替代分裂
当缺少观察的最佳分割预测器的值时,如果指定使用代理拆分,则软件将使用最佳代理预测器向左或右子节点发送观察。当您缺少数据,树木和具有代理分裂的树木的集合会提供更好的预测。此示例显示如何通过使用具有代理分割的决策树来提高具有缺失值的数据的预测的准确性。
加载样本数据
加载电离层数据集。
加载电离层
将数据分区设置为培训和测试集。持有30%的测试数据。
RNG('默认')重复性的%cv = cvpartition(y,'坚持',0.3);
确定培训和测试数据。
Xtrain = x(训练(CV),:);YTrain = Y(训练(简历));xtest = x(测试(cv),:);YTEST = Y(测试(CV));
假设缺少测试集中的一半值。在测试设置中设置一半值南。
XTEST(RAND(尺寸(XTEST))> 0.5)= NAN;
训练随机森林
在没有替代分裂的情况下训练150棵分类树的随机森林。
templ = templatetree('可重复',真的);随机预测器选择的再现性的%mdl = fitcensemble(xtrain,ytrain,'方法'那'包'那'numlearnicalnycle',150,'学习者',templ);
创建使用代理分割的决策树模板。使用代理分裂的树不会丢弃在某些预测器中缺少数据时的整个观察。
templs = templatetree('代理'那'在'那'可重复',真的);
使用模板训练一个随机的森林Templs.。
mdls = fitcensemble(xtrain,ytrain,'方法'那'包'那'numlearnicalnycle',150,'学习者',模板);
测试精度
测试预测的准确性和没有代理分裂。
使用这两种方法预测响应并创建混淆矩阵图。
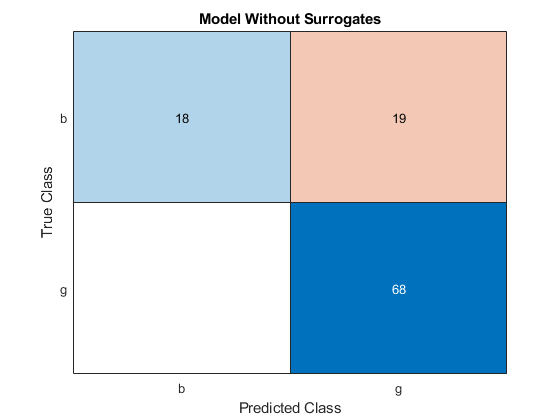
ytest_pred =预测(mdl,xtest);图cm = confusionchart(ytest,ytest_pred);cm.title ='没有代理的模型';
YTEST_PREDS =预测(MDL,XTEST);图CMS = ConfusionChart(YTEST,YTEST_PREDS);cms.title =.'与代理人的模型';
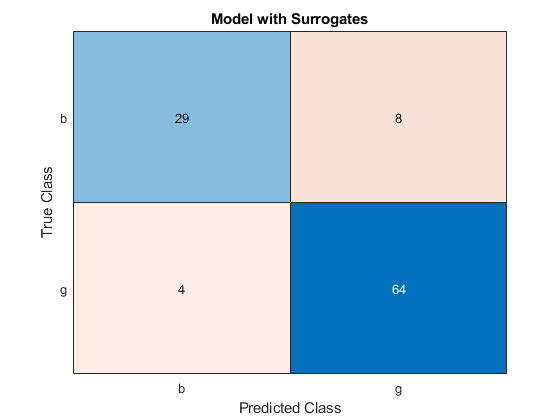
混淆矩阵上的所有偏差元素都表示错误分类的数据。一个良好的分级器产生了一种看起来显着对角线的混淆矩阵。在这种情况下,对于用代理分裂训练的模型,分类误差较低。
估计累积分类错误。指定'模式','累积'估计通过使用的分类错误损失功能。这损失函数返回一个元素的向量j表示使用第一个错误j学习者。
图绘图(丢失(MDL,XTEST,YTEST,'模式'那'累积')) 抓住在绘图(损失(MDLS,XTEST,YTEST,'模式'那'累积'),'r--') 传奇('没有代理分裂的树木'那'用替代分裂的树木')Xlabel('树的数量')ylabel('测试分类错误')

由于树的数量增加,误差值会降低,这表明性能良好。对于使用代理分裂训练的模型,分类错误较低。
通过使用检查结果差异的统计显着性CompareHoldout.。此功能使用McNemar测试。
[〜,p] = pockareholdoutout(mdls,mdl,xtest,xtest,ytest,'选择'那'更大')
P = 0.0384.
低P.-Value表示与替代分裂的集合以统计上显着的方式更好。
估计预测因素重要性
预测值重要性估计可以根据树木是否使用替代分裂而变化。通过禁用外袋观察来估算预测的重要措施。然后,找到五个最重要的预测因子。
Imp = OobperMutedPredictorimportance(MDL);[〜,IND] = MAXK(IMP,5)
IND =1×55 3 27 8 14
Imps = OobperMutedPredictorimportance(MDL);[〜,Inds] = maxk(Imps,5)
inds =1×53 5 8 27 7
在估算预测因素重要性之后,您可以再次排除不重要的预测器并再次培训模型。消除不重要的预测器可节省预测的时间和内存,并使预测更容易理解。
如果培训数据包括许多预测因子并且您想要分析预测的重要性,则指定'numvariablestosample'的Templatetree.功能'全部'对于合奏的树学习者。否则,软件可能无法选择一些预测器,低估了他们的重要性。例如,看到选择随机林的预测器。
也可以看看
CompareHoldout.|fitcensemble.|fitrensemble.
相关话题
您还可以从以下列表中选择一个网站:
