从桌面扩展到集群
这个示例展示了如何在本地机器上开发并行MATLAB®代码,并将其扩展到集群。集群提供了更多的计算资源来加速和分布您的计算。您可以在本地机器上并行交互式地运行代码,然后在集群上运行,而无需更改代码。在本地机器上完成代码原型之后,可以使用批处理作业将计算卸载到集群。你可以关闭MATLAB,稍后再检索结果。
开发你的算法
首先在本地机器上创建算法原型。该示例使用整数因式分解作为示例问题。这是一个计算密集型问题,因式分解的复杂性随着数字的大小而增加。您使用一个简单的算法来分解整数序列。
创建一个64位精度的质数向量,并将质数对随机相乘以获得较大的合数。创建一个数组来存储每个分解的结果。本例中以下每个部分中的代码可能需要超过20分钟的时间。为了提高速度,可以通过使用更少的质数来减少工作负载,例如2 ^ 19.运行2 ^ 21看看最终的最佳方案。
primeNumbers =质数(uint64(2^21));compositeNumbers = primeNumbers.*primeNumbers(randperm(numel(primeNumbers)));factors = 0 (number (primeNumbers),2);
使用循环分解每个合数,并测量计算所需的时间。
抽搐;为idx = 1:numel(compositeNumbers) factors(idx,:) = factor(compositeNumbers(idx));结束toc
运行时间为684.464556秒。
在本地并行池上运行代码
并行计算工具箱™使您能够通过在并行池中的多个工作上运行来扩展您的工作流。前面的迭代为循环是独立的,所以你可以使用parfor循环将迭代分发给多个工作者。简单地转换你的为循环成parfor循环。然后,运行代码并测量总体计算时间。代码在一个并行池中运行,没有进一步的更改,工作线程将您的计算发送回本地工作空间。由于工作负载分布在多个工作人员之间,因此计算时间较短。
抽搐;parforidx = 1:numel(compositeNumbers) factors(idx,:) = factor(compositeNumbers(idx));结束toc
运行时间为144.550358秒。
当你使用parfor你有并行计算工具箱,MATLAB自动启动一个并行工作池。并行池启动需要一些时间。这个示例显示了池已经启动的第二次运行。
默认的集群配置文件为“本地”.您可以在MATLAB中检查该配置文件是否已设置为默认值首页选项卡,在平行>选择默认集群.启用此配置文件后,MATLAB将在您的机器上为并行池创建工作线程。当你使用“本地”配置文件,MATLAB,在默认情况下,启动与机器中的物理核心一样多的工作,直到您喜欢的工作数。您可以使用并行首选项控制并行行为。关于MATLAB首页选项卡上,选择平行>平行的偏好.
要用工作人员的数量来衡量加速,可以多次运行相同的代码,限制工作人员的最大数量。首先,定义每次运行的工作人员的数量,直到池中工作人员的数量,并创建一个数组来存储每个测试的结果。
numWorkers = [1 2 4 6];tLocal = 0 (size(numWorkers));
使用循环遍历最大工人数量,并运行前面的代码。要限制工作人员的数量,请使用第二个输入参数parfor.
为w = 1:数字(numWorkers) tic;parfor(idx = 1: number (compositeNumbers), numWorkers(w)) factors(idx,:) = factor(compositeNumbers(idx));结束tLocal(w) = toc;结束
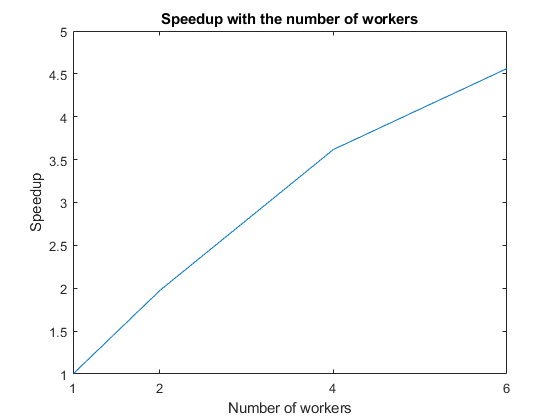
通过计算单个工人的计算时间与每个最大工人数量的计算时间之比来计算加速。为了可视化计算如何随着工人数量的增加而增加,可以将加速与工人数量画在一起。观察速度随着工人数量的增加而增加。然而,由于与并行化相关的开销,伸缩并不完美。
F =数字;speedup = tLocal(1)./tLocal;情节(numWorkers加速);标题(“随着工人数量的增加而加速”);包含(“工人人数”);xticks (numWorkers);ylabel (“加速”);
计算完成后,删除当前的并行池,以便为集群创建一个新的并行池。可以通过命令获取当前的并行池gcp函数。
删除(gcp);
设置集群
如果您的计算任务对本地计算机来说太大或太慢,您可以将计算卸载到现场集群或云中。在运行下一节之前,必须访问一个集群。关于MATLAB首页Tab,转到平行>发现集群以了解您是否已经使用MATLAB并行服务器™访问了集群。有关更多信息,请参见发现集群.
如果您没有访问某个集群的权限,则必须配置对该集群的访问权限,然后才能运行下面的部分。在MATLAB中,您可以直接从MATLAB Desktop在云服务(如Amazon AWS)中创建集群。在首页选项卡,在平行菜单中,选择创建和管理集群.在“集群配置文件管理器”中,单击创建云集群.要了解有关扩展到云的更多信息,请参见开始使用云中心.有关在网络中扩展到集群的选项的详细信息,请参见开始使用MATLAB并行服务器(MATLAB并行服务器).
设置集群概要文件后,可以在平行>创建和管理集群.有关更多信息,请参见发现集群并使用集群概要文件.中的集群配置文件集群配置文件管理器:

在集群并行池上运行代码
如果您希望在默认情况下在集群中运行并行函数,请将集群概要文件设置为default平行>选择默认集群:
您还可以使用编程方法指定您的集群。方法中指定集群配置文件的名称,从而在集群中启动并行池parpool命令。在下面的代码中,替换MyCluster集群配置文件的名称。还要使用第二个输入参数指定工人的数量。
parpool (“MyCluster”, 64);
启动并行池(parpool)使用'MyCluster'配置文件…与64名员工相连。
与前面一样,通过多次运行相同的代码并限制最大工作者数量来测量加速。因为这个例子中的集群允许比本地设置更多的工作人员,numWorkers可以容纳更多的值。如果运行此代码,则parfor循环现在在集群中运行。
numWorkers = [1 2 4 6 16 32 64];tCluster = 0 (size(numWorkers));为w = 1:数字(numWorkers) tic;parfor(idx = 1: number (compositeNumbers), numWorkers(w)) factors(idx,:) = factor(compositeNumbers(idx));结束tCluster(w) = toc;结束
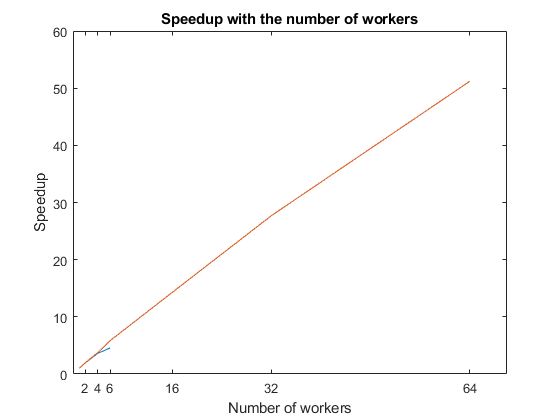
计算加速,并将其与工人数量绘制在一起,以可视化计算如何随着工人数量的增加而增加。将结果与本地设置的结果进行比较。观察速度随着工人数量的增加而增加。然而,由于与并行化相关的开销,伸缩并不完美。
图(f);持有在speedup = tCluster(1)./tCluster;情节(numWorkers加速);标题(“随着工人数量的增加而加速”);包含(“工人人数”);xticks (numWorkers(2:结束));ylabel (“加速”);
计算完成后,删除当前的并行池。
删除(gcp);
卸载和扩展您的计算批处理
在完成原型创建和交互式运行之后,可以使用批处理作业在后台卸载长时间运行的计算的执行。计算在集群中进行,您可以稍后关闭MATLAB并检索结果。
使用批处理函数向集群提交批处理作业。可以将算法的内容放在脚本中,并使用批处理函数提交。例如,脚本myParallelAlgorithm基于本例中所示的整数分解问题执行一个简单的基准测试。该脚本测量了几个复杂问题在不同工人数量下的计算时间。
请注意,如果发送脚本文件使用批处理, MATLAB将所有工作空间变量传输到集群,即使您的脚本不使用它们。如果您的工作空间很大,则会对数据传输时间产生负面影响。作为最佳实践,将脚本转换为函数文件以避免这种通信开销。只需在脚本开头添加一个函数行就可以做到这一点。学习如何转变myParallelAlgorithm到函数,参见myParallelAlgorithmFcn.
以下代码提交myParallelAlgorithmFcn作为批处理作业。myParallelAlgorithmFcn返回两个输出参数,numWorkers而且时间,并且必须指定2作为输入参数的输出数。因为代码需要一个并行池parfor循环,使用“池”名称-值对批处理指定工人的数量。集群使用一个额外的worker来运行函数本身。默认情况下,批处理将集群中工人的当前文件夹更改为MATLAB客户端的当前文件夹。控制当前文件夹可能很有用。例如,如果您的集群使用不同的文件系统,因此路径也不同,例如当您从Windows客户端计算机提交到Linux集群时。设置名称-值对“CurrentFolder”到您选择的文件夹,或者到“。”避免更改工作包的文件夹。
totalNumberOfWorkers = 65;Cluster = parcluster(“MyCluster”);作业=批处理(集群,“myParallelAlgorithmFcn”2,“池”totalNumberOfWorkers-1,“CurrentFolder”,“。”);
要在作业提交后监视作业的状态,请在中打开作业监视器平行>监控工作.当集群中开始计算时,作业的状态变为运行:
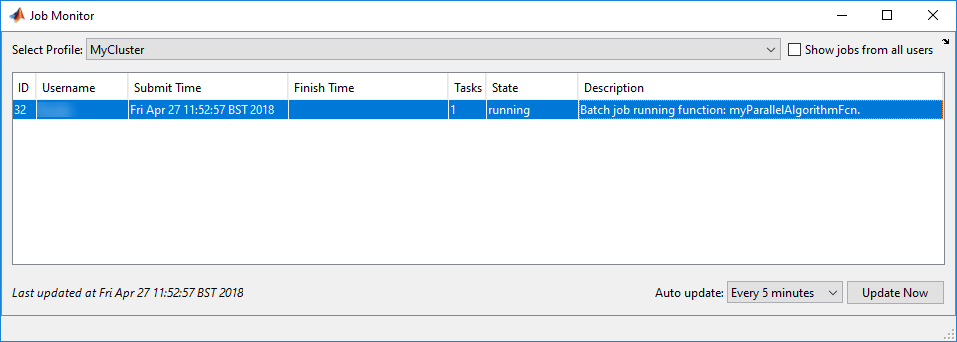
提交作业后,可以关闭MATLAB。当您再次打开MATLAB时,作业监视器会为您跟踪作业,如果您右键单击它,就可以与它进行交互。例如,要检索作业对象,请选择显示详细信息,要将批处理作业的输出传输到工作空间,请选择获取输出.

或者,如果希望阻塞MATLAB直到作业完成,请使用等待函数在作业对象上执行。
等待(工作);
若要从群集传输函数的输出,请使用fetchOutputs函数。
输出= fetchOutputs(作业);numWorkers =输出{1};时间=输出{2};
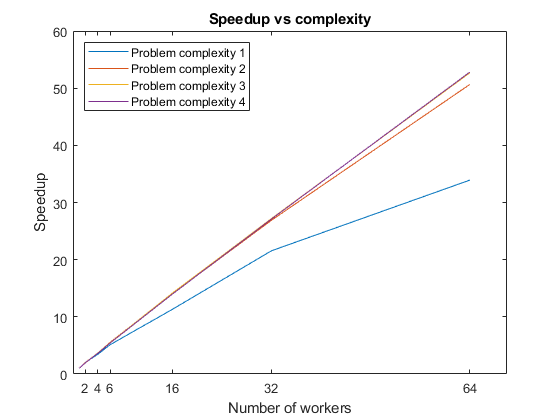
检索结果后,可以在本地计算机上使用它们进行计算。计算加速,并绘制它与工人数量的关系。因为代码对不同的问题复杂性运行因式分解,所以可以得到每个层次的图。您可以看到,对于每一个复杂的问题,加速都会随着工作人员数量的增加而增加,直到额外工作人员的开销大于并行化带来的性能收益。随着问题复杂性的增加,可以在大量工作人员的情况下获得更好的加速,因为与并行化相关的开销不那么显著。
图speedup = time(1,:)./time;情节(numWorkers加速);传奇(“问题复杂性1”,“问题复杂性2”,“问题复杂性3”,“问题复杂性4”,“位置”,“西北”);标题(“加速vs复杂”);包含(“工人人数”);xticks (numWorkers(2:结束));ylabel (“加速”);
另请参阅
parpool|parfor|批处理|fetchOutputs(工作)
相关的例子
更多关于
- 并行for循环(parfor)
- 开始使用MATLAB并行服务器(MATLAB并行服务器)
您也可以从以下列表中选择一个网站: