用广义线性模型拟合数据
此示例显示如何使用和评估广义的线性模型使用glmfit.和glmval.。普通的线性回归可用于适合直线,或者在其参数中线性的任何功能,以具有正常分布错误的数据。这是最常用的回归模型;但是,它并不总是一个现实的。广义线性模型以两种方式扩展线性模型。首先,通过引入链接功能,放宽参数中的线性度的假设。第二,可以建模正常的错误分布
广义线性模型
回归模型在一个或多个预测器变量方面定义响应变量(通常是y)的响应变量的分布(通常表示x1,x2等)。最常用的回归模型,普通线性回归,模型y作为正常随机变量,其平均值是预测器的线性函数,B0 + B1 * x1 + ...,其方差是恒定的。在单个预测器x的最简单情况下,该模型可以表示为与每个点的高斯分布的直线。
mu = @(x)-1.9 + .23 * x;x = 5:.1:15;yhat = mu(x);dy = -3.5:.1:3.5;sz =尺寸(dy);k =(长度(dy)+1)/ 2;x1 = 7 * x1(sz);Y1 = mu(x1)+ dy;z1 = normpdf(y1,mu(x1),1);x2 = 10 *那些(sz); y2 = mu(x2)+dy; z2 = normpdf(y2,mu(x2),1); x3 = 13*ones(sz); y3 = mu(x3)+dy; z3 = normpdf(y3,mu(x3),1); plot3(x,yhat,zeros(size(x)),“b -”那......X1,Y1,Z1,'r-',X1([k K]),Y1([k k]),[0 z1(k)],'r:'那......X2,Y2,Z2,'r-',X2([k]),Y2([k]),[0 Z2(k)],'r:'那......X3,Y3,Z3,'r-',x3([k k]),y3([k k]),[0 z3(k)],'r:');zlim([01]);Xlabel('X');ylabel('是');Zlabel('概率密度');网格在;视图(45 [-45]);

在广义线性模型中,响应的均值被建模为预测器g(b0 + b1*x1 +…)的线性函数的单调非线性变换。变换g的逆称为“连杆”函数。示例包括logit (sigmoid)链接和log链接。y也可以是非正态分布,如二项分布或泊松分布。例如,具有对数链接和单个预测器x的泊松回归可以表示为每一点具有泊松分布的指数曲线。
mu = @(x)exp(-1.9 + .23 * x);x = 5:.1:15;yhat = mu(x);x1 = 7 *那些(1,5);Y1 = 0:4;z1 = poisspdf(y1,mu(x1));x2 = 10 * x2(1,7);Y2 = 0:6;z2 = poisspdf(y2,mu(x2));X3 = 13 *那些(1,9); y3 = 0:8; z3 = poisspdf(y3,mu(x3)); plot3(x,yhat,zeros(size(x)),“b -”那......[x1;X1],[Y1;Y1],[Z1;零(尺寸(y1))],'r-',x1,y1,z1,'r。'那......[x2;X2],[Y2;Y2],[Z2;零(尺寸(y2))],'r-',x2,y2,z2,'r。'那......[x3;x3],[Y3;Y3],[Z3;零(尺寸(y3))],'r-',x3,y3,z3,'r。');zlim([01]);Xlabel('X');ylabel('是');Zlabel('可能性');网格在;视图(45 [-45]);

适合逻辑回归
此示例涉及实验,以帮助模拟失效的各种重量的汽车比例。数据包括检测的观察,所测试的汽车数量,并且数字失败。
%一组汽车重量重量= [2100 2300 2500 2700 2900 3100 3300 3500 3700 3900 4100 4300]'%在每次重量测试的汽车数量测试= [48 42 31 31 21 23 23 21 16 17 21]';%在每次重量中未能测试的汽车数量失败= [1 2 0 3 8 8 14 17 15 17 21]'每次重量都失败的汽车比例比例=失败./测试;情节(体重,比例,s)包含('重量');ylabel('部分');

该图是作为重量的函数失效的汽车比例的曲线图。假设失败计数来自二项式分布,这是合理的,其中概率参数p随着重量增加而增加。但是P如何取决于重量?
我们可以尝试将直线连接到这些数据。
LineAlcoef = Polyfit(重量,比例,1);Linearfit = Polyval(Linearcoef,重量);情节(体重,比例,s,重量,linearfit,'r-',[2000 4500],[0 0],'k:',[2000 4500],[1 1],'k:')包含('重量');ylabel('部分');

这种线性拟合有两个问题:
1)线预测比0且大于1的比例。
2)比例通常不分布,因为它们必须有界。这违反了拟合简单的线性回归模型所需的假设之一。
使用高阶多项式可能看起来有助于帮助。
[立方体,统计数据,CTR] = Polyfit(重量,比例,3);Cubicfit = Polyval(Cubiccoef,重量,[],CTR);情节(体重,比例,s,重量,cubicfit,'r-',[2000 4500],[0 0],'k:',[2000 4500],[1 1],'k:')包含('重量');ylabel('部分');

