基于模糊c均值聚类的准随机数据聚类
这个例子展示了如何使用准随机二维数据进行FCM聚类。
加载数据集并绘制它。
负载fcmdata.dat情节(fcmdata (: 1) fcmdata (:, 2),“o”)

接下来,调用命令行函数,fcm,在这个数据集中找到两个聚类,直到目标函数不再减少很多。
[center,U,objFcn] = fcm(fcmdata,2);
迭代计数= 1,obj。fcn = 8.970479迭代计数= 2,obj。fcn = 7.197402迭代计数= 3,obj。fcn = 6.325579迭代计数= 4,obj。fcn = 4.586142迭代计数= 5,obj。fcn = 3.893114迭代计数= 6,obj。fcn = 3.810804迭代计数= 7,obj。fcn = 3.799801迭代计数= 8,obj。fcn = 3.797862迭代计数= 9,obj。fcn = 3.797508迭代计数= 10,obj。 fcn = 3.797444 Iteration count = 11, obj. fcn = 3.797432 Iteration count = 12, obj. fcn = 3.797430
中心包含两个集群中心的坐标,U包含每个数据点的成员级别和objFcn包含目标函数在迭代过程中的历史。
的fcm函数是构建在以下例程之上的迭代循环:
initfcm-初始化问题distfcm-进行欧氏距离计算stepfcm-执行一次聚类迭代
为了查看聚类的进展情况,可以绘制目标函数。
图(objFcn)“目标函数值”)包含(迭代计算的) ylabel (“目标函数值”)

最后,绘制由fcm函数。图中的大字表示集群中心。
maxU = max(U);index1 = find(U(1,:) == maxU);index = find(U(2,:) == maxU);图line(fcmdata(index1,1), fcmdata(index1,2),“线型”,...“没有”,“标记”,“o”,“颜色”,‘g’1)线(fcmdata (index2), fcmdata (index2, 2),“线型”,...“没有”,“标记”,“x”,“颜色”,“r”)举行在情节(中心(1,1),中心(1、2),“柯”,“markersize”15岁的“线宽”2)图(中心(2,1),中心(2,2),“kx”,“markersize”15岁的“线宽”, 2)
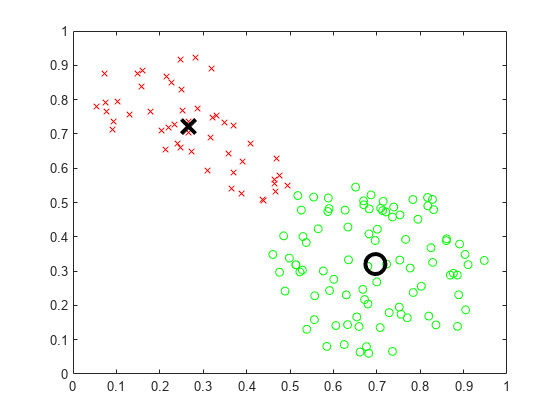
注意:每次运行此示例时,fcm函数用不同的初始条件初始化。此行为将交换计算和绘制集群中心的顺序。
另请参阅
相关的话题
您也可以从以下列表中选择一个网站: