基于超参数优化的分类器分类器
这个例子展示了如何在分类学习器应用程序中使用超参数优化来调整分类支持向量机(SVM)模型的超参数。比较训练后的可优化的SVM与性能最好万博1manbetx的预置SVM模型的测试集性能。
在matlab.®命令窗口,加载
电离层数据集,并创建包含该数据的表。将表分为训练集和测试集。负载电离层tbl = array2table(x);tbl.y = y;RNG('默认')数据拆分的再现性的%分区= cvpartition (Y,“坚持”,0.15);Idxtrain =培训(分区);%训练集指标tblTrain =(资源(idxTrain:);tblTest =(资源(~ idxTrain:);
开放分类学习者。单击应用程序选项卡,然后单击右侧的箭头应用程序要打开应用程序库的部分。在机器学习和深度学习组中,单击分类学习者.
在分类学习者标签,在文件部分中,选择新会话>从工作区.
在“从工作区”对话框的“新会话”中,选择
tbltrain表的数据集变量列表。如对话框中所示,该应用程序选择响应和预测器变量。默认响应变量是
Y.默认的验证选项是5倍交叉验证,以防止过拟合。对于本例,不要更改默认设置。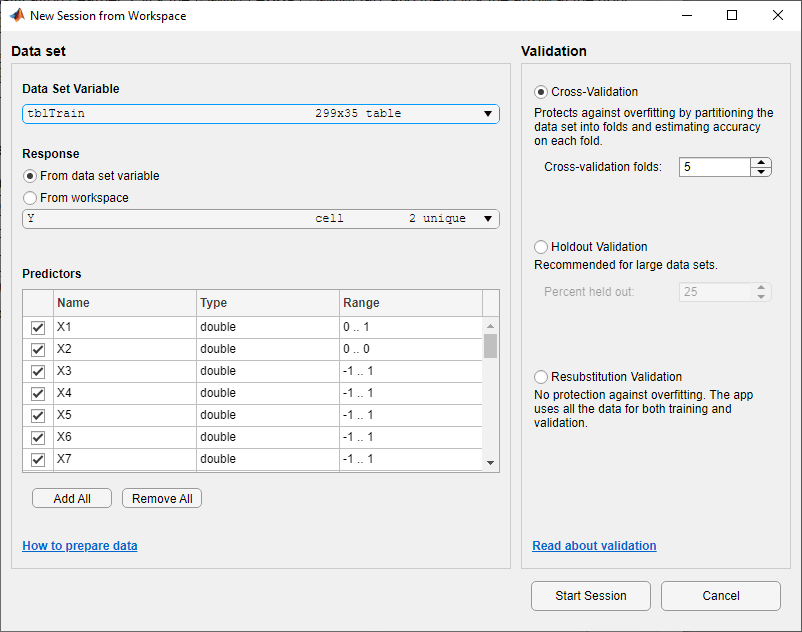
要接受默认选项并继续,请单击开始课程.
列车所有预设的SVM型号。在分类学习者标签,在模型类型段,单击箭头以打开图库。在万博1manbetx支持向量机组中,单击所有SVMS.在培训部分中,点击火车.该应用程序训练每种支持向量机模型类型中的一个,并在楷模窗格。
提示
如果您有并行计算工具箱™,您可以培训所有SVM型号(所有SVMS)同时选择使用并行按钮培训节之前点击火车.点击后火车,打开并行池对话框打开并保持打开状态,同时应用程序打开并行工作人员池。在此期间,您不能与该软件进行交互。池打开后,应用程序同时训练SVM模型。
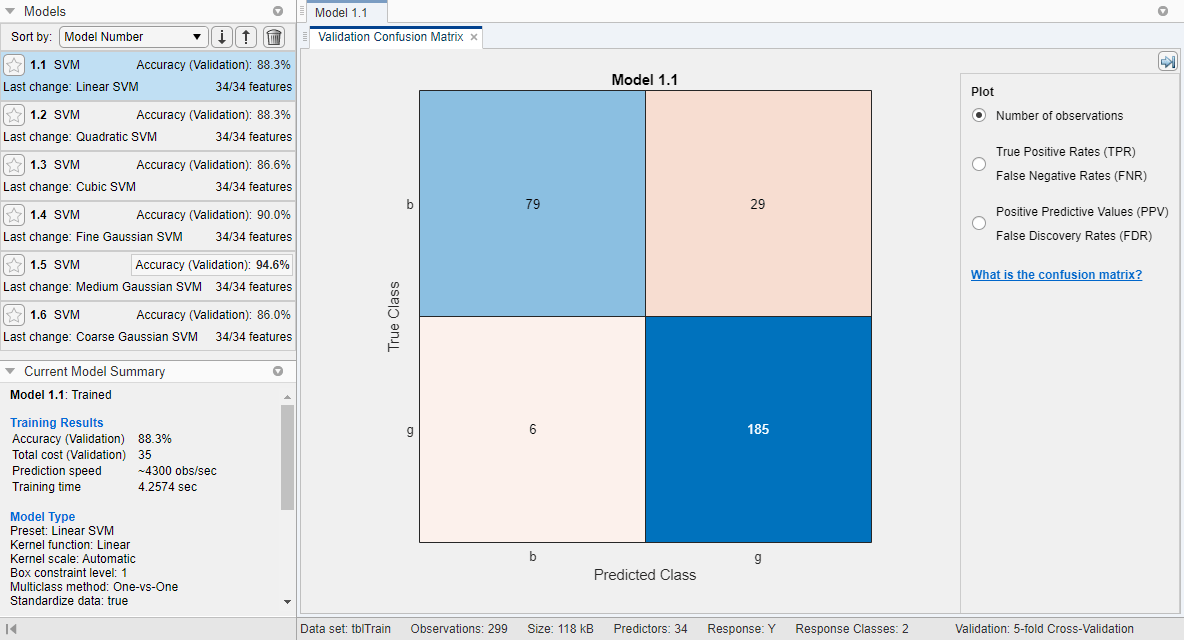
该应用程序显示一个散点图
电离层数据。正确分类点标有一个o,并且用x标记错误的分类点。楷模左边的窗格显示了每个模型的验证精度。请注意
验证在结果中引入了一些随机性。您的模型验证结果可能与本例中显示的结果不同。
选择一个可优化的SVM模型进行训练。在分类学习者标签,在模型类型段,单击箭头以打开图库。在万博1manbetx支持向量机组中,单击优化的SVM.该应用程序禁用使用并行选择可优化的型号时按钮。
选择要优化的模型超参数。在模型类型部分中,选择高级>高级.应用程序会打开一个对话框,你可以在其中进行选择优化选中要优化的超参数。默认情况下,所有可用超参数的复选框都被选中。对于本例,清除优化复选框核函数和标准化数据.默认情况下,应用程序禁用优化复选框内核规模当核函数有一个固定的值而不是
高斯.选择一个高斯核函数,并选择优化复选框内核规模.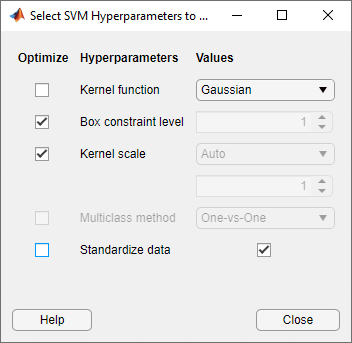
在培训部分中,点击火车.
该应用程序显示最小分类错误情节它运行优化过程。在每次迭代时,该应用程序尝试不同的HyperParameter值组合,并使用最小验证分类错误更新绘图,该识别误差在深蓝色中表示。当应用程序完成优化过程时,它选择由红场指示的优化的超参数集。有关更多信息,请参阅最小分类错误情节.
应用程序列出了优化的超参数优化结果情节右侧的部分和优化的超参数部分的当前模型的总结窗格。
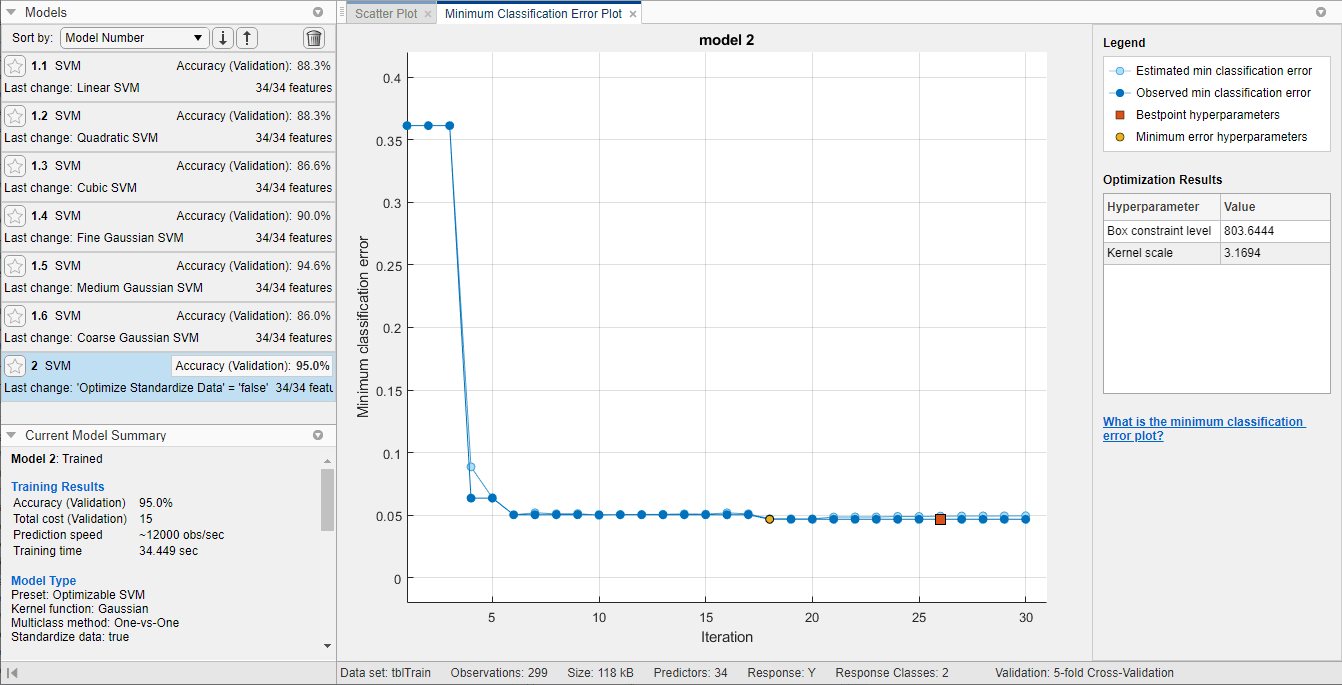
请注意
一般情况下,优化结果是不可重复的。
比较训练后的预设支持向量机模型和训练后的可优化模型。在楷模窗格,应用程序突出显示最高准确性(验证)通过在一个盒子里勾勒出来。在此示例中,训练有素的优化SVM模型优于六个预设模型。
训练有素的可优化型号并不总是比训练有素的预设型号更高的精度。如果训练有素的可优化型号不执行良好,则可以尝试通过运行更长时间的优化来获得更好的结果。在模型类型部分中,选择高级>优化器选项.在对话框中,增加迭代价值。例如,双击默认值
30.并输入一个值60.由于HyperParameter调整通常会导致过度框架的模型,因此检查测试集上可优化的SVM模型的性能,并将其与最佳预设SVM模型的性能进行比较。首先将测试数据导入应用程序。
在分类学习者标签,在测试部分中,选择从工作区中测试数据>.
在“导入测试数据”对话框中,选择
tblTest表的测试数据集变量列表。如对话框中所示,应用程序标识响应和预测器变量。
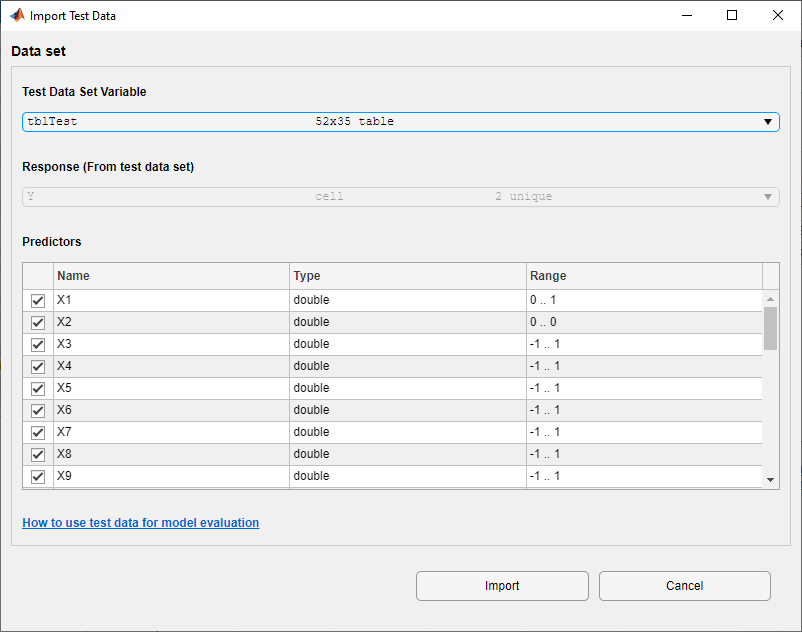
点击进口.
计算最佳预设模型的准确性和最优化的模型
tblTest数据。首先,在楷模窗格中,单击旁边的星形图标介质高斯支持向量机模型和优化的SVM模型。
对于每个模型,选择楷模窗格,然后选择选择所有>选择测试在里面测试部分。该应用程序计算在完整数据集上培训的模型的测试集性能,包括培训和验证数据。
根据测试集的准确性对模型进行排序。在楷模窗格中,打开排序方式列表并选择
准确性(测试).在本例中,经过训练的可优化模型在测试集数据上的表现不如经过训练的预置模型。

在情节上节分类学习者选项卡上,选择混乱矩阵>测试数据.在媒体高斯SVM模型和优化的SVM模型之间切换,在视觉上比较两个混乱矩阵。










相关话题
您还可以从以下列表中选择一个网站:
