标签数据使用Semi-Supervised学习技术
这个例子展示了如何使用基于和自我训练semi-supervised学习技术标签数据。
Semi-supervised学习监督学习的结合方面,所有训练数据的标记,和无监督学习,真正的标签是未知的。一些训练观察标记,但绝大多数没有标记。Semi-supervised学习方法试图利用底层的数据结构以适应标签无标号数据。
统计和机器学习工具箱™提供这些semi-supervised学习功能分类:
fitsemigraph结构相似度图与标记和未标记观察节点,从标签和分发标签信息标记观察观察。fitsemiself对数据迭代训练分类器。第一,功能训练一个分类器单独带安全标签的数据时,然后使用标签,分类器的预测无标号数据。fitsemiself提供成绩的预测,然后对预测为未来真正的标签分类器的训练周期,如果分数超过一定阈值。重复这个过程,直到标签预测收敛。
生成数据
生成数据从两个半月的形状。确定哪些月球新分属于利用图论和自我训练semi-supervised技术。
创建自定义函数twomoons(如图所示的这个例子)。这个函数接受一个输入参数n并创建n点的两个交错半月:月球上月球凹下来一个下凹的。
生成一组40标记数据点通过twomoons函数。每一个点的X的两个卫星,月球与相应的标签中存储向量标签。
rng (“默认”)%的再现性[X,标签]= twomoons (20);
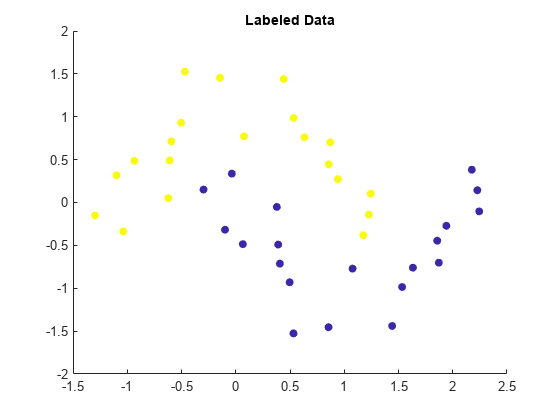
利用散点图可视化的点。分在同一个月亮有相同的颜色。
散射(X (: 1) X(:, 2),[],标签,“填充”)标题(“带安全标签的数据”)
生成一组400年的无标号数据点通过twomoons函数。每一个点的newX属于其中一个卫星,但相应的月球标签是未知的。
newX = twomoons (200);
使用基于标签数据的方法
标签中的无标号数据newX通过使用半监督图论方法。默认情况下,fitsemigraph从数据结构相似度图X和newX,并使用一个标签传播技术以适应标签newX。
graphMdl = fitsemigraph (X,标签,newX)
graphMdl = SemiSupervisedGraphModel属性:FittedLabels: x1双[400]LabelScores: [400 x2双]一会:[1 - 2]ResponseName:“Y”CategoricalPredictors:[]方法:“labelpropagation”属性,方法
函数返回一个SemiSupervisedGraphModel的对象FittedLabels属性包含了安装的无标号数据和标签LabelScores属性包含分数相关的标签。
可视化安装标签使用散点图的结果。使用安装标签设置点的颜色,并使用标签的最大成绩的透明度设置点。点透明度较低标以更大的信心。
maxGraphScores = max (graphMdl.LabelScores [], 2);rescaledGraphScores =重新调节(maxGraphScores, 0.05, 0.95);散射(newX (: 1) newX (:, 2), [], graphMdl.FittedLabels,“填充”,…“MarkerFaceAlpha”,“平”,“AlphaData”,rescaledGraphScores);标题([“无标号数据安装标签”,“(基于)”])
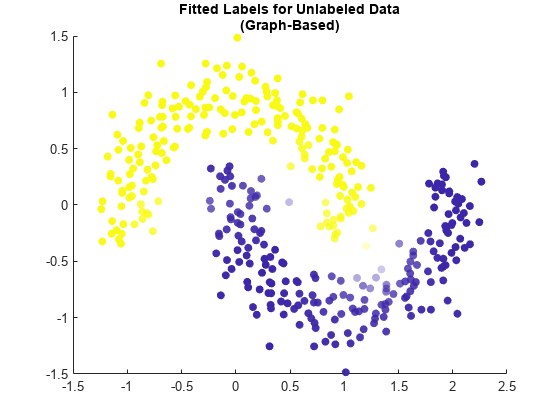
这个方法似乎标签newX准确点。两个月亮是视觉上不同的,最多的点标记为不确定性躺在两者之间的边界形状。
标签数据使用自我训练方法
标签中的无标号数据newX通过使用半监督自我训练方法。默认情况下,fitsemiself使用支持向量机万博1manbetx(SVM)模型的高斯核标签数据迭代。
selfSVMMdl = fitsemiself (X,标签,newX)
selfSVMMdl = SemiSupervisedSelfTrainingModel属性:FittedLabels: x1双[400]LabelScores: [400 x2双]一会:[1 - 2]ResponseName:“Y”CategoricalPredictors:[]学习者:[1 x1 classreg.learning.classif。CompactClassificationSVM]属性,方法
函数返回一个SemiSupervisedSelfTrainingModel的对象FittedLabels属性包含了安装的无标号数据和标签LabelScores属性包含分数相关的标签。
可视化安装标签使用散点图的结果。和之前一样,使用安装标签设置点的颜色,并使用标签的最大成绩的透明度设置点。
maxSVMScores = max (selfSVMMdl.LabelScores [], 2);rescaledSVMScores =重新调节(maxSVMScores, 0.05, 0.95);散射(newX (: 1) newX (:, 2), [], selfSVMMdl.FittedLabels,“填充”,…“MarkerFaceAlpha”,“平”,“AlphaData”,rescaledSVMScores);标题([“无标号数据安装标签”,”(自我训练SVM):“])
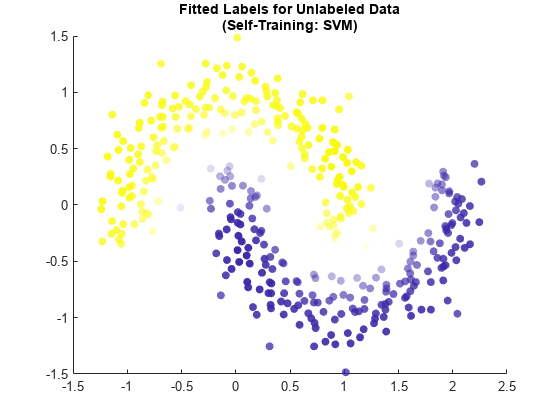
这种方法,支持向量机的学习者,也似乎标签newX准确点。两个月亮是视觉上不同的,最多的点标记为不确定性躺在两者之间的边界形状。
有些学习者可能不是标签无标号数据有效,然而。例如,使用一个树模型而不是默认的标签数据的支持向量机模型newX。
newX selfTreeMdl = fitsemiself (X,标签,“学习者”,“树”);
可视化安装标签的结果。
maxTreeScores = max (selfTreeMdl.LabelScores [], 2);rescaledTreeScores =重新调节(maxTreeScores, 0.05, 0.95);散射(newX (: 1) newX (:, 2), [], selfTreeMdl.FittedLabels,“填充”,…“MarkerFaceAlpha”,“平”,“AlphaData”,rescaledTreeScores);标题([“无标号数据安装标签”,”(自我训练:树)”])

这种方法,与树的学习者,贴错标签的许多点在月球。当你使用半监督自我训练方法,请确保使用一个潜在的学习者适合您的数据的结构。
这段代码创建函数twomoons。
函数[X,标签]= twomoons (n)%生成两个月亮,n个点在每个月球。%相关指定半径和角度两个月亮。噪音= (1/6)。* randn (n, 1);半径= 1 +噪声;angle1 =π+π/ 10;angle2 =π/ 10;%创建月球底部中心(1,0)。bottomTheta = linspace (-angle1 angle2 n)”;bottomX1 =半径。* cos (bottomTheta) + 1;bottomX2 =半径。* sin (bottomTheta);%创建月球的顶部中心(0,0)。topTheta = linspace (angle1 -angle2 n)”;topX1 =半径。* cos (topTheta);topX2 =半径。* sin (topTheta);%返回月球点和他们的标签。X = [bottomX1 bottomX2;topX1 topX2];标签=[的(n - 1);2 * 1 (n, 1)];结束