评估回归神经网络性能
利用全连接层创建前馈回归神经网络模型fitrnet.使用验证数据早期停止训练过程,以防止模型过拟合。然后,利用模型的对象函数对测试数据进行性能评估。
加载示例数据
加载carbig数据集,其中包含20世纪70年代和80年代初生产的汽车的测量数据。
负载carbig
转换起源变量变为分类变量。然后创建一个包含预测变量的表加速度,位移,等等,以及响应变量英里/加仑.每一行包含单个汽车的度量值。
起源=分类(cellstr(起源));台=表(加速度、位移、马力、...Model_Year、产地、重量、MPG);
对数据进行分区
将数据分解为训练、验证和测试集。首先,为测试集保留大约三分之一的观测值。然后,将剩余的数据分成两半,以创建训练和验证集。
rng (“默认”)%用于数据分区的再现性cvp1 = cvpartition(大小(1台),“坚持”, 1/3);testTbl =台(测试(cvp1):);remainingTbl =(资源(培训(cvp1):);cvp2 = cvpartition(大小(remainingTbl, 1),“坚持”1/2);validationTbl = remainingTbl(测试(cvp2):);trainTbl = remainingTbl(培训(cvp2):);
训练神经网络
利用训练集训练回归神经网络模型。指定英里/加仑列的tblTrain作为响应变量,并标准化数值预测器。在每次迭代中使用验证集评估模型。属性指定在每个迭代中显示训练信息详细的名称-值参数。默认情况下,如果验证损失大于或等于迄今为止计算的最小验证损失(连续六次),则训练过程提前结束。要更改允许验证丢失大于或等于最小值的次数,请指定ValidationPatience名称-值参数。
Mdl = fitrnet (trainTbl,“英里”,“标准化”,真的,...“ValidationData”validationTbl,...“详细”1);
|==========================================================================================| | 迭代| |火车损失梯度| | | |一步迭代验证验证 | | | | | | 时间(秒)| |检查损失 | |==========================================================================================| | 1 | 71.063537 | 22.623354 | 6.466959 |0.001272 | 72.648960 | 0 | | 2 | 48.608700 | 22.384995 | 1.022929 | 0.001808 | 43.435698 | 0 | | 3 | 30.584887 | 13.433471 | 0.537190 | 0.000903 | 29.134447 | 0 | | 4 | 17.781636 | 11.159801 | 1.401355 | 0.000461 | 16.542207 | 0 | | 5 | 13.075804 | 4.605991 | 0.419875 | 0.000387 | 12.946670 | 0 | | 6 | 11.697936 | 3.197944 | 0.226945 | 0.000543 | 12.025502 | 0 | | 7 | 9.494801 |2.269831 | 0.751711 | 0.000452 | 12.596499 | 1 | | 8 | 8.390979 | 1.970589 | 0.337301 | 0.000398 | 11.490990 | 0 | | 9 | 6.853097 | 1.029078 | 0.866974 | 0.000378 | 9.449945 | 0 | | 10 | 6.531678 | 0.924820 | 0.306913 | 0.000429 | 9.350721 | 0 | |==========================================================================================| | 迭代梯度| | |火车损失Step | Iteration | Validation | Validation | | | | | | Time (sec) | Loss | Checks | |==========================================================================================| | 11| 6.152995| 1.872684| 0.457744| 0.000403| 9.223829| 0| | 12| 5.924852| 0.718386| 0.447879| 0.000402| 9.656166| 1| | 13| 5.792836| 0.500170| 0.216351| 0.000387| 9.733226| 2| | 14| 5.613473| 1.151197| 0.316828| 0.000531| 9.788646| 3| | 15| 5.415889| 1.513493| 0.327937| 0.000485| 9.607953| 4| | 16| 5.008195| 1.398069| 1.085660| 0.000430| 9.251971| 5| | 17| 5.004176| 2.070041| 0.890201| 0.000383| 8.719334| 0| | 18| 4.738386| 0.483667| 0.338897| 0.000374| 8.523728| 0| | 19| 4.680213| 0.437918| 0.107667| 0.000371| 8.369271| 0| | 20| 4.587350| 0.510639| 0.146276| 0.000385| 8.100236| 0| |==========================================================================================| | Iteration | Train Loss | Gradient | Step | Iteration | Validation | Validation | | | | | | Time (sec) | Loss | Checks | |==========================================================================================| | 21| 4.479929| 0.565635| 0.228198| 0.000381| 8.062927| 0| | 22| 4.380618| 0.892717| 0.377776| 0.000554| 7.843234| 0| | 23| 4.189344| 0.403227| 0.362307| 0.000434| 7.834582| 0| | 24| 4.182775| 1.150234| 1.908768| 0.000408| 9.436226| 1| | 25| 3.985939| 0.908479| 0.518217| 0.000570| 8.973756| 2| | 26| 3.873835| 0.826655| 0.477740| 0.000505| 8.863599| 3| | 27| 3.830830| 0.331936| 0.220000| 0.000539| 8.574682| 4| | 28| 3.796605| 0.232756| 0.075643| 0.000492| 8.591758| 5| | 29| 3.706326| 0.470116| 0.249292| 0.000396| 8.517317| 6| |==========================================================================================|
使用内部的信息TrainingHistory对象的属性Mdl检验最小验证均方误差(MSE)对应的迭代。最终返回的模型Mdl是在此迭代中训练的模型。
迭代= Mdl.TrainingHistory.Iteration;valLosses = Mdl.TrainingHistory.ValidationLoss;[~, minIdx] = min (valLosses);迭代(minIdx)
ans = 23
评估测试集性能
评估训练模型的表现Mdl在测试集中testTbl通过使用损失和预测对象的功能。
计算测试集均方误差(MSE)。MSE值越小,性能越好。
mse =损失(Mdl testTbl,“英里”)
mse = 25.4145
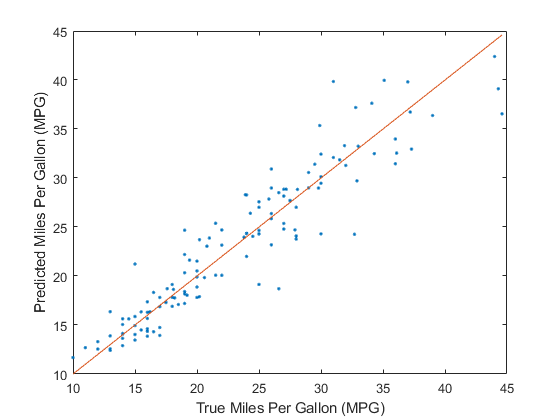
将预测的测试集响应值与真实响应值进行比较。在纵轴上画出预测的每加仑英里数(MPG),在横轴上画出真实的每加仑英里数。基准线上的点表示正确的预测。一个好的模型会产生分散在线附近的预测。
testTbl predictedY =预测(Mdl);情节(testTbl。英里/加仑,预测edY,“。”)举行在情节(testTbl.MPG testTbl.MPG)从包含(“每加仑实际行驶里程(MPG)”) ylabel (“每加仑预计行驶里程(MPG)”)
使用箱形图来比较预测的MPG值和真实的MPG值在原产国的分布。创建盒状图使用boxchart函数。每个框图显示中值、上、下四分位数、任何异常值(使用四分位数区间计算),以及非异常值的最小值和最大值。具体来说,每个框内的线是样本的中值,圆形标记表示离群值。
对于每个原产国,比较红方框图(显示预测MPG值的分布)和蓝方框图(显示真实MPG值的分布)。预测的MPG值和真实MPG值的分布相似,表明预测结果很好。
boxchart (testTbl.Origin testTbl.MPG)在boxchart (testTbl.Origin predictedY)从传奇([“真正的MPG”,“预测MPG”])包含(“原产国”) ylabel (每加仑英里数(MPG))

对于大多数国家,预测的MPG值和真实MPG值有相似的分布。然而,神经网络模型往往低估了法国制造汽车的MPG值。这种差异可能是由于法国车在训练和测试集的数量很少。
比较范围的MPG值为法国汽车在训练和测试集。
trainSummary = grpstats (trainTbl (:,“英里”,“起源”]),“起源”,...[“最小值”,“马克斯”])
trainSummary =6×4表Origin GroupCount min_MPG max_MPG _______ __________ _______ _______法国法国3 16.2 27德国德国11 20 44.3意大利意大利1 37.3 37.3日本日本24 20 40.8瑞典瑞典3 19 21.6美国美国94 9 39
testSummary = grpstats (testTbl (:,“英里”,“起源”]),“起源”,...[“最小值”,“马克斯”])
testSummary =6×4表Origin GroupCount min_MPG max_MPG _______ __________ _______ _______法国法国3 28.1 40.9德国德国12 21.5 44意大利意大利3 28 30日本日本32 18 46.6瑞典瑞典3 17 24美国82 10 36.1
在训练集中,法国制造的汽车的MPG值在16.2到27之间。然而,在测试中,法国制造的汽车的MPG值在28.1到40.9之间。
绘制测试集的残差。一个好的模型通常有残差大致对称地散布在0附近。清晰的残差模式表明你可以改进你的模型。
残差= testTbl。MPG - predictedY;情节(testTbl。英里/加仑,residuals,“。”)举行在yline (0)从包含(“每加仑实际行驶里程(MPG)”) ylabel (“MPG残差”)

从图中可以看出,一些残值是异常值。找出关于最大残差观测的更多信息。
[outlierResidual, outlierIdx] = max(残差)
outlierResidual = 37.8727
outlierIdx = 113
testTbl (outlierIdx:)
ans =表1×7加速度位移马力Model_Year起源体重MPG ____________ ____________ __________ __________ ______ ______ ____ 17.3 85年南80年法国1835年40.9
这个观察结果与一辆马力价值缺失,以及其原籍国是法国,这是一个很少观察到的类别。
另请参阅
你也可以从以下列表中选择一个网站:
