部分最小二乘回归和主成分回归
该示例示出了如何应用偏最小二乘回归(PLSR)和主成分回归(PCR),并讨论了这两种方法的有效性。PLSR和PCR在有大量预测变量时模拟响应变量的方法,并且这些预测器是高度相关的甚至共线。这两种方法都构造了新的预测变量,称为组件,作为原始预测器变量的线性组合,但它们以不同方式构造这些组件。PCR创建组件以解释预测变量中的观察到可变性,而不考虑响应变量。另一方面,PLSR确实考虑了响应变量,因此通常会导致能够使用更少组件符合响应变量的模型。在其实际使用方面,最终是否转化为更加令人垂涎的模型,取决于上下文。
加载数据
负载数据集,其包括在401个波长的60个汽油样品的光谱强度,以及它们的辛烷值等级。这些数据在Kalivas,约翰H.,描述“近红外光谱的两个数据集,”化学计量学与智能实验室系统,V.37(1997年),pp.255-259。
加载光谱谁德文辛烷
名称大小字节类属性NIR 60x401 192480双辛烷值60x1 480双倍
[假,h] =排序(辛烷值);OldOrder = Get(GCF,'defaultaxescolororord');设置(GCF,'defaultaxescolororord',喷射(60));Plot3(Repmat(1:401,60,1)',Repmat(辛烷(H),1,401)',NIR(H,:)');设置(GCF,'defaultaxescolororord',老大号标);Xlabel('波长索引');ylabel('辛烷');轴(“紧”);网格上
用两个组件拟合数据
用来plsregress.用十个PLS组件和一个响应拟合PLSR模型的功能。
x = nir;y =辛烷;[n,p] = size(x);[Xloadings,Yloadings,Xscores,Yscores,BetaPLS10,PLSPCTVAR] = PLSREOGRENT(......x,y,10);
10个组件可能比需要充分适应数据,但是可以使用来自这种拟合的诊断来选择具有更少组件的更简单模型。例如,选择组件数量的一种快速方法是绘制响应变量中所解释的方差百分比作为组件数量的函数。
情节(1:10,Cumsum(100 * plspctvar(2,:)),'-bo');Xlabel('PLS组件数量');ylabel(在y'中解释的'百分比方差);

在实践中,在选择组件数量时可能需要更多的护理。例如,交叉验证是一个广泛使用的方法,该方法将在此示例稍后举例说明。目前,上面的剧情表明,具有两个组件的PLSR解释了观察到的大部分方差y。计算双组分模型的拟合响应值。
[Xloadings,Yloadings,Xscores,Yscores,Betapls] = PlsreOgress(x,y,2);Yfitpls = [of(n,1)x] * betapls;
接下来,用两个主成分拟合PCR模型。第一步是执行主成分分析X.,使用PCA.功能,并保留两个主组件。然后,PCR只是在这两个组件上的响应变量的线性回归。当变量具有非常不同的可变性时,首先通过其标准偏差将每个变量进行正常化,通常是有意义的。然而,在这里没有完成。
[PCALoadings,PCASCORORS,PCAVAR] = PCA(X,“经济”,假);betapcr =回归(Y-yan(y),pcascores(:,1:2));
为了使PCR结果更容易根据原始频谱数据来解释,转换为原始的未输入变量的回归系数。
betapcr = pcaloadings(:,1:2)* betapcr;betapcr = [均值(y) - 平均值(x)* betapcr;betapcr];YFITPCR = [oon(n,1)x] * betapcr;
绘图适用于PLSR和PCR的响应。
情节(Y,Yfitpls,'博',Y,Yfitpcr,'r ^');Xlabel(“观察到的回应”);ylabel('合适的反应');传说({'PLSR有2个组件''PCR带有2个组件'},......'位置'那'nw');
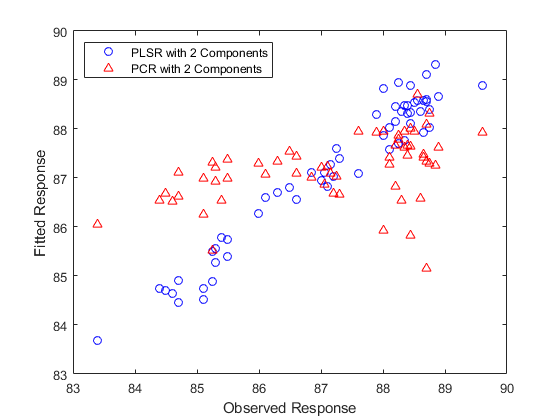
从某种意义上说,上图中的比较不是公平的一个 - 通过观察两个组件PLSR模型预测响应的程度,选择组件数量(两种),并且没有理由PCR模型应该仅限于相同数量的组件。然而,凭借相同数量的组件,PLSR在拟合方面做得更好y。事实上,看着上面的图中拟合值的水平散射,具有两个组分的PCR几乎没有使用恒定模型。来自两个回归的R角值确认。
TSS = SUM((Y-均值(y))。^ 2);rss_pls = sum((y-yfitpls)。^ 2);rsquaredpls = 1 - rss_pls / tss
rsquaredpls = 0.9466
rss_pcr = sum((y-yfitpcr)。^ 2);rsquaredpcr = 1 - rss_pcr / tss
rsquaredpcr = 0.1962
比较两个模型的预测力的另一种方法是在两种情况下绘制响应变量对两个预测器的响应变量。
Plot3(Xscores(:,1),Xscores(:,2),Y-均值(Y),'博');传说('PLSR');网格上;查看(-30,30);

在没有能力旋转图形的情况下,它有点难,但上面的PLSR曲线曲线显示了围绕平面散射的点。另一方面,下面的PCR曲线表显示了一云点,几乎没有线性关系的指示。
Plot3(Pcascores(:,1),Pcascores(:,2),Y-yan(Y),'r ^');传说('PCR');网格上;查看(-30,30);

请注意,虽然两个PLS组件更好地观察到的预测器y,下图表明他们在观察到的情况下解释了一些较小的方差X.比PCR中使用的前两个主要成分。
情节(1:10,100 * cumsum(plspctvar(1,:)),'b-o',1:10,......100 * cumsum(Pcavar(1:10))/总和(PCAVAR(1:10)),'r- ^');Xlabel('主成分数量');ylabel('x'中解释的百分比方差);传说({'PLSR''PCR'},'位置'那'se');

PCR曲线均匀地提高的事实表明,为什么PCR与两个部件的PCR相对于PLSR在配件方面具有这种糟糕的工作y。PCR构建成分以最佳解释X.因此,这些前两个组件忽略了在适合观察到的数据中的数据中的信息y。
适合更多组件
随着更多组件在PCR中添加,它必须更好地拟合原始数据y,仅仅因为在某些时候大多数重要的预测信息X.将存在于主要成分中。例如,下图表明,当使用10个组件时,这两种方法的残差差异远得多,而不是两个组件。
Yfitpls10 = [of(n,1)x] * betapls10;betapcr10 =回归(Y-yan(y),pcascores(:,1:10));betapcr10 = pcaloadings(:,1:10)* betapcr10;betapcr10 = [均值(y) - 平均值(x)* betapcr10;betapcr10];YFITPCR10 = [of(n,1)x] * betapcr10;绘图(Y,Yfitpls10,'博',y,yfitpcr10,'r ^');Xlabel(“观察到的回应”);ylabel('合适的反应');传说({'PLSR有10个组件''PCR带有10个组件'},......'位置'那'nw');
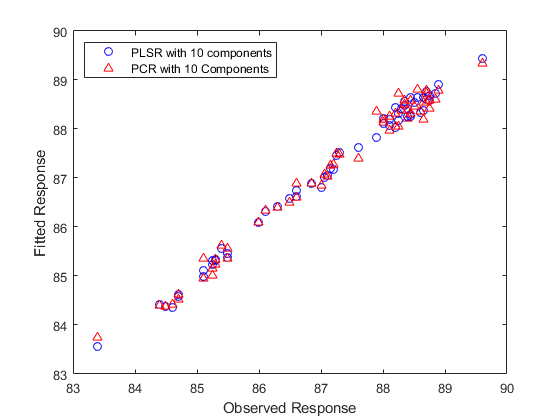
两种型号都适合y相当准确,虽然PLSR仍然稍微准确。但是,10个组件仍然是任何一个模型的任意选择的编号。
选择具有交叉验证的组件数量
选择组件数量以在预测预测器变量的未来观察的响应时最小化预期误差通常有用。只需使用大量组件将在拟合当前观察到的数据时进行良好的工作,而是导致过度装备的策略。拟合当前数据的良好导致模型不呈现给其他数据,并给出了对预期误差的过度乐观估计。
交叉验证是一种更统计学上的声音方法,用于选择PLSR或PCR中的组件数量。它避免了通过不重新装入相同的数据来符合模型和估计预测误差来避免过度拟合数据。因此,预测误差的估计不是乐观偏置向下。
plsregress.在这种情况下,可以选择通过交叉验证来估计平均平方预测误差(MSEP),在这种情况下使用10倍C-V.
[xl,yl,xs,ys,beta,pctvar,plsmsep] = plsregress(x,y,10,'cv',10);
对于PCR,横梁结合简单的功能来计算PCR的平方误差之和,可以使用10倍交叉验证来估计MSEP。
pcrmsep = sum(crossval(@ pcrsse,x,y,'kfold',10),1)/ n;
PLSR的MSEP曲线表示,两个或三个组件尽可能良好地确实良好。另一方面,PCR需要四个组件以获得相同的预测精度。
情节(0:10,PLSMSEP(2,:),'b-o',0:10,pcrmsep,'r- ^');Xlabel('组件数量');ylabel('估计平均平方预测误差');传说({'PLSR''PCR'},'位置'那'ne');
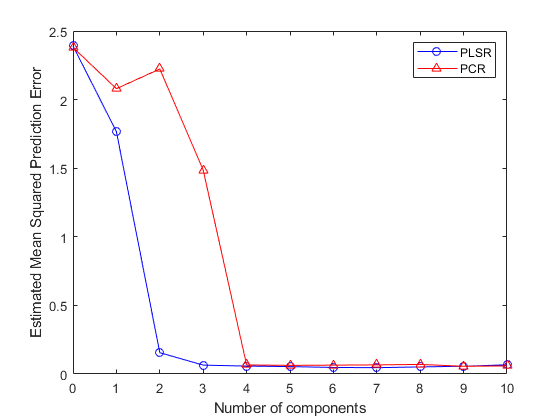
实际上,PCR中的第二个组分增加模型的预测误差,暗示该组件中包含的预测变量的组合与之强烈相关y。同样,这是因为PCR构造成分来解释变化X.,而不是y。
模型分析
因此,如果PCR需要四个组件与三个组件一起获得与PLSR相同的预测精度,则PLSR模型更加解析吗?这取决于您考虑的模型的哪个方面。
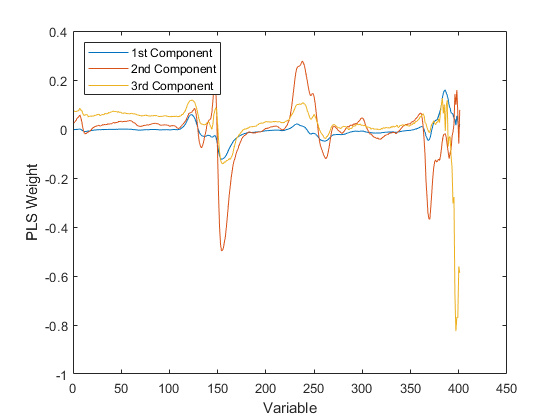
所述PLS权重是定义PLS部件,原始变量的线性组合,即,它们描述在PLSR每个组件如何强烈地依赖于原始变量,和在什么方向。
[xl,yl,xs,ys,beta,pctvar,mse,stats] = plsregress(x,y,3);情节(1:401,统计信息,' - ');Xlabel('变量');ylabel('pls prefe');传说({'1st组件''第二个组件''第3个组件'},......'位置'那'nw');
类似地,PCA加载描述了PCR中的每个组件的强度取决于原始变量。
绘图(1:401,PCaloadings(:,1:4),' - ');Xlabel('变量');ylabel('pca loading');传说({'1st组件''第二个组件''第3个组件'......'第四组分'},'位置'那'nw');
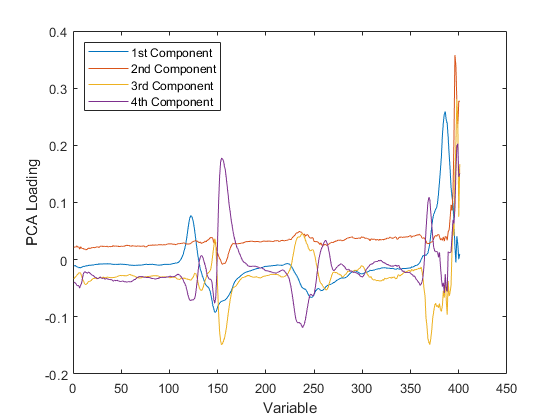
对于PLSR或PCR,可能是通过检查其重量最大的变量来赋予每个组分来赋予物理上有意义的解释。例如,通过这些光谱数据,可以在汽油中存在的化合物来解释强度峰,然后观察特定组分的重量拾取少量这些化合物。从该角度来看,较少的组件更简单地解释,因为PLSR通常需要更少的组件来充分预测响应,因此它导致更加令人垂涎的模型。
另一方面,PLSR和PCR都导致每个原始预测器变量的回归系数,以及截距。从这个意义上讲,既不是更加解析的,因为无论使用多少个组件,两种模型都依赖于所有预测因子。更具体地说,对于这些数据,两个模型都需要401个光谱强度值,以便进行预测。
然而,最终目标可以将原始变量集减小到较小的子集仍然能够准确地预测响应。例如,可以使用PLS权重或PCA加载来仅选择对每个组件贡献的那些变量。如前所示,从PCR模型拟合一些组件可主要用来描述在预测变量的变化,并且可包括大的权重为未牢固与响应相关联的变量。因此,PCR可以导致保持不需要预测的变量。
对于本示例中使用的数据,PLSR和PCR用于精确预测的PLS的数量的差异不是很大,并且PLS权重和PCA负载似乎拾取相同的变量。对于其他数据来说可能不是真的。
您还可以从以下列表中选择一个网站:
