两足机器人使用强化学习代理行走训练
这个例子展示了如何训练两足机器人行走使用深决定性策略梯度(DDPG)代理或twin-delayed深决定性策略梯度(TD3)代理。在这个例子中,您还比较这些训练有素的特工的性能。机器人在这个例子中是建模Simscape™多体™。
这些代理的更多信息,请参阅深决定性策略梯度(DDPG)代理和Twin-Delayed深确定性(TD3)政策梯度代理。
比较的目的在这个例子中,这个例子列车代理在双足机器人环境相同的模型参数。这个例子还配置代理有以下设置共同之处。
双足机器人的初始条件策略
网络结构的演员和评论家,灵感来自[1]
选择演员和评论家表示
培训方案(样品时间,折扣因素,mini-batch大小、经验缓冲区长度,探索噪音)
两足机器人模型
这个例子的强化学习环境是一个两足机器人。培训的目标是使机器人走直线使用最少的控制工作。
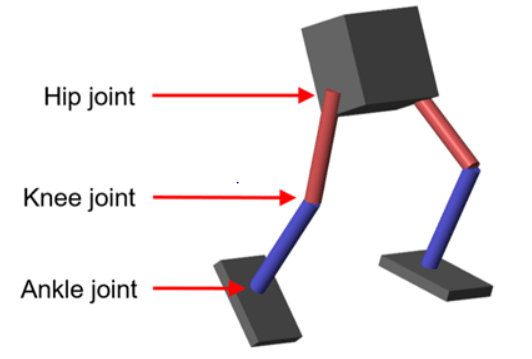
模型的参数加载到MATLAB®工作区。
robotParametersRL
打开仿真软件模型。万博1manbetx
mdl =“rlWalkingBipedRobot”;open_system (mdl)
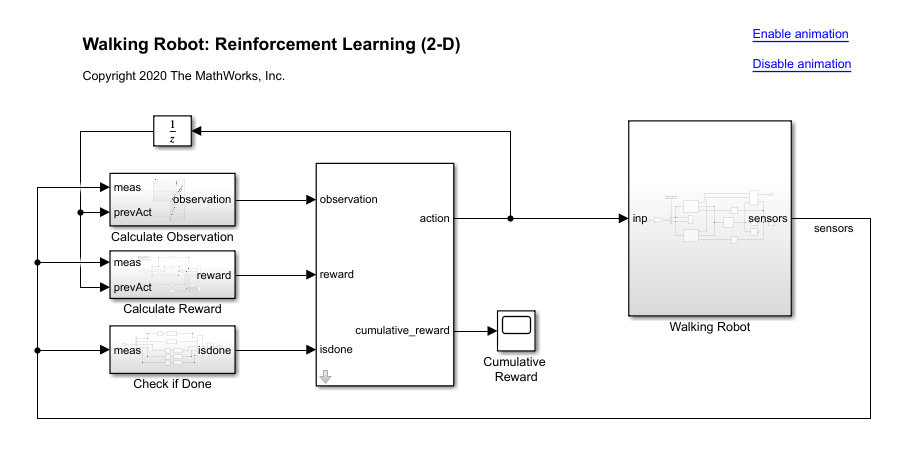
机器人使用Simscape多体建模。

对于这个模型:
在中性0 rad的位置,直腿和脚踝都是平的。
脚接触建模使用空间接触力(Simscape多体)块。
代理可以控制3个人关节(脚踝,膝盖和臀部)两腿机器人通过应用扭矩信号
3来3N·m。实际的行动之间的信号归一化计算1和1。
环境提供了以下29观测到代理。
Y(横向)和Z(垂直)躯干质心的翻译。翻译在Z方向是规范化类似其他观测范围。
X(向前),Y(横向)和Z(垂直)的翻译速度。
偏航、俯仰和滚角的躯干。
偏航、俯仰和躯干的转动角速度。
角位置和速度的三个关节(脚踝、膝盖、臀部)两腿。
从之前的时间步动作值。
这一事件终止如果下列条件发生。
机器人躯干质心小于0.1 m Z方向(机器人下降)或超过1 m Y方向(机器人移动到一边太远)。
的绝对值辊,球场上,或偏航大于0.7854 rad。
下面的回报函数 提供的,这是在每一个时间步的灵感来源于[2]。
在这里:
翻译速度在X方向(前进走向目标)的机器人。
是机器人的横向位移翻译从目标直线轨迹。
规范化是垂直翻译机器人质心的位移。
是联合的扭矩我从之前的时间步。
是环境的样品时间。
是最后的仿真环境的时间。
这个奖励函数鼓励代理前进通过提供积极的奖励积极的前进速度。它还鼓励代理避免事件终止通过提供一个恒定的奖励( 在每个时间步)。奖励函数中的其他条款处罚大量的横向和纵向的变化翻译,和过度的使用控制的努力。
创建环境接口
创建观测规范。
numObs = 29;obsInfo = rlNumericSpec ([numObs 1]);obsInfo。Name =“观察”;
创建操作规范。
numAct = 6;actInfo = rlNumericSpec (numAct [1], LowerLimit = 1, UpperLimit = 1);actInfo。Name =“foot_torque”;
创建环境界面的步行机器人模型。
黑色= mdl +“/ RL代理”;env = rl万博1manbetxSimulinkEnv (mdl,黑色,obsInfo actInfo);env。ResetFcn = @(在)walkerResetFcn (,…upper_leg_length / 100,…lower_leg_length / 100,…h / 100);
选择和创建代理培训
这个示例提供了选择训练机器人使用DDPG或TD3代理。模拟机器人与您所选择的代理设置AgentSelection相应的国旗。
AgentSelection =“DDPG”;开关AgentSelection情况下“DDPG”代理= createDDPGAgent (numObs obsInfo、numAct actInfo, Ts);情况下“TD3”代理= createTD3Agent (numObs obsInfo、numAct actInfo, Ts);否则disp (“给DDPG AgentSelection或TD3”)结束
的createDDPGAgent和createTD3Agent辅助函数执行以下操作。
创建演员兼评论家网络。
为演员和评论家表示指定选项。
使用创建网络创建演员和评论家表示和指定的选项。
配置代理特定选项。
创建代理。
DDPG代理
DDPG代理使用参数化确定性政策连续动作空间,由一个连续确定的演员,学会了和一个参数化核反应能量函数的估计值来估算价值的政策。利用神经网络模型的政策和核反应能量函数。这个例子的演员和评论家网络受[1]。
有关如何创建DDPG代理时,看到的createDDPGAgenthelper函数。配置选项DDPG代理信息,请参阅rlDDPGAgentOptions。
更多信息创建一个深层神经网络价值函数表示,看到的创建政策和价值功能。为一个示例,该示例创建了神经网络DDPG代理,明白了火车DDPG剂来控制双积分器系统。
TD3代理
的评论家DDPG代理可以高估的Q值。由于代理使用Q值来更新其政策(演员),由此产生的政策可能是次优的,可以积累训练的错误可以导致不同的行为。TD3算法是DDPG的扩展和改进,使其更加健壮,防止高估的Q值[3]。
两个评论家网络——TD3代理独立学习两个评论家网络和使用最小值函数估计更新演员(政策)。这样做可以防止误差积累在随后的步骤和过高的Q值。
添加噪声目标政策——添加剪噪音值函数平滑Q函数值在类似的行动。这样做可以防止学习不正确的顶点嘈杂的价值的估计。
延迟政策和目标更新——TD3代理,延迟问的演员网络更新允许更多的时间函数来减少错误(接近所需的目标)之前更新的政策。这样做可以防止方差值估计和结果在一个更高的质量政策更新。
演员和评论家的结构网络用于这个代理是一样的用于DDPG代理。在创建TD3代理的详细信息,请参阅createTD3Agenthelper函数。配置选项TD3代理信息,请参阅rlTD3AgentOptions。
指定培训方案和培训代理
对于这个示例,训练选项DDPG和TD3代理都是一样的。
运行每个训练2000集,每集持久的最多
maxSteps时间的步骤。在事件管理器对话框显示培训进展(设置
情节在命令行选项)和禁用显示(设置详细的选项)。终止训练只有当它达到的最大数量集(
maxEpisodes)。这样做允许的学习曲线的比较多个代理在整个训练。
和额外的选项的更多信息,见rlTrainingOptions。
maxEpisodes = 2000;maxSteps =地板(Tf / Ts);trainOpts = rlTrainingOptions (…MaxEpisodes = MaxEpisodes,…MaxStepsPerEpisode = maxSteps,…ScoreAveragingWindowLength = 250,…Verbose = false,…情节=“训练进步”,…StopTrainingCriteria =“EpisodeCount”,…StopTrainingValue = maxEpisodes,…SaveAgentCriteria =“EpisodeCount”,…SaveAgentValue = maxEpisodes);
培训代理并行,指定以下培训选项。并行训练需要并行计算工具箱™。如果你没有安装并行计算工具箱软件,集UseParallel来假。
设置
UseParallelt选项街。火车异步并行代理。
每32个步骤之后,每个工人送经验平行池客户机(MATLAB®流程启动培训)。DDPG和TD3代理要求员工向客户发送的经历。
trainOpts。UseParallel = true;trainOpts.ParallelizationOptions。模式=“异步”;trainOpts.ParallelizationOptions。StepsUntilDataIsSent = 32;trainOpts.ParallelizationOptions。DataToSendFromWorkers =“经验”;
火车代理使用火车函数。这个过程是计算密集型和每个代理需要几个小时才能完成。节省时间在运行这个例子中,加载一个pretrained代理设置doTraining来假。训练自己代理,集doTraining来真正的。由于随机性在并行训练,你可以期待不同的训练结果的情节。并行pretrained代理被训练使用四个工人。
doTraining = false;如果doTraining%培训代理。trainingStats =火车(代理,env, trainOpts);其他的%加载pretrained代理为选定的代理类型。如果比较字符串(AgentSelection“DDPG”)负载(“rlWalkingBipedRobotDDPG.mat”,“代理”)其他的负载(“rlWalkingBipedRobotTD3.mat”,“代理”)结束结束


前面的示例训练曲线,每一步DDPG训练的平均时间,TD3代理0.11和0.12秒,分别。TD3代理每一步,因为它需要更多的训练时间更新两个评论家网络用于DDPG相比单一的评论家。
模拟训练有素的特工
解决随机发生器再现性的种子。
rng (0)
验证培训代理的性能,模拟在两足机器人的环境。代理模拟更多的信息,请参阅rlSimulationOptions和sim卡。
simOptions = rlSimulationOptions (MaxSteps = MaxSteps);经验= sim (env,代理,simOptions);

对比剂的性能
以下代理比较,每个代理训练5次每次使用不同的随机种子。由于随机探索噪声和随机并行训练,每个运行的学习曲线是不同的。代理多个培训以来的运行需要好几天才能完成,这个比较使用pretrained代理。
DDPG和TD3代理、情节的平均和标准偏差事件奖励(情节)和集Q0值(图)。集Q0值贴现的评论家估计长期奖励在每集的开始给定的初始观察环境。对于一个设计良好的评论家,集Q0值方法真正的折扣的长期回报。
comparePerformance (“DDPGAgent”,“TD3Agent”)


基于学习曲线比较图:
DDPG代理似乎加快学习速度(平均约一集600号)但达到一个局部最小值。TD3启动较慢但最终达到比DDPG更高的回报,因为它避免了过高的Q值。
TD3代理显示稳步改善它的学习曲线,这表明DDPG代理相比,改进的稳定。
基于集Q0对比图:
TD3代理,贴现的评论家估计长期奖励(2000集)较低相比DDPG代理。这种差异是由于TD3算法采用保守的方法在更新其目标通过使用至少两个问的功能。这种行为进一步加强,因为延迟更新目标。
尽管这些2000集的TD3估计低,TD3代理集Q0值,显示了一个稳定的增加与DDPG代理。
在这个例子中,训练是停在2000集。更大的训练时期,TD3代理稳步增长的估计显示可能收敛于真实的折扣的长期回报。
在另一个例子如何培养一个仿人机器人行走使用DDPG代理,看看火车人形沃克(Simscape多体)。例如如何训练四足机器人行走使用DDPG代理,看看四足机器人运动使用DDPG代理。
引用
[1]Lillicrap,蒂莫西·P。,Jonathan J. Hunt, Alexander Pritzel, Nicolas Heess, Tom Erez, Yuval Tassa, David Silver, and Daan Wierstra. "Continuous Control with Deep Reinforcement Learning." Preprint, submitted July 5, 2019.https://arxiv.org/abs/1509.02971。
[2]Heess,尼古拉斯,Dhruva结核病,Srinivasan·杰伊·雷蒙Josh梅瑞尔格雷格•韦恩Yuval Tassa, et al。“丰富环境中的运动行为的出现。”Preprint, submitted July 10, 2017.https://arxiv.org/abs/1707.02286。
[3]藤本,斯科特,Herke范霍夫,David Meger和。“解决函数近似误差Actor-Critic方法”。Preprint, submitted October 22, 2018.https://arxiv.org/abs/1802.09477。
另请参阅
功能
对象
rlDDPGAgent|rlDDPGAgentOptions|rlTD3Agent|rlTD3AgentOptions|rlQValueFunction|rlContinuousDeterministicActor|rlOptimizerOptions|rlTrainingOptions|rlSimulationOptions