使用分类学习应用训练决策树
这个例子展示了如何使用classification Learner创建和比较各种分类树,以及如何将经过训练的模型导出到工作空间中,以对新数据进行预测。
您可以训练分类树来预测对数据的响应。要预测响应,请遵循树中的决策,从根(开始)节点一直到叶节点。叶节点包含响应。
统计和机器学习工具箱™树是二进制的。预测的每一步都包括检查一个预测器(变量)的值。例如,这是一个简单的分类树:
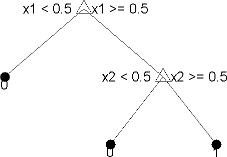
这棵树基于两个预测器来预测分类,x1和x2。要预测,从顶部节点开始。在每个决策中,检查预测器的值以决定遵循哪个分支。当分支到达叶节点时,数据被分类为type0或1。
在MATLAB®,加载
fisheriris数据集,并使用要用于分类的数据集中的变量创建一个度量预测器(或特性)表。fishertable = readtable (“fisheriris.csv”);在应用程序选项卡,机器学习和深度学习组中,单击分类学习者。
在分类学习者选项卡,文件部分中,点击来自工作空间的新会话>。

在New Session对话框中,选择表
fishertable从数据集变量列表(如果有必要)。观察应用程序已经根据它们的数据类型选择了响应和预测变量。花瓣和萼片长度和宽度预测,物种是你想要的反应分类。对于本例,不要更改选择。
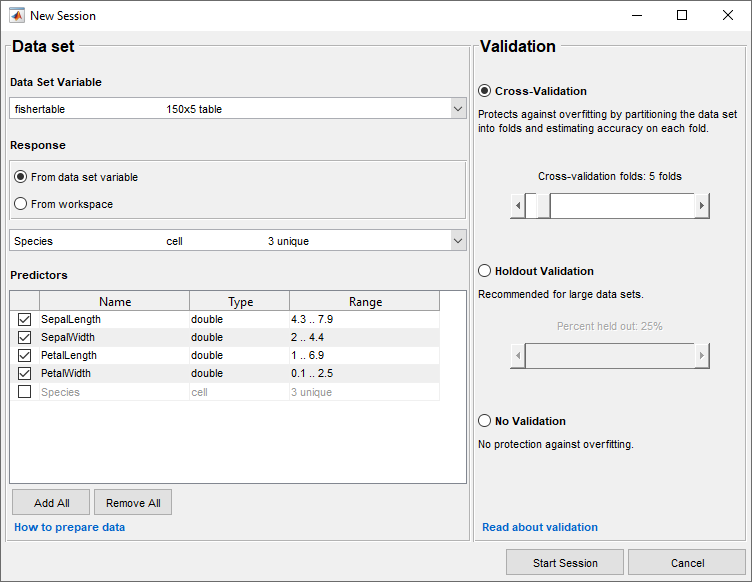
要接受默认验证方案并继续,请单击开始会议。默认的验证选项是交叉验证,以防止过拟合。
分类学习者创建数据的散点图。
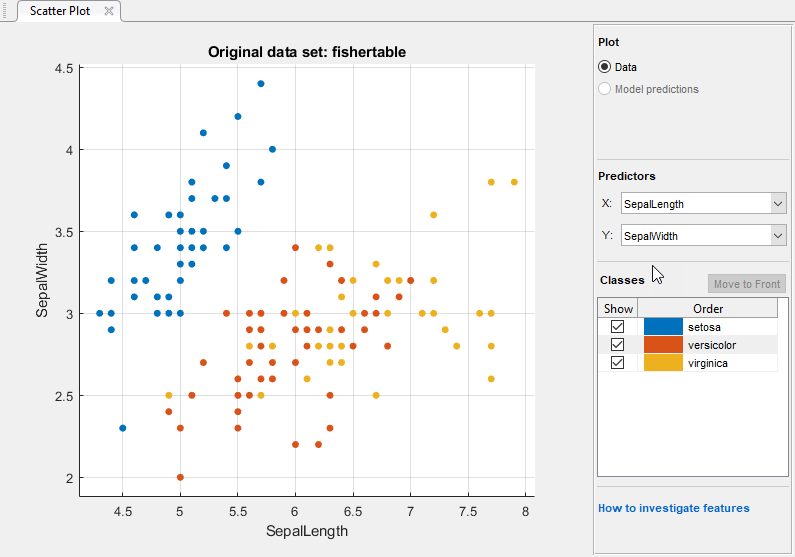
使用散点图调查哪些变量是有用的预测响应。选择不同的选项X和Y列表下预测使物种的分布和测量形象化。观察哪些变量能最清楚地区分物种的颜色。
观察到的
setosa品种(蓝色点)很容易从其他两个品种与所有四个预测。的多色的和virginica物种在所有的预测测量中更接近,特别是当你绘制萼片长度和宽度重叠。setosa比其它两个物种更容易预测。要创建一个分类树模型,对分类学习者选项卡,模型类型部分,单击向下箭头以展开图库并单击粗树。然后单击火车。