但是,这种契合仍然存在类似的问题。该图表明,随着重量超过4000,拟合比例开始减少;实际上它将变得否定重量值。当然,仍然违反了正常分布的假设。
相反,更好的方法是使用glmfit.适合Logistic回归模型。Logistic回归是广义线性模型的特殊情况,并且有两个原因比这些数据的线性回归更合适。首先,它使用适合于二项式分布的拟合方法。其次,物流链接将预测的比例限制在范围[0,1]。
对于Logistic回归,我们指定预测矩阵,以及包含一个列的矩阵,其中包含故障计数,以及包含所测试的数字的一列。我们还指定了二项式分布和Logit链接。
[LogItCoef,DEV] = GLMFIT(重量,[测试失败],“二”那'logit');LogitFit = GLMVAL(LogITCOEF,重量,'logit');情节(体重,比例,'BS',重量,logitfit,'r-');Xlabel('重量');ylabel('部分');

正如该曲线表明,拟合比例渐近为零,1重量变小或大。
模型诊断
这glmfit.功能提供了许多输出,用于检查拟合并测试模型。例如,我们可以比较两种模型的偏差值,以确定平方项是否会显着提高拟合。
[LogitCoEF2,DEV2] = GLMFIT([重量重量^ 2],[测试失败],“二”那'logit');pval = 1 - chi2cdf(dev-dev2,1)
pval = 0.4019
大的p值表示,对于这些数据,二次术语不会显着提高拟合。两个配合的图表表明了适合的差异很小。
Logitfit2 = Glmval(LogitCoef2,[重量重量^ 2],'logit');情节(体重,比例,'BS',重量,logitfit,'r-',重量,logitfit2,'G-');传奇('数据'那'线性术语'那'线性和二次术语'那“位置”那'西北');

为了检查合适的善良,我们还可以看看Pearson残差的概率图。这些是归一化的,使得当模型适合数据时,它们具有大致标准的正态分布。(没有这种标准化,残差会有不同的差异。)
[LogITCOEF,DEV,STATS] = GLMFIT(重量,[未能测试],“二”那'logit');normplot(stats.residp);

残余图显示了与正态分布的愉快协议。
评估模型预测
一旦我们对模型感到满意,我们就可以使用它来进行预测,包括计算置信范围。在这里,我们预测了100个测试中的预期车辆数量,这将在四个重量中的每一个都失败。
重量= 2500:500:4000;[失败,dlo,dhi] = glmval(logitcoef,treachred,'logit',统计数据,.95,100);错误栏(举重,失败,DLO,DHI,':');

二项式模型的链接功能
对于这五个分布中的每一个glmfit.万博1manbetx支持,有一个规范(默认)链接函数。对于二项式分布,规范链接是Logit。然而,还有其他三种相对于二项式模型的链接。所有四个都在间隔中保持平均反应[0,1]。
η= 5:.1:5;Plot (eta,1 ./ (1 + exp(-eta))' - ',eta,normcdf(eta),' - '那......ETA,1 - EXP(-Exp(ETA)),' - ',eta,exp(-exp(eta)),' - ');Xlabel('预测器的线性函数');ylabel('预测意味着反应');传奇('logit'那'概率'那'互补日志'那'log-log'那'地点'那'东');

例如,我们可以将符合概率链接与Logit链路进行比较。
probitcoef = glmfit(重量,[测试失败],“二”那'概率');probitFit = glmval (probitCoef、重量、'概率');情节(体重,比例,'BS',重量,logitfit,'r-',重量,probitfit,'G-');传奇('数据'那'Logit Model'那'概率模型'那“位置”那'西北');
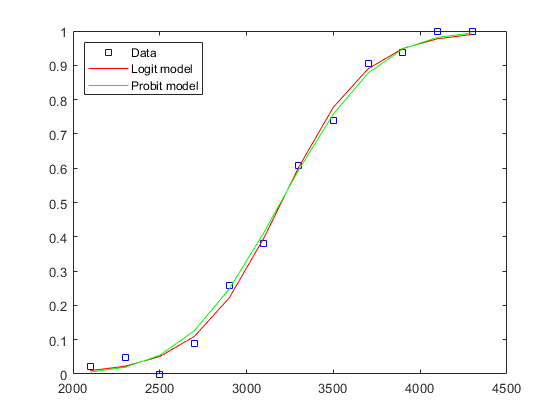
数据往往很难区分这四种链接功能,并且通常在理论场上进行选择。
您还可以从以下列表中选择一个网站:
