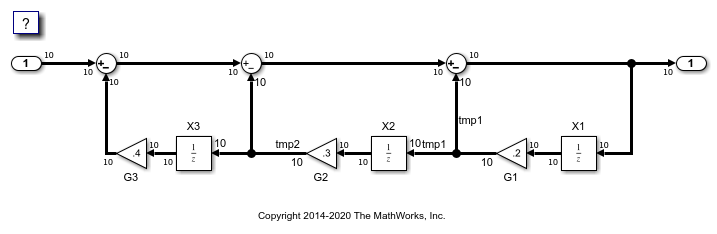
示例模型
在模型中RTWDEMO_VECTOROPTIMIATION,增益块的输出G1和G2是向量信号TMP1和TMP2。这些向量的宽度为10。
模型='rtwdemo_vectorOptimization';Open_System(模型);set_param(型号,“仿真”,,,,'更新')
生成代码
为构建和检查过程创建一个临时文件夹(在您的系统临时文件夹中)。
CurrentDir = PWD;[〜,cgdir] = rtwdemodir();
构建模型。
Slbuild(型号)
###启动构建过程:rtwdemo_vectorOptimization ###成功完成构建过程的完成过程:rtwdemo_vectorOptimization构建摘要摘要摘要最高模型目标:模型动作重建原因=================================================================================================================================。1个型号中的1个型号(0个模型已经最新)构建持续时间:0H 0M 14.009S
优化的代码在rtwdemo_vectoroptimization.c。信号TMP1和TMP2是本地变量RTB_TMP1和RTB_TMP2。
cfile = fullfile(cgdir,'rtwdemo_vectoroptimization_grt_rtw',,,,...'rtwdemo_vectoroptimization.c');rtwdemodbtype(cfile,'/*模型步骤',,,,'/*模型初始化',1,0);
/ *模型步骤函数 */ void rtwdemo_vectoroptimization_step(void){real_t rtb_sum3;real_t rtb_tmp1;real_t rtb_tmp2;int32_t i;for(i = 0; i <10; i ++){/ *增益:'/g2'并入: * unitdelay:'/x2' */rtb_tmp2 = 0.3 * rtwdemo_vectoroptimization_dw.x2_dstate [i];/ *增益:'/g1'并入: * unitdelay:'/x1' */rtb_tmp1 = 0.2 * rtwdemo_vectoroptimization_dw.x1_dstate [i];/ * sum:'/sum3'并入: *增益:'/g3' * inport:'/in2' * sum:'/sum1' * sum:'/sum2' * unitdelay:'/x3' */rtb_sum3 =(((rtwdemo_vectoroptimization_in2 [i] - 0.4 * rtwdemo_vectoroptimization_dw.x3_dstate [i]) -/ * outport:'/out2' */rtwdemo_vectoroptimization_y.out2 [i] = rtb_sum3;/ * unitdelay的更新:'/x3' */rtwdemo_vectoroptimization_dw.x3_dstate [i] = rtb_tmp2; /* Update for UnitDelay: '/X2' */ rtwdemo_VectorOptimization_DW.X2_DSTATE[i] = rtb_tmp1; /* Update for UnitDelay: '/X1' */ rtwdemo_VectorOptimization_DW.X1_DSTATE[i] = rtb_Sum3; } }
关闭模型和代码生成报告。
bdclose(型号)rtwdemoclean;CD(CurrentDir)
相关话题
您还可以从以下列表中选择一个网站:
美洲
- AméricaLatina(Español)
- 加拿大(英语)
- 美国(英语)