选择用于分类高维数据的特征
这个示例展示了如何选择对高维数据进行分类的特性。更具体地讲,它展示了如何进行序列特征选择,这是最流行的特征选择算法之一。它还展示了如何使用坚持和交叉验证来评估所选特性的性能。
在统计学习中,减少特征的维数是非常重要的。对于许多特征量大而观测量有限的数据集,如生物信息学数据,通常许多特征对于产生期望的学习结果是没有用的,有限的观测量可能导致学习算法对噪声过度拟合。减少特性还可以节省存储和计算时间,增加可理解性。
主要有两种方法来减少特点:特征选择和特征变换。特征选择算法选择的从原始特征集的特征的子集;特征的转化方法从原始高维特征空间的变换数据与维数降低了新的空间。
加载数据
血清蛋白质组学诊断模式可以从患者和无病来区分不同的意见。资料模式是使用表面增强激光解吸和电离(SELDI)蛋白质质谱生成。这些功能是在特定的质量/电荷值的离子强度水平。
本例中的数据是从FDA-NCI临床蛋白质组学计划数据库。此示例使用是使用WCX2蛋白质阵列产生高分辨率卵巢癌的数据集。经过一些预处理步骤,类似于在生物信息工具箱™示例中所示的那些预处理原始质谱数据,该数据集有两个变量OBS和GRP。的OBS变量由216个观测与4000层的功能。中的每个元素GRP的对应行所对应的组OBS属于。
加载卵巢癌;谁
名称大小字节类属性grp 216x1 26784单元obs 216x4000 3456000单
将数据划分为训练集和测试集
本例中使用的一些函数调用MATLAB®内置随机数生成函数。要复制本例中显示的结果,请执行下面的命令将随机数生成器设置为已知状态。否则,结果可能会有所不同。
RNG(8000,“旋风”);
训练数据(resubstitution性能)的表现不是一个模型的一个独立测试集性能较好的估计。Resubstitution性能通常会过于乐观。为了预测所选模型的性能,你需要评估其对不用于构建模型的另一个数据集的性能。在这里,我们使用cvpartition到数据划分成大小160的训练集和测试集大小56无论是训练集和测试集的大小的具有大致相同的基团的比例在GRP。我们使用训练数据选择特征,并判断所选择的特征在测试数据上的性能。这通常称为坚持验证。另一个用于评估和选择模型的简单和广泛使用的方法是交叉验证,这将在后面的例子中说明。
holdoutCVP = cvpartition(GRP,'坚持'56)
holdoutCVP = holdoutCVP = holdoutCVP = holdoutCVP = holdoutCVP = holdoutCVP = holdoutCVP = holdoutCVP = holdoutCVP = holdoutCVP = holdoutCVP
奥林匹克广播服务公司(dataTrain = holdoutCVP.training:);grpTrain = grp (holdoutCVP.training);
使用所有特征对数据进行分类的问题
不首先降低的特征的数量,一些分类算法将失败在该实施例中使用的数据集,因为特征的数量比观测值的数量大得多。在这个例子中,我们使用二次判别分析(QDA)作为分类算法。如果我们使用的所有功能,如下面所示的数据应用QDA,我们会因为没有足够的样本各组估计协方差矩阵得到一个错误。
试一试yhat = classification (obs(test(holdoutCVP),:), dataTrain, grpTrain,“二次”);抓住我显示(ME.message);结束
训练中每组的协方差矩阵必须是正的。
使用简单的筛选方法选择特性
我们的目标是通过找出一小部分重要的特征,可以提供良好的分类性能,以减少数据的维度。特征选择算法可以被粗略地分为两类:过滤器的方法和包装方法。筛选方法依赖于数据的一般特性评估和选择功能的子集,而不涉及所选择的学习算法(QDA在这个例子中)。包装方法使用所选择的学习算法的性能来评估每个候选特征的子集。包装方法搜索功能,更适合选择的学习算法,但如果学习算法需要较长的时间来运行他们可以显著慢于过滤器的方法。的“过滤器”和“包装”的概念在约翰G. Kohavi R.(1997)“为包装器的特征子集选择”,人工智能,Vol.97,第1-2期,pp.272-324中描述。这个例子中示出了过滤器的方法的一个实例和包装方法的一个实例。
过滤器通常用作预处理步骤,因为它们简单和快速。生物信息学数据筛选的一种常用方法是在假设特征之间不存在交互作用的情况下,对每个特征分别应用单变量准则。
例如,我们可以应用t- 测试每个功能和比较p的绝对值t-统计)为每个特性,以衡量其在分组时的有效性。
dataTrainG1 = dataTrain(grp2idx(grpTrain)== 1,:);dataTrainG2 = dataTrain(grp2idx(grpTrain)== 2,:);[H,P,Cl,STAT] = ttest2(dataTrainG1,dataTrainG2,'VARTYPE',“不平等”);
为了得到一个大致的概念,如何很好地分开两组的每个特征,我们绘制的经验累积分布函数(CDF)p- 值:
ecdf (p);包含(“P值”);ylabel (“提供价值”)
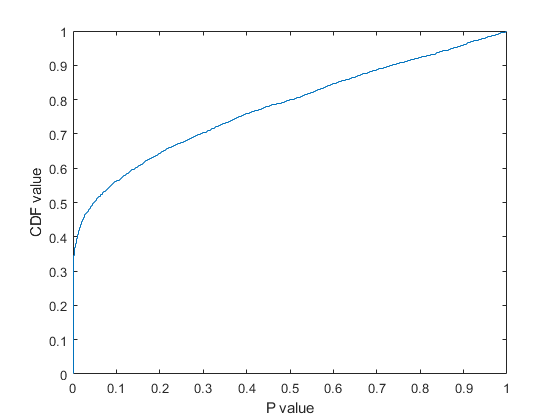
大约有35%的功能p- 值接近于零和特征的超过50%的具有p- 值小于0.05,也就是说有原来的5000个功能,具有较强的判别力中超过2500层的功能。人们可以根据这些特点的排序p- 值(或的绝对值t-统计)和选择一些功能从排序列表。然而,通常很难决定需要多少特性,除非一个人拥有一些领域知识,或者可以考虑的最大特性数量已经根据外部约束提前确定。
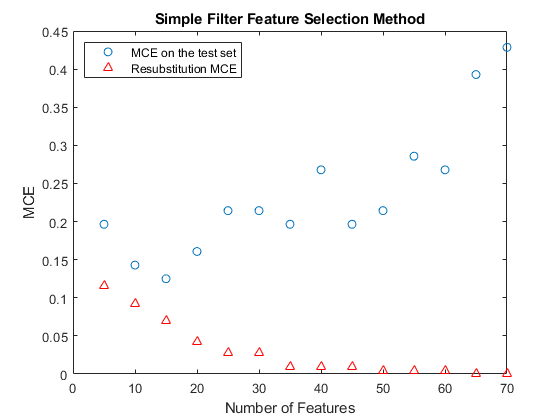
一个快速的方式来决定所需特征的数量绘制MCE(误分,即,错误分类观测由观测值的数量所得的值)在测试集合作为特征的数量的函数。由于只有160在训练组观察,特征的用于施加QDA限于最大数目,否则,可能不存在足够的样本各组来估计协方差矩阵。实际上,在这个例子中使用的数据,坚持分区和两个组的大小决定了的功能为应用QDA所允许的最大数量约为70现在我们计算MCE 5和70,并显示之间的各种数字功能MCE的情节一样的特征数量的功能。为了合理地估计所选择的模型的性能,它是使用160个训练样本,以适应QDA模型并计算在56个测试观测MCE(在下面的曲线图蓝色的圆形标记)重要。为了说明为什么resubstitution误差不测试误差的一个很好的误差估计,我们也用红色三角标志显示resubstitution MCE。
[~,featureIdxSortbyP] = (p, 2);对特征进行排序testMCE = 0 (1、14);resubMCE = 0 (1、14);nfs = 5:5:70;classf = @ (xtrain、ytrain xtest、欧美)…总和(~ strcmp(欧美、分类(xtest、xtrain ytrain,“二次”)));resubCVP = cvpartition(长度(grp),“resubstitution”)对于fs = featureIdxSortbyP(1:nfs(i));testMCE (i) = crossval (classf突发交换(:,fs), grp,“分区”holdoutCVP)…/holdoutCVP.TestSize;resubMCE(ⅰ)= crossval(classf,观测值(:,FS),GRP,“分区”,resubCVP)/…resubCVP.TestSize;结束情节(nfs、testMCE“o”nfs resubMCE,“r ^”);包含(特征的数量);ylabel (“乎”);传奇({"测试集的MCE "'Resubstitution MCE'},'位置',“西北”);标题(“简单滤镜特征选择方法”);
NumObservations: 216 NumTestSets: 1 TrainSize: 216 TestSize: 216
为了方便起见,classf定义为匿名函数。它将QDA与给定的训练集相匹配,并返回给定测试集错误分类的样本数量。如果你正在开发自己的分类算法,你可能需要将它放在单独的文件中,如下所示:
%函数ERR = classf(xtrain,ytrain,XTEST,ytest)%yfit =分类(XTEST,xtrain,ytrain, '二次');= sum(~strcmp(ytest,yfit));
MCE的重新替代过于乐观了。当使用更多的特性时,它会持续下降,当使用超过60个特性时,它会下降到零。但是,如果测试误差增大,而替换误差仍然减小,则可能发生过拟合。当使用15个特征时,这个简单的过滤器特征选择方法在测试集中得到最小的MCE。图中显示,当使用20个或更多特征时,开始出现过拟合。测试集上最小的MCE为12.5%:
testMCE (3)
ans = 0.1250
这些是前15个功能,实现最低MCE:
featureIdxSortbyP(1:15)
ANS =列1至6 2814 2813 2721 2720 2452 2645列7到12 2644 2642 2650 2643 2731 2638列13至15 2730 2637 2398
应用顺序特征选择
上述特征选择算法没有考虑特征之间的相互作用;此外,根据个体排名从列表中选择的特征也可能包含冗余信息,因此并不需要所有的特征。例如,第一个特征(列2814)与第二个特征(列2813)之间的线性相关系数接近0.95。
科尔(dataTrain(:,featureIdxSortbyP(1)),dataTrain(:,featureIdxSortbyP(2)))
ans =单因素0.9447
这种简单的特征选择过程通常被用作预处理步骤,因为它是快速。更高级的特征选择算法,提高了性能。顺序特征选择是使用最广泛的技术之一。它通过依次加入(向前检索)或移除(向后搜索),直到某个停止条件成立时选择的功能的子集。
在这个例子中,我们使用着连续的特征选择的包装方式找到重要特征。更具体地说,由于分类的典型目标是最小化的MCE,特征选择程序执行使用关于每个候选特征的子集,作为该子集的性能指标学习算法QDA的MCE顺序搜索。训练集是用来选择功能,并符合QDA模型,测试集用于评估最终选择功能的性能。在特征选择过程中,评估和比较各候选特征子集的性能,我们采用分层10倍交叉验证训练集。稍后我们将说明为什么采用交叉验证训练集是非常重要的。
首先,我们生成了训练集的分层10倍分区:
tenfoldCVP = cvpartition (grpTrain,'kfold',10)
tenfoldCVP = K-fold交叉验证分区NumObservations: 160 NumTestSets: 10 TrainSize: 144 144 144 144 144 144 144 144 144 144 144 TestSize: 16 16 16 16 16 16 16 16 16 16 16 16 16 16 16 16 16 16 16 16 16 16 16
然后,我们使用的过滤器的结果从上一节作为预处理步骤来选择的功能。例如,我们在这里选择150层的特点:
fs1 = featureIdxSortbyP (1:15);
我们对这150个特征进行了正向序列特征选择。这个函数sequentialfs提供了一种简单的方式(默认选项)来决定有多少功能是必要的。当交叉验证MCE的第一极小发现它停止。
fsLocal = sequentialfs (classf dataTrain (:, fs1) grpTrain,“简历”,tenfoldCVP);
所选择的特征如下:
fs1 (fsLocal)
ANS = 2337 864 3288
为了评估这三个功能选择模型的性能,我们计算的56个试验样品的MCE。
testMCELocal = crossval(classf,观测值(:,FS1(fsLocal)),GRP,“分区”,…holdoutCVP) / holdoutCVP.TestSize
testMCELocal = 0.0714
只有三个特征被选择,MCE仅仅是最小的MCE的一半多一点使用简单的过滤器特征选择方法。
算法可能已经提前停止。有时,通过在合理的特性数量范围内寻找最小的交叉验证MCE,可以实现更小的MCE。例如,我们绘制了交叉验证MCE的图,将其作为50个特性的特性数量的函数。
[fsCVfor50, historyCV] = sequentialfs (classf dataTrain (:, fs1) grpTrain,…“简历”tenfoldCVP,“Nf”,50);情节(historyCV.Crit“o”);包含(特征的数量);ylabel (“简历多国评价”);标题(“交叉验证的正向顺序特征选择”);
交叉验证MCE在使用10个特性时达到最小值,该曲线在10个特性到35个特性的范围内保持平稳。此外,当使用超过35个特征时,曲线会上升,这意味着该区域出现过拟合。
通常,优选具有更少的功能,所以在这里我们选择10周的特点:
:fsCVfor10 = fs1 (historyCV.In(10日))
fsCVfor10 =列1到6 2814 2721 2720 2452 2650 2731列7到10 2337 2658 864 3288
为了按照顺序正向过程中选择的顺序显示这10个特性,我们找到它们在historyCV输出:
[orderlist,ignore] =查找([historyvi . (1,:);diff (historyCV.In (1:10,:))]);fs1 (orderlist)
ans =列1到6 2337 864 3288 2721 2814 2658列7到10 2452 2731 2650 2720
为了评估这些10层的功能,我们计算的测试集他们对QDA MCE。我们得到最小的MCE值为止:
testMCECVfor10 = crossval (classf突发交换(:,fsCVfor10)、grp,“分区”,…holdoutCVP) / holdoutCVP.TestSize
testMCECVfor10 = 0.0357
它看resubstitution MCE值的训练集积(即,没有特征选择过程期间执行交叉验证)为特征的数量的函数是有趣:
[fsResubfor50, historyResub] = sequentialfs (classf dataTrain (:, fs1),…grpTrain,“简历”,“resubstitution”,“Nf”,50);图(1:50,historyCV.Crit,“波”1:50 historyResub.Crit,“r ^”);包含(特征的数量);ylabel (“乎”);传奇({'10倍CV MCE”'Resubstitution MCE'},'位置',“不”);
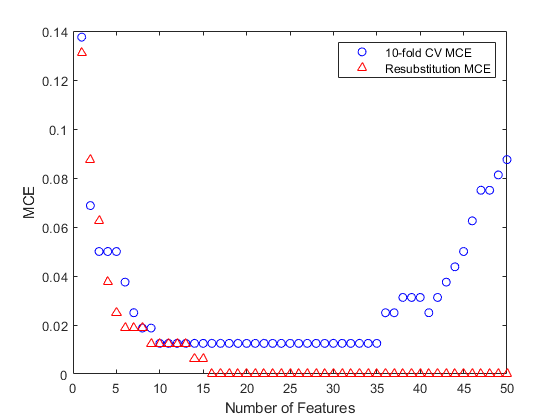
同样,resubstitution MCE值是过于乐观了这里。大多数比交叉验证MCE值小,并且当使用16个特征的resubstitution MCE变为零。我们可以计算对测试集这些功能16的MCE值,看看他们真正的性能:
:fsResubfor16 = fs1 (historyResub.In (16));testMCEResubfor16 = crossval (classf突发交换(:,fsResubfor16)、grp,“分区”,…holdoutCVP) / holdoutCVP.TestSize
testMCEResubfor16 = 0.0714
testMCEResubfor16,这些16点的特征(所述特征选择过程期间由resubstitution选择)上测试集的性能,是大约两倍于testMCECVfor10,的10个功能的性能在测试组(通过选择10倍的特征选择过程期间交叉验证)。这再次表明,resubstitution误差一般不用于评估和选择功能,良好的性能估计。我们可能希望避免使用resubstitution错误,不仅在最后的评估步骤,也是特征选择过程中。