提示
如果你有并行计算工具箱™然后你第一次点击火车当应用程序打开一个并行工作程序池时,您会看到一个对话框。在池打开后,您可以一次训练多个分类器并继续工作。
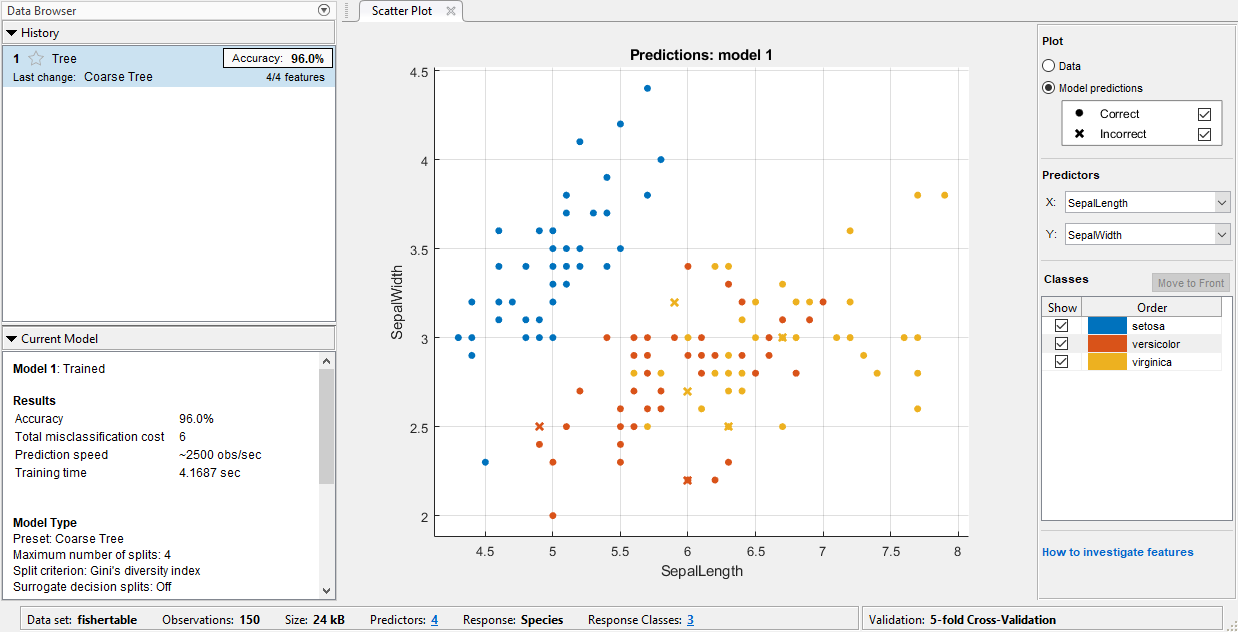
这个应用程序创建了一个简单的分类树,阴谋的结果。
观察粗树在历史列表中的模型。属性中的模型验证分数精度盒子。该模型表现。
请注意
对于验证,结果中存在一些随机性,因此您的模型验证评分结果可能与所显示的结果不同。
检查散点图。X表示分类错误的点。蓝点(
setosa物种)都是正确的分类,但其他两个物种的一些是错误的分类。下情节,在数据和模型的预测选项。观察错误点(X)的颜色。或者,在绘制模型预测图时,只查看不正确的点,清除正确的复选框。训练不同的模式比较。点击中树,然后单击火车。
当你点击火车时,应用程序会在历史列表中显示一个新模型。
观察中树在历史列表中的模型。模型验证得分并不比粗树得分好。该应用程序在一个方框中勾勒出
精度最佳模型的分数。单击历史列表中的每个模型来查看和比较结果。为。检查散点图中树模型。中等树与上一个粗树正确地分类了同样多的点。您想要避免过拟合,并且粗树表现良好,因此所有进一步的模型都基于粗树。
选择粗树在历史列表中。为了改进模型,尝试在模型中包含不同的特性。看看是否可以通过删除具有低预测能力的特征来改进模型。
在分类学习者选项卡,特性部分中,点击特征选择。
在“特性选择”对话框中,清除有关的复选框PetalLength和PetalWidth将它们排除在预测因子之外。一个新的草稿模型会出现在模型历史列表中,带有你的新设置2/4的特性,基于粗树。
点击火车利用新的预测器选项来训练新的树模型。
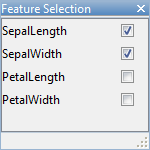
观察历史列表中的第三个模型。它也是一个粗树模型,仅使用4个预测因子中的2个进行训练。历史列表显示排除了多少预测器。要检查包含了哪些预测器,请单击历史列表中的一个模型,并观察“特性选择”对话框中的复选框。只有萼片尺寸的模型比只有花瓣尺寸的模型精度得分低得多。
训练另一个模型,只包括花瓣的尺寸。更改“特性选择”对话框中的选择并单击火车。
仅使用花瓣测量训练的模型与包含所有预测因子的模型的性能相当。使用所有测量值与仅使用花瓣测量值相比,模型预测的结果并不更好。如果数据收集很昂贵或很困难,您可能更喜欢不使用预测器而执行得令人满意的模型。
重复训练另外两个模型,包括宽度测量和长度测量。几种模型的得分没有太大差别。
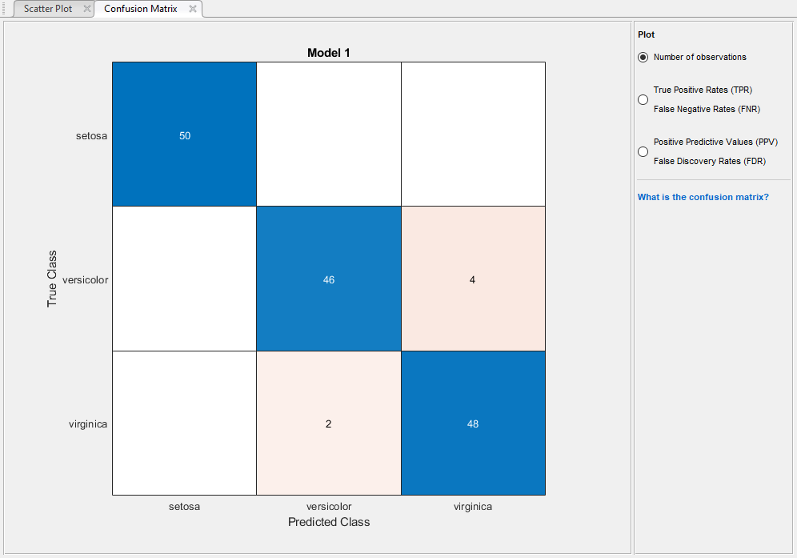
通过考察每个班级的表现,在相似分数的班级中选择一个最佳的模型。选择包含所有预测器的粗树。检查每堂课预测的准确性分类学习者选项卡,情节部分中,点击混淆矩阵。使用这个图来理解当前选择的分类器是如何在每个类中执行的。观察真类和预测类结果的矩阵。
通过检查对角线上显示高数字和红色的细胞来寻找分类器表现不佳的区域。在这些红细胞中,真实的类和预测的类不匹配。数据点分类错误。
请注意
通过验证,结果中存在一些随机性,因此混淆矩阵的结果可能与所显示的结果不同。
在该图中,检查中间行的第三个单元格。在这个单元格中,true class是
多色的,但模型将这些点错误地分类为virginica。对于这个模型,单元格显示了4个分类错误(结果可能会有所不同)。若要查看观察值的百分比而不是数量,请选择真正积极的利率选择下情节控制. .您可以使用这些信息来帮助您为您的目标选择最佳的模型。如果这个类中的假阳性对您的分类问题非常重要,那么选择预测这个类的最佳模型。如果这个类中的假阳性不是很重要,并且具有较少预测器的模型在其他类中表现更好,那么选择一个模型来权衡某些总体准确性,以排除某些预测器,并使未来的数据收集更容易。
比较历史记录列表中每个模型的混淆矩阵。选中Feature Selection对话框,查看每个模型中包含哪些预测器。
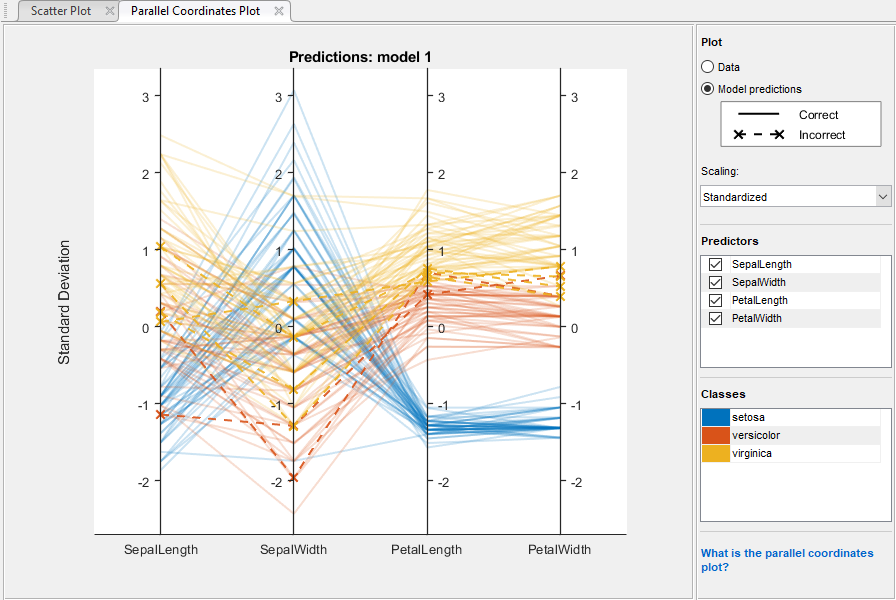
使用散点图和平行坐标图来调查要包括或排除的特征。在分类学习者选项卡,情节部分中,点击平行坐标图。你可以看到花瓣的长度和花瓣的宽度是区分类的最佳特征。
