解释机器学习模型
本主题介绍用于模型解释的统计学和机器学习工具箱™功能,并展示如何解释机器学习模型(分类和回归)。
机器学习模型通常被称为“黑盒子”模型,因为很难理解该模型是如何进行预测的。可解释性工具可以帮助您克服机器学习算法的这方面问题,并揭示预测器如何有助于(或不有助于)预测。此外,您还可以验证模型的预测是否使用了正确的证据,并发现模型偏差不是立即明显的。
模型解释的功能
使用石灰那福芙,绘图竞争依赖性解释个人预测因子对训练分类或回归模型的预测的贡献。
石灰- 当地可解释的模型 - 不可知论解释(石灰)[1])通过拟合查询点的简单可解释模型来解释查询点的预测。简单模型充当训练模型的近似,并解释查询点周围的模型预测。简单模型可以是线性模型,也可以是决策树模型。您可以使用线性模型的估计系数或决策树模型的估计预测器重要性来解释单个预测器对查询点预测的贡献。有关详细信息,请参见石灰.福芙- 福利价值[2][3]查询点的预测器解释了由于预测器的原因,查询点的预测(对回归的响应或分类的类得分)与平均预测的偏差。对于一个查询点,所有特征的Shapley值的和对应于预测与平均值的总偏差。有关详细信息,请参见机器学习模型的福价.绘图竞争依赖性和partialDependence-部分依赖图(PDP)[4])示出了预测器(或一对预测器)与训练模型中的预测(或一对预测器)和预测(对分类的回归或类别的响应)之间的关系。对所选预测器的部分依赖性由通过通过边缘地消除其他变量的效果而获得的平均预测来定义。因此,部分依赖性是所选择的预测器的函数,其显示所选择的预测器对数据集的平均效果。您还可以创建一组个人有条件的期望(ICE[5])图,显示所选预测因子对单个观测结果的影响。有关详细信息,请参见更多关于在绘图竞争依赖性参考页面。
某些机器学习模型支持嵌入式功能选择,其中模型将预测值重要,万博1manbetx作为模型学习过程的一部分。您可以使用估计的预测原因来解释模型预测。例如:
训练一个合奏(
ClassificationBaggedensemble.或RegressionBaggedEnsemble)袋装决策树(例如,随机森林)并使用预测的重要性和OobpermutedPredictorimportance.功能。用套索正常化训练一个线性模型,从而缩小最不重要的预测器的系数。然后使用估计的系数作为预测值重要性的措施。例如,使用
fitclinear或Fitrinear.并指定这一点'正规化'名称-值参数为“套索”.
有关支持嵌入式功能选择的机器学习模型列表,请参阅万博1manbetx嵌入式功能选择.
使用统计和机器学习工具箱特征,适用于三级模型解释:本地,队列和全局。
| 水平 | 目标是 | 用例 | 统计和机器学习工具箱功能 |
|---|---|---|---|
| 本地解释 | 解释单个查询点的预测。 |
|
使用石灰和福芙对于指定的查询点。 |
| 队列的解释 | 解释培训的模型如何对整个数据集的子集进行预测。 | 验证一组特定样本的预测。 |
|
| 全球解释 | 解释训练有素的模型如何为整个数据集进行预测。 |
|
|
解释分类模型
这个例子使用随机森林算法训练了一个袋装决策树的集合,并使用可解释性特征解释了训练的模型。使用对象函数(OobpermutedPredictorimportance.和预测的重要性),以便在模型中找到重要的预测因子。此外,使用石灰和福芙解释指定查询点的预测。然后使用绘图竞争依赖性创建一个绘图,显示重要预测器和预测分类评分之间的关系。
火车分类集合模型
加载Creditrating_Historical.数据集。数据集包含客户ID及其财务比率,行业标签和信用评级。
台= readtable (“CreditRating_Historical.dat”);
显示表的前三行。
头(TBL,3)
ans =.3×8表ID WC_TA RE_TA EBIT_TA MVE_BVTD S_TA工业评分_____ _____ _____ _______ ________ _____ ________ ______ 62394 0.013 0.104 0.036 0.447 0.142 3 { 'BB'} 48608 0.232 0.335 0.062 1.969 0.281 8 { 'A'} 42444 0.311 0.367 0.074 1.935 0.366 1 {'A'}
通过删除包含客户ID和额定值的列来创建预测变量的表TBL..
tblx = removevars(tbl,[“id”那“评级”]);
通过使用培训袋装决策树的集合fitcensemble函数,并指定集合聚合方法为随机森林('袋').为保证随机森林算法的重现性,请指定“复制”名称-值参数为真正的树的学习者。另外,指定类名以设置训练模型中类的顺序。
RNG('默认')重复性的%t = templateTree (“复制”,真正的);黑箱= fitcensemble (tblX,资源描述。评级,...“方法”那'袋'那'学习者',t,...'pationoricalpricictors'那'行业'那...'classnames',{“AAA”“AA”“一个”'BBB'“BB”“B”'CCC'});
黑箱是A.ClassificationBaggedensemble.模型。
使用特定于模型的可解释性特性
ClassificationBaggedensemble.万博1manbetx支持两个对象功能,OobpermutedPredictorimportance.和预测的重要性,在训练的模型中找到重要的预测因子。
通过使用使用的估计袋外的预测值OobpermutedPredictorimportance.函数。该函数每次在一个预测器上随机地对包外数据进行置换,并估计由于这种置换而导致的包外误差的增加。增加的越多,功能就越重要。
Imp1 = oobPermutedPredictorImportance(黑箱);
估计通过使用的预测标志重要性预测的重要性函数。该功能通过在每个预测器上的拆分和分支节点的数量分割总和来估计预测测量器的重要性。
Imp2 = predictorImportance(黑箱);
创建一个包含预测器重要性估计的表,并使用该表创建水平条形图。要在任何预测器名称中显示现有的下划线,请更改ticklabelinterpreter.坐标轴的值'没有'.
table_Imp =表(Imp1’,Imp2’,...“VariableNames”,{'不禁止允许的预测标志重要性'那'预测重要性'},...“RowNames”,blackbox.predictornames);TileDlayout(1,2)AX1 = NEXTTILE;table_imp1 = sortrows(table_imp,'不禁止允许的预测标志重要性');barh(分类(table_imp1.row,table_imp1.row),table_imp1。('不禁止允许的预测标志重要性'))xlabel('不禁止允许的预测标志重要性') ylabel ('预测器') ax2 = nexttile;table_Imp2 = sortrows (table_Imp,'预测重要性');barh(分类(table_imp2.row,table_imp2.row),table_imp2。('预测重要性'))xlabel('预测重要性')ax1.ticklabelinterpreter =.'没有';ax2.ticklabelinterpreter =.'没有';
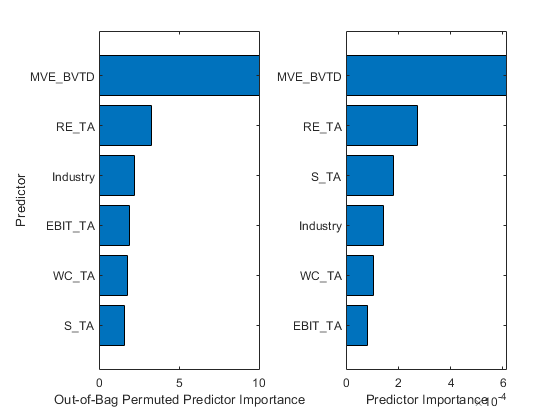
两个对象函数都确定mve_bvtd.和re_ta.作为两个最重要的预测因素。
指定查询点
找出那些评分是“AAA”并从中选择四个疑点。
tblX_AAA = tblX (strcmp(资源描述。评级,“AAA”):);queryPoint = datasample (tblX_AAA 4“替换”假)
queryPoint =4×6表WC_TA RE_TA EBIT_TA MVE_BVTD S_TA工业_____ _____ _______ ________ _____ ________ 0.331 0.531 0.077 7.116 0.522 12 0.26 0.515 0.065 3.394 0.515 0.121 1 0.413 0.057 3.647 0.466 0.617 12 0.766 0.126 4.442 0.483 9
使用Lime用线性简单型号
解释使用的查询点的预测石灰线性简单模型。石灰生成一个合成数据集,并将一个简单的模型拟合到该合成数据集。
创建A.石灰物体使用tblX_AAA这石灰仅使用其观察结果生成合成数据集评分是“AAA”,而不是整个数据集。
explainer_lime =石灰(黑箱,tblX_AAA);
默认值'datalocality'对于石灰是'全球',这意味着,默认情况下,石灰生成全局合成数据集并将其用于任何查询点。石灰使用不同的观察权重,使重量值更加专注于查询点附近的观察结果。因此,您可以将每个简单模型解释为特定查询点的训练模型的近似值。
使用对象函数适合四个查询点的简单模型适合.将第三个输入(在简单模型中使用的重要预测器的数量)指定为6,以使用所有6个预测器。
explainer_lime1 =适合(explainer_lime queryPoint (1:), 6);explainer_lime2 =适合(explainer_lime queryPoint (2:), 6);explainer_lime3 =适合(explainer_lime queryPoint (3:), 6);explainer_lime4 =适合(explainer_lime queryPoint (4:), 6);
利用目标函数绘制简单模型的系数情节.
Tiledlayout (2,2) ax1 = nexttile;绘图(expresser_lime1);AX2 = NELTTILE;绘图(Exploxer_lime2);Ax3 = NextTile;绘图(expresser_lime3);AX4 = NELTTILE;绘图(expresser_lime4);ax1.ticklabelinterpreter ='没有';ax2.ticklabelinterpreter =.'没有';ax3。TickLabelInterpreter ='没有';大举裁员。TickLabelInterpreter ='没有';
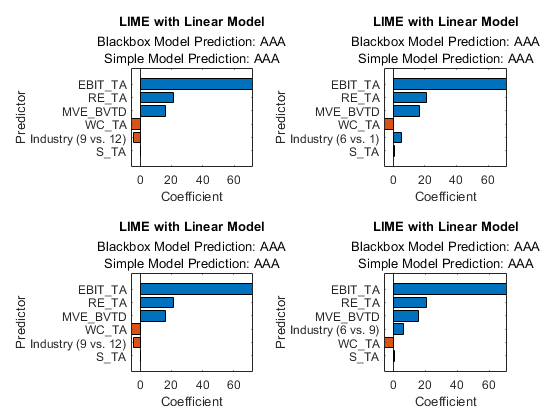
所有的简单模型都确定EBIT_TA那re_ta.,mve_bvtd.作为三个最重要的预测因子。预测器的正系数表明,增加预测值值导致简单模型中预测得分的增加。
对于一个绝对预测器来说情节函数只显示分类预测器中最重要的虚拟变量。因此,每个柱状图都显示了一个不同的哑变量。
计算福利价值
对于查询点的预测器的福音值解释了从平均分数的预测得分的偏差,由于预测器。创建A.福芙物体使用tblX_AAA这福芙根据样本计算预期的贡献“AAA”.
解释器_Shapley=福芙尼(Blackbox,TBLX_AAA);
使用对象函数计算查询点的福利值适合.
explainer_shapley1 =适合(explainer_shapley queryPoint (1:));explainer_shapley2 =适合(explainer_shapley queryPoint (2:));explainer_shapley3 =适合(explainer_shapley queryPoint (3:));explainer_shapley4 =适合(explainer_shapley queryPoint (4:));
使用对象函数绘制Shapley值情节.
Tiledlayout (2,2) ax1 = nexttile;Plot (explainer_shapley1) ax2 = nexttile;Plot (explainer_shapley2) ax3 = nexttile;Plot (explainer_shapley3) ax4 = nexttile;情节(explainer_shapley4) ax₁。TickLabelInterpreter ='没有';ax2.ticklabelinterpreter =.'没有';ax3。TickLabelInterpreter ='没有';大举裁员。TickLabelInterpreter ='没有';
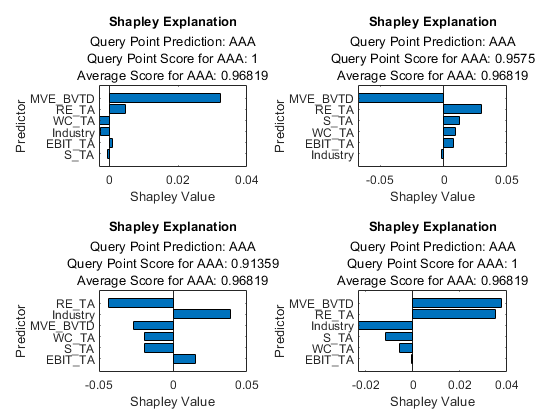
mve_bvtd.和re_ta.所有四个查询点的三个最重要的预测因素中有两个。
福的价值观mve_bvtd.第一个和第四个查询点为正,第二个和第三个查询点为负。的mve_bvtd.对于第一个和第四查询点,值为7和4,以及第二和第三查询点的值约为3.5。根据四个查询点的福利值,一个大mve_bvtd.值会导致预测分数的增加,且较小mve_bvtd.与平均值相比,值导致预测得分的减少。结果与结果一致石灰.
创建部分依赖图(PDP)
PDP图显示了在训练模型中预测器和预测分数之间的平均关系。创建pdpre_ta.和mve_bvtd.,其他可解释工具标识为重要的预测因子。通过tblx_aaa.来绘图竞争依赖性所以这个函数计算预测分数的期望只使用样本“AAA”.
图绘图(Blackbox,'re_ta'那“AAA”tblX_AAA)
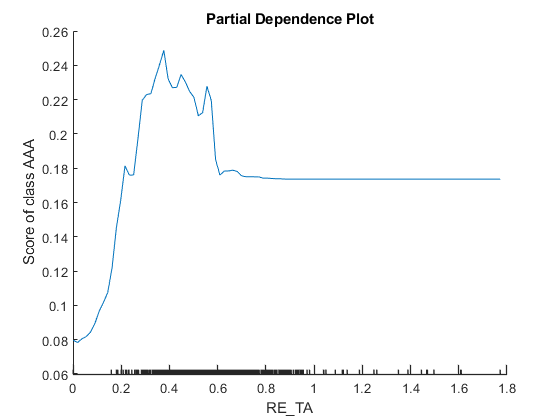
plotPartialDependence(BlackBox,“MVE_BVTD”那“AAA”tblX_AAA)
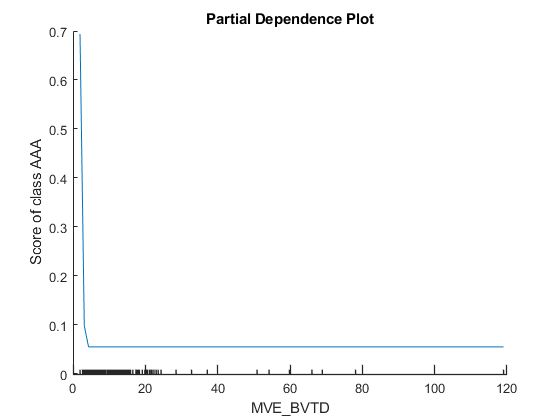
小蜱虫X.-axis表示预测器的唯一值tbl_AAA.情节为mve_bvtd.表明预测得分很大mve_bvtd.价值很小。得分值会减少mve_bvtd.值增加,直到它达到5个,然后得分值保持不变mve_bvtd.价值增加。的依赖mve_bvtd.的子集tbl_AAA鉴定绘图竞争依赖性与当地的贡献不一致mve_bvtd.在识别的四个查询点石灰和福芙.
解释回归模型
回归问题的模型解释工作流类似于分类问题的工作流程,如示例中所示解释分类模型.
这个例子训练了一个高斯过程回归(GPR)模型,并使用可解释性特征解释训练的模型。利用探地雷达模型的一个核参数来估计预报权值。此外,使用石灰和福芙解释指定查询点的预测。然后使用绘图竞争依赖性创建一个图表,显示一个重要的预测器和预测的反应之间的关系。
探地雷达火车模型
加载CARBIG.数据集,其中包含在20世纪70年代和20世纪80年代初进行的汽车测量。
加载CARBIG.
创建包含预测器变量的表加速度那气瓶等等
TBL =桌子(加速,气瓶,位移,马力,型号,重量);
训练响应变量的GPR模型MPG.通过使用fitrgp.函数。指定“KernelFunction”as.'ardsquaredexponential'使用平方指数内核,每个预测器具有单独的长度尺度。
Blackbox = FitRGP(TBL,MPG,“ResponseName”那'mpg'那'pationoricalpricictors',[2 5],...“KernelFunction”那'ardsquaredexponential');
黑箱是A.regressiongp.模型。
使用特定于模型的可解释性特性
您可以从模型中使用的核函数的长度尺度中计算预测器权重(预测器重要性)。长度尺度定义了预测器之间的距离,可以使响应值变得不相关。通过取负学习长度尺度的指数来找到归一化的预测权重。
sigmaL = blackbox.KernelInformation.KernelParameters (1: end-1);%学习的长度尺度重量= exp (-sigmaL);%预测值重量重量=重量/笔(重量);归一化预测权重
创建一个包含标准化预测器权重的表,并使用该表创建水平条形图。要在任何预测器名称中显示现有的下划线,请更改ticklabelinterpreter.坐标轴的值'没有'.
tbl_weight =表(权重,“VariableNames”,{'预测重量'},...“RowNames”, blackbox.ExpandedPredictorNames);tbl_weight = sortrows (tbl_weight,'预测重量');b = barh(分类(tbl_weight.row,tbl_weight.row),tbl_weight。('预测重量'));B.Parent.TicklabelInterpreter =.'没有';Xlabel('预测重量') ylabel ('预测器')
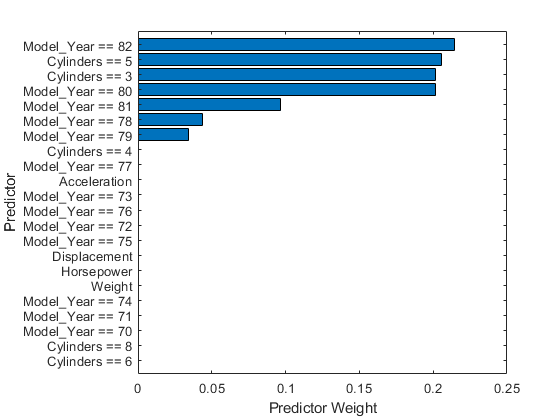
预测器权值表明分类预测器存在多个虚拟变量model_year.和气瓶是很重要的。
指定查询点
找出那些MPG.值小于的0.25分位数MPG..从子集中,选择不包含缺失值的四个查询点。
RNG('默认')重复性的%idx_子集= find(MPG <分位数(MPG,0.25));tbl_subset =(资源(idx_subset:);queryPoint = datasample (rmmissing (tbl_subset), 4,“替换”假)
queryPoint =4×6表加速气瓶位移马力型号_ _______________________________________________________________________________________________________3130 215 70 4613 13.7 8 318 145 77 4140
用树木用树木简单模型
解释使用的查询点的预测石灰与决策树简单模型。石灰生成一个合成数据集,并将一个简单的模型拟合到该合成数据集。
创建A.石灰物体使用tbl_subset.这石灰使用子集而不是整个数据集生成合成数据集。指定'simplemodeltype'as.“树”使用决策树简单模型。
exploxer_lime =石灰(blackbox,tbl_subset,'simplemodeltype'那“树”);
默认值'datalocality'对于石灰是'全球',这意味着,默认情况下,石灰生成全局合成数据集并将其用于任何查询点。石灰使用不同的观察权重,使重量值更加专注于查询点附近的观察结果。因此,您可以将每个简单模型解释为特定查询点的训练模型的近似值。
使用对象函数适合四个查询点的简单模型适合.指定第三个输入(在简单模型中使用的重要预测器的数量)为6.使用此设置,该软件指定最大判定拆分数(或分支节点)为6,以便最多使用拟合的决策树预测器。
explainer_lime1 =适合(explainer_lime queryPoint (1:), 6);explainer_lime2 =适合(explainer_lime queryPoint (2:), 6);explainer_lime3 =适合(explainer_lime queryPoint (3:), 6);explainer_lime4 =适合(explainer_lime queryPoint (4:), 6);
通过使用对象函数绘制预测值重要性情节.
Tiledlayout (2,2) ax1 = nexttile;绘图(expresser_lime1);AX2 = NELTTILE;绘图(Exploxer_lime2);Ax3 = NextTile;绘图(expresser_lime3);AX4 = NELTTILE;绘图(expresser_lime4);ax1.ticklabelinterpreter ='没有';ax2.ticklabelinterpreter =.'没有';ax3。TickLabelInterpreter ='没有';大举裁员。TickLabelInterpreter ='没有';
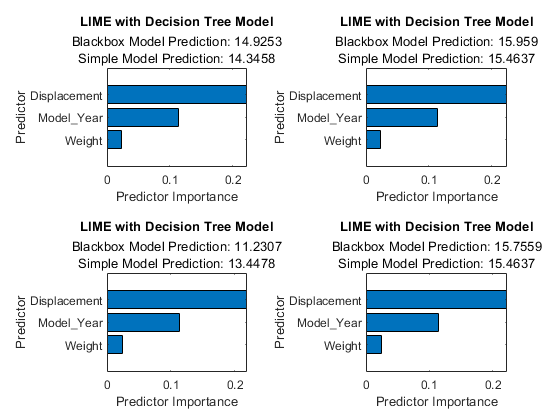
所有的简单模型都确定置换那model_year.,重量作为重要的预测因子。
计算福利价值
查询点的预测器的Shapley值解释了由于预测器导致的查询点的预测响应与平均响应之间的偏差。创建A.福芙模型的对象黑箱使用tbl_subset.这福芙计算的预期贡献基于观测tbl_subset..
explainer_shapley =沙普利(黑箱,tbl_subset);
使用对象函数计算查询点的福利值适合.
explainer_shapley1 =适合(explainer_shapley queryPoint (1:));explainer_shapley2 =适合(explainer_shapley queryPoint (2:));explainer_shapley3 =适合(explainer_shapley queryPoint (3:));explainer_shapley4 =适合(explainer_shapley queryPoint (4:));
使用对象函数绘制Shapley值情节.
Tiledlayout (2,2) ax1 = nexttile;Plot (explainer_shapley1) ax2 = nexttile;Plot (explainer_shapley2) ax3 = nexttile;Plot (explainer_shapley3) ax4 = nexttile;情节(explainer_shapley4) ax₁。TickLabelInterpreter ='没有';ax2.ticklabelinterpreter =.'没有';ax3。TickLabelInterpreter ='没有';大举裁员。TickLabelInterpreter ='没有';
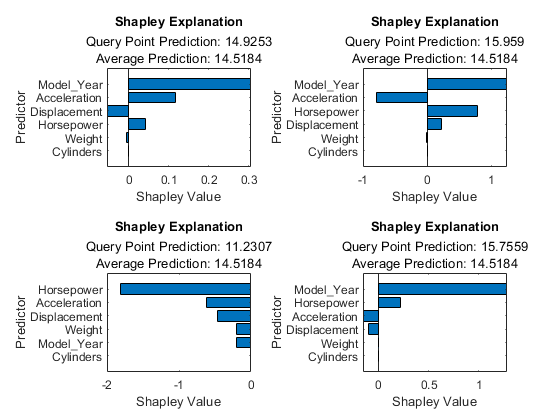
model_year.是第一个、第二个和第四个查询点最重要的预测器,而model_year.对于三个查询点是肯定的。的model_year.对于这三个点来说,值为76或77,第三个查询点的值为70.根据四个查询点的福音值,一个小model_year.价值导致预测响应的减少,并且是一个大的model_year.值导致预测响应比平均值增加。
创建部分依赖图(PDP)
PDP图显示了预测器与训练模型中的预测响应之间的平均关系。创建一个PDPmodel_year.,其他可解释性工具认为这是一个重要的预测因素。通过tbl_subset.来绘图竞争依赖性所以这个函数只用样本来计算预测响应的期望tbl_subset..
图绘图(Blackbox,'model_year',tbl_subset)
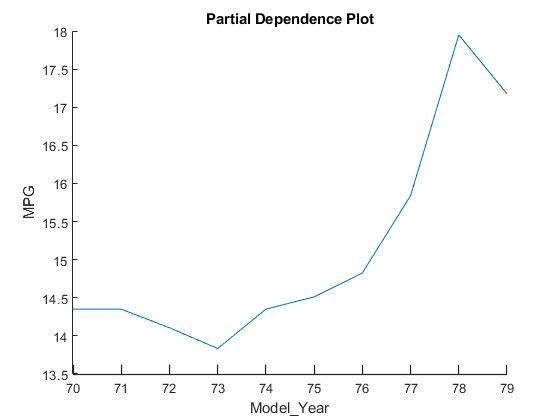
该曲线显示了四个查询点的Shapley值标识的相同趋势。预测的反应(MPG.)的价值增加model_year.价值增加。
参考资料
另请参阅
相关的话题
- 机器学习模型的福价
- 功能选择简介
- 用石灰解释对表格数据的深网络预测(深度学习工具箱)
你也可以从以下列表中选择一个网站:
