TreeBagger
袋装决策树的合奏
描述
一个TreeBagger对象是袋装的整体决策树分类或回归。个人决策树overfit。装袋代表引导聚合,它是一个方法,减少过度拟合的影响,提高了泛化。
创建
的TreeBagger函数的每棵树生长TreeBagger使用引导整体模型的样本输入数据。观察不包含在样本被认为是“out-of-bag”那棵树。函数的随机选择一个子集预测每个决定分割利用随机森林算法[1]。
语法
描述
提示
默认情况下,TreeBagger功能分类决策树生长。增长回归决策树,指定名称的论点方法作为“回归”。
Mdl= TreeBagger (NumTrees,资源描述,ResponseVarName)Mdl)NumTrees袋装分类树,训练有素的预测表资源描述在变量和类标签Tbl.ResponseVarName。
输入参数
输出参数
属性
对象的功能
例子
火车的袋装分类树
创建一个合奏袋装分类树的费雪的虹膜数据集。然后,把第一次种植的树,情节out-of-bag分类错误,和预测out-of-bag观察标签。
加载fisheriris数据集创建。X作为一个数字矩阵,包含四个花瓣测量150虹膜。创建Y作为一个单元阵列包含相应的特征向量的虹膜的物种。
负载fisheririsX =量;Y =物种;
设置随机数字生成器默认的再现性。
rng (“默认”)
火车一袋装分类树的整个数据集。指定使用50弱的学习者。每棵树的存储out-of-bag观测。默认情况下,TreeBagger深树生长。
Mdl = TreeBagger (50, X, Y,…方法=“分类”,…OOBPrediction =“上”)
Mdl = TreeBagger合奏与50袋装决策树:训练X: [150 x4)培训Y: [150 x1)方法:分类NumPredictors: 4 NumPredictorsToSample: 2 MinLeafSize: 1 InBagFraction: 1 SampleWithReplacement: 1 ComputeOOBPrediction: 1 ComputeOOBPredictorImportance: 0距离:[]一会:“setosa”“杂色的”“virginica”属性,方法
Mdl是一个TreeBagger系综分类树。
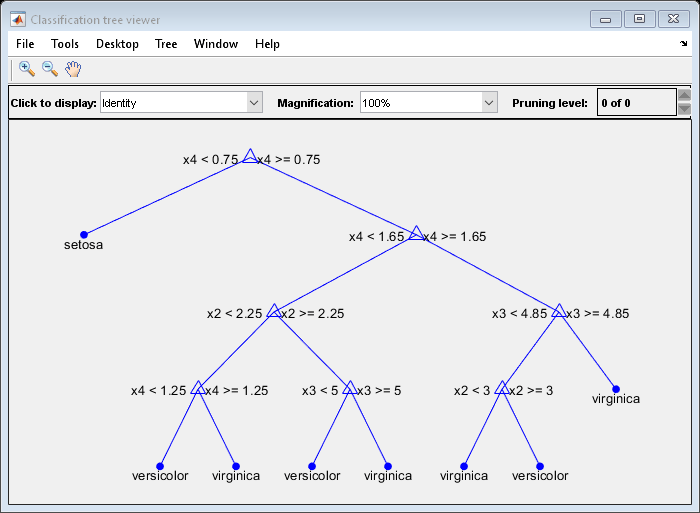
的Mdl.Trees属性是一个50-by-1细胞向量包含合奏训练分类树。每棵树是一个CompactClassificationTree对象。查看图形显示的第一个训练有素的分类树。
视图(Mdl.Trees{1},模式=“图”)
情节out-of-bag分类错误的数量分类树。
情节(oobError (Mdl)包含(“种植树木数量”)ylabel (“Out-of-Bag分类错误”)
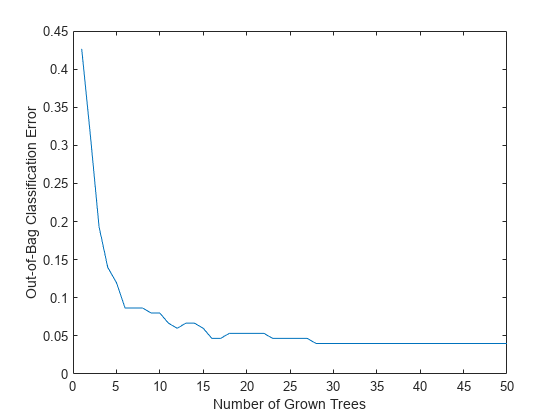
out-of-bag误差减少种植树木的数量增加。
预测out-of-bag观察标签。显示结果为一组随机的10的观察。
oobLabels = oobPredict (Mdl);印第安纳州= randsample(长度(oobLabels), 10);表(Y(印第安纳州),oobLabels(印第安纳州),…VariableNames = [“TrueLabel”“PredictedLabel”])
ans =10×2表是_____________ TrueLabel PredictedLabel * * * {‘setosa} {‘setosa} {‘virginica} {‘virginica} {‘setosa} {‘setosa} {‘virginica} {‘virginica} {‘setosa} {‘setosa} {‘virginica} {‘virginica} {‘setosa} {‘setosa}{“癣”}{“癣”}{“癣”}{‘virginica} {‘virginica} {' virginica '}
火车的袋装回归树
创建一个袋装回归树的合奏carsmall数据集。然后,预测条件意味着反应和有条件的四分位数。
加载carsmall数据集创建。X包含汽车发动机作为一个数字矢量位移值。创建Y作为一个数值向量包含相应的英里每加仑。
负载carsmallX =位移;Y = MPG;
设置随机数字生成器默认的再现性。
rng (“默认”)
火车一袋装回归树使用整个数据集。指定100弱的学习者。
Mdl = TreeBagger (100 X, Y,…方法=“回归”)
Mdl = TreeBagger合奏与100袋装决策树:训练X: x1[94]培训Y: [94 x1)方法:回归NumPredictors: 1 NumPredictorsToSample: 1 MinLeafSize: 5 InBagFraction: 1 SampleWithReplacement: 1 ComputeOOBPrediction: 0 ComputeOOBPredictorImportance: 0距离:[]属性,方法
Mdl是一个TreeBagger回归树的合奏。
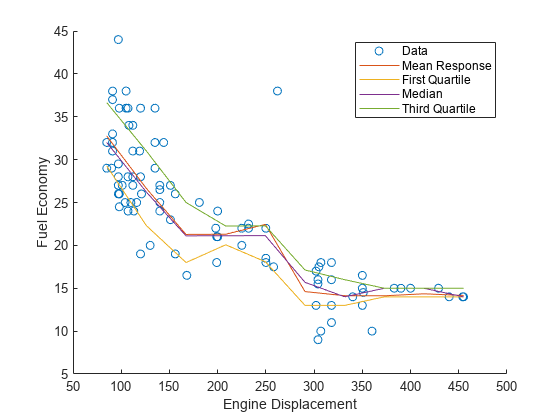
10等距的引擎位移之间的最小和最大样本内位移,预测条件均值反应(YMean)和有条件的四分位数(YQuartiles)。
predX = linspace(最小(X)最大(X) 10) ';predX YMean =预测(Mdl);YQuartiles = quantilePredict (Mdl predX,…分位数= [0.25,0.5,0.75]);
情节的观察,估计意思是回应,估计四分位数。
持有在情节(X, Y,“o”);情节(predX YMean)情节(predX YQuartiles)从ylabel (“燃料经济”)包含(“发动机排量”)传说(“数据”,“平均响应”,…“第一四分位数”,“中值”,…,“第三四分位数”)
无偏预测重要性估计袋装回归树
创建两个乐团袋装回归树,一个使用标准的购物车将预测的算法,和其他使用曲率检测分割预测。然后,比较预测重要性估计两个乐团。
加载carsmall数据集和转换变量气缸,制造行业,Model_Year分类变量。然后,显示类别的数量代表的分类变量。
负载carsmall气缸=分类(缸);及时通知=分类(cellstr (Mfg));Model_Year =分类(Model_Year);元素个数(类别(气缸))
ans = 3
元素个数(类别(有限公司))
ans = 28
元素个数(类别(Model_Year))
ans = 3
创建一个表,其中包含八个指标。
台=表(加速、气缸、位移,…马力,生产厂,Model_Year、重量、MPG);
设置随机数字生成器默认的再现性。
rng (“默认”)
火车200袋装回归树的整体使用整个数据集。因为数据缺失值,指定使用代理分裂。商店的out-of-bag信息预测评估的重要性。
默认情况下,TreeBagger使用标准的车,一个分裂算法预测。因为变量气缸和Model_Year每只包含三个类别,标准的车喜欢分裂连续预测这两个变量。
MdlCART = TreeBagger(200台,“英里”,…方法=“回归”代理=“上”,…OOBPredictorImportance =“上”);
TreeBagger商店预测重要性估计房地产OOBPermutedPredictorDeltaError。
impCART = MdlCART.OOBPermutedPredictorDeltaError;
200年训练随机森林回归树使用整个数据集。无偏树木生长,指定使用曲率检测分割预测。
MdlUnbiased = TreeBagger(200台,“英里”,…方法=“回归”代理=“上”,…PredictorSelection =“弯曲”,…OOBPredictorImportance =“上”);impUnbiased = MdlUnbiased.OOBPermutedPredictorDeltaError;
创建酒吧图表比较预测重要性估计impCART和impUnbiased两个乐团。
tiledlayout(1、2、填充=“紧凑”);nexttile栏(impCART)标题(“标准车”)ylabel (“预测重要性估计”)包含(“预测”甘氨胆酸)h =;h。XTickLabel = MdlCART.PredictorNames; h.XTickLabelRotation = 45; h.TickLabelInterpreter =“没有”;nexttile酒吧(impUnbiased);标题(“弯曲测试”)ylabel (“预测重要性估计”)包含(“预测”甘氨胆酸)h =;h。XTickLabel = MdlUnbiased.PredictorNames; h.XTickLabelRotation = 45; h.TickLabelInterpreter =“没有”;
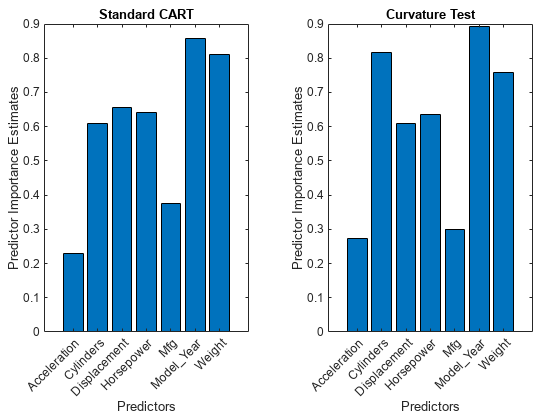
车模型,连续的预测重量是第二个最重要的因素。公正的模型,预测的重要性重量较小的值和排名。
火车的袋装分类树高大的数组
火车一个观察的袋装分类树高的数组,并找到每棵树的误分类概率加权观测模型。下面的例子使用了数据集airlinesmall.csv,一个大的数据集,其中包含一个表格文件航空公司飞行数据。
当你执行计算高数组,MATLAB®使用一个平行池(默认如果你有并行计算工具箱™)或当地的MATLAB会话。要运行示例使用当地的MATLAB会话并行计算工具箱后,改变全球执行环境使用mapreduce函数。
mapreduce (0)
创建一个引用的位置数据存储文件夹包含变量的数据集。选择一个子集,和治疗“NA”价值观缺失的数据,这样数据存储函数替换他们南值。创建高表tt包含数据存储中的数据。
ds =数据存储(“airlinesmall.csv”);ds。年代electedVariableNames = [“月”“DayofMonth”“DayOfWeek”,…“DepTime”“ArrDelay”“距离”“DepDelay”];ds。TreatAsMissing =“NA”;tt =高(ds)
tt = Mx7高表月DayofMonth DayOfWeek DepTime ArrDelay距离DepDelay _____ _____ _____ _________ ________说21日3 642 296 308 12 10 26 1 1021 8 1 10 23 5 2055 21 480 1332 10 23 5 13 296年12 10 22 4 629 373 1 10 28 3 1446 59 308 63 10 8 4 928 447 2 10 10 6 859 11 954 1::::::::::::::
确定航班,迟到10分钟或更多通过定义一个逻辑变量,适用于晚期飞行。该变量包含的类标签Y。预览这个变量包括前几行。
Y = tt。DepDelay > 10
Y = mx₁高逻辑数组1 0 1 1 0 1 0 0::
创建一个高的数组X的预测数据。
X = tt {: 1: end-1}
X = Mx6双矩阵10 21 3 642 8 308年10 26 1 1021 8 296 1332年10 23 5 2055 21 480 23日5 13 296 10 22 4 629 4 373 10 28 3 1446 59 308 859 8 4 928 447 10 10 6 954年11::::::::::::
创建一个高的数组W观察权重的任意分配权重的在课堂上观察1两倍。
W = Y + 1;
删除行X,Y,W含有缺失数据。
R = rmmissing ([X Y W]);X = R (:, 1: end-2);Y = R (:, end-1);W = R(:,结束);
火车一个20袋装分类树使用整个数据集。指定权向量和统一的先验概率。再现性,设置使用随机数生成器的种子rng和tallrng。结果取决于工人的数量和执行环境高数组。有关详细信息,请参见控制你的代码运行。
rng (“默认”)tallrng (“默认”)tMdl = TreeBagger (20, X, Y,…重量= W =“统一”)
评估高表达式使用当地的MATLAB会话:通过1 1:在0.72秒完成评估在0.89秒完成评估高表达式使用本地MATLAB会话:-通过1对1:在1.2秒完成评估在1.3秒完成评估高表达式使用本地MATLAB会话:-通过1对1:在4.3秒完成评估在4.3秒完成
tMdl = CompactTreeBagger合奏20袋装决策树:方法:分类NumPredictors: 6类名:' 0 ' ' 1 '的属性,方法
tMdl是一个CompactTreeBagger合奏与20袋装决策树。对于高数据,TreeBagger函数返回一个CompactTreeBagger对象。
每棵树的计算错误分类概率模型。中包含的属性权重向量W观察使用权重名称-值参数。
恐怖分子=错误(tMdl, X, Y,权重= W)
评估高表达式使用当地的MATLAB会话:通过1 1:在4.8秒完成评估在4.8秒完成
恐怖分子=20×10.1420 0.1214 0.1115 0.1078 0.1037 0.1027 0.1005 0.0997 0.0981 0.0983⋮
找到的平均误分类概率决策树的合奏。
avg_terr =意味着(恐怖分子)
avg_terr = 0.1022
更多关于
提示
对于一个
TreeBagger模型Mdl,树属性包含一个细胞的向量Mdl.NumTreesCompactClassificationTree或CompactRegressionTree对象。视图的图形化显示t成长树通过输入:视图(Mdl.Trees {t})对于回归问题,
TreeBagger万博1manbetx支持的意思,分位数回归(即分位数回归森林[5])。预测是指反应或估计的均方误差数据,通过一个
TreeBagger模型对象和数据预测或错误,分别。为out-of-bag观察执行类似的操作,使用oobPredict或oobError。估计响应分布分位数或给定的分位数错误数据,通过一个
TreeBagger模型对象和数据quantilePredict或quantileError,分别。为out-of-bag观察执行类似的操作,使用oobQuantilePredict或oobQuantileError。
标准车往往选择分裂预测包含许多不同的值,如连续变量,在那些包含几个不同的值,如分类变量[4]。考虑指定曲率或交互测试如果以下是正确的:
相对较少的数据预测不同值比其它预测;例如,预测数据集是异构的。
你的目标是分析预测的重要性。
TreeBagger商店预测估计的重要性OOBPermutedPredictorDeltaError财产。
在指标选择的更多信息,见名称参数
PredictorSelection分类树或名称参数PredictorSelection回归树。
算法
如果你指定
成本,之前,权重名称-值参数,输出模型对象存储指定的值成本,之前,W属性,分别。的成本属性存储指定的成本矩阵(C没有修改。的之前和W属性存储先验概率和观察权重,分别归一化后。模型训练,软件更新先验概率和观察权重将描述的惩罚成本矩阵。有关详细信息,请参见误分类代价矩阵、先验概率和观察权重。的
TreeBagger由过采样函数生成在袋子样品类大误分类代价采样类小误分类代价。因此,out-of-bag样本较少的观察从类大误分类代价和更多的观察类小误分类代价。如果你训练一个分类合奏使用一个小的数据集和一个高度倾斜成本矩阵,然后out-of-bag观察每个类的数量可能非常低。因此,估计out-of-bag错误可能有一个大的方差和难以解释。同样的现象也发生类先验概率大。
选择功能
统计和机器学习工具箱™装袋和随机森林提供了三个对象:
ClassificationBaggedEnsemble创建的对象fitcensemble函数的分类RegressionBaggedEnsemble创建的对象fitrensemble函数回归TreeBagger创建的对象TreeBagger功能分类和回归
对于细节的差异TreeBagger和袋装集合体(ClassificationBaggedEnsemble和RegressionBaggedEnsemble),看比较TreeBagger和袋装的集合体。
引用
[1]Breiman,狮子座。“随机森林。”机器学习45 (2001):5-32。https://doi.org/10.1023/A: 1010933404324。
[2]Breiman,狮子座,杰罗姆·弗里德曼,查尔斯·j·斯通和r . a . Olshen。分类和回归树。波卡拉顿,FL: CRC出版社,1984年。
[3]Loh,阴虚。“回归树与公正的变量选择和交互检测。”Statistica中央研究院12,没有。2 (2002):361 - 386。https://www.jstor.org/stable/24306967。
[4]Loh,阴虚,Yu-Shan施。“分裂选择分类树。”Statistica中央研究院7,不。4 (1997):815 - 840。https://www.jstor.org/stable/24306157。
[5]Meinshausen,尼科莱。“分位数回归森林。”机器学习研究杂志》上7,不。35 (2006):983 - 999。https://jmlr.org/papers/v7/meinshausen06a.html。
[6]膝,罗宾,jean - michel Poggi Christine Tuleau-Malot,娜塔莉Villa-Vialanei。对大数据“随机森林。”大数据的研究9 (2017):28-46。https://doi.org/10.1016/j.bdr.2017.07.003。