要了解模型设置,请在历史记录列表中选择一个模型并查看高级设置。中的不可优化模型选项模型类型图片库是预设的起始点,你可以改变进一步的设置。在分类学习者选项卡,模型类型部分中,点击先进的。比较历史记录中的简单树模型和中等树模型,并观察高级树选项对话框中的差异。的最大分割数设置控件树的深度。
为了进一步改进粗树模型,请尝试更改最大分割数设置,然后通过点击训练一个新模型火车。
在“当前模型”窗格或“高级”对话框中查看所选训练模型的设置。
将经过最佳训练的模型导出到工作空间分类学习者选项卡,出口部分中,点击出口模式。在导出模型对话框中,单击好吧接受默认变量名
trainedModel。在命令窗口中查看有关结果的信息。
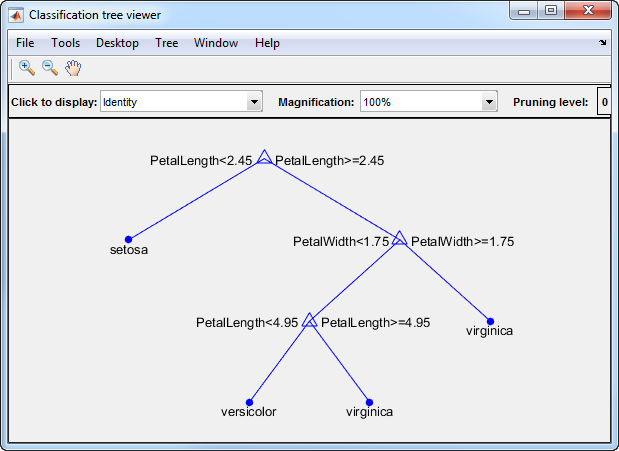
要使决策树模型可视化,请输入:
视图(trainedModel.ClassificationTree,“模式”,“图”)
您可以使用导出的分类器对新数据进行预测。例如,为
fishertable工作空间中的数据,请输入:输出yfit = trainedModel.predictFcn (fishertable)
yfit包含每个数据点的类预测。如果你想用新的数据自动训练同一个分类器,或者学习如何以编程的方式训练分类器,你可以从应用程序生成代码分类学习者选项卡,出口部分中,点击生成函数。
应用程序从模型生成代码并在MATLAB中显示文件编辑器。想了解更多,请看生成MATLAB代码,用新数据训练模型。








这个例子使用了Fisher 1936年的iris数据。虹膜数据包含了对三种标本的花的测量:花瓣长度、花瓣宽度、萼片长度和萼片宽度。训练一个分类器根据预测器的测量值来预测物种。
使用相同的工作流程来评估和比较您可以在Classification Learner中训练的其他分类器类型。
尝试所有不可优化的分类器模型预设为您的数据集:
的最右边的箭头模型类型节展开分类器列表。
点击所有,然后单击火车。

要了解其他分类器类型,请参见在分类学习者App中训练分类模型。
相关的话题
您也可以从以下列表中选择一个网站:
