评估回归神经网络性能
创建具有全连接层的前馈回归神经网络模型fitrnet.使用验证数据提前停止训练过程,以防止模型过拟合。然后,利用模型的对象函数评估模型在测试数据上的性能。
加载样例数据
加载carbig数据集,其中包含20世纪70年代和80年代初生产的汽车的测量数据。
负载carbig
转换起源变量转换为分类变量。然后创建一个包含预测变量的表加速度,位移,等等,以及响应变量英里/加仑.每一行包含一辆车的测量值。删除表中缺少值的行。
Origin = categorical(cellstr(Origin));Tbl = table(加速度,位移,马力,...Model_Year、产地、重量、MPG);Tbl = rmmissing(Tbl);
对数据进行分区
将数据分成训练集、验证集和测试集。首先,为测试集保留大约三分之一的观测值。然后,将剩下的数据分成两半以创建训练集和验证集。
rng (“默认”)用于数据分区的再现性cvp1 = cvpartition(size(Tbl,1),“坚持”, 1/3);testTbl = Tbl(test(cvp1),:);remainingTbl = Tbl(训练(cvp1),:);cvp2 = cvpartition(size(remainingTbl,1)“坚持”1/2);validationTbl = remainingTbl(test(cvp2),:);trainTbl = remainingTbl(training(cvp2),:);
训练神经网络
利用训练集训练回归神经网络模型。指定英里/加仑列的tblTrain作为响应变量,并对数值预测器进行标准化。在每个迭代中使用验证集评估模型。控件在每次迭代中显示训练信息详细的名称-值参数。默认情况下,如果验证损失大于或等于迄今为止计算的最小验证损失,连续六次,则训练过程提前结束。要更改允许验证损失大于或等于最小值的次数,请指定ValidationPatience名称-值参数。
Mdl = fitrnet(trainTbl,“英里”,“标准化”,真的,...“ValidationData”validationTbl,...“详细”1);
|==========================================================================================| | 迭代| |火车损失梯度| | | |一步迭代验证验证 | | | | | | 时间(秒)| |检查损失 | |==========================================================================================| | 1 | 102.962345 | 46.853164 | 6.700877 | 0.016299 | 115.730384 | 0 | | 2 | 55.403995 | 22.171181 | 1.811805 | 0.008385 | 53.086379 | 0 | | 3 | 37.588848 | 11.135231 | 0.782861 | 0.002038 | 38.580002 | 0 | | 4 |29.713458| 8.379231| 0.392009| 0.000628 b| 31.021379| 0| | | 17.137584 | 0.000631| 17.594863 b| 0| | 6| 12.700624| | 0.744551| 0.000677| 14.209019| 0| | 7| 11.841152| 1.907378| 0.201770| 0.000656| 13.159899| 0| | 8| 10.162988| 2.542555| 0.576907| 0.000671| 11.352490| 0| | 9| 8.889095| 2.779980| 0.615716| 0.000691| 2.400272| 0.648711| 0.000731| 10.424337| 0||==========================================================================================| | 迭代| |火车损失梯度| | | |一步迭代验证验证 | | | | | | 时间(秒)| |检查损失 | |==========================================================================================| | 11 | 7.416274 | 0.505111 | 0.214707 | 0.001852 | 10.522517 | 1 | | 12 | 7.338923 | 0.880655 | 0.119085 | 0.006082 | 10.648031 | 2 | | 13 | 7.149407 | 1.784821 | 0.277908 | 0.000758 | 10.800952 | 3 | | 14 |6.866385| 1.904480| 0.472190| 0.017130| 10.839202| 3.339285| 0.943063| 0.000843| 10.031692 b| 0| | 16| 6.428137| 0.684771| 0.133729| | 6.363299| 0.456606| 0.125363| 0.000895| 9.720076| 0| | 18| 6.289887| 0.742923| 0.152290| 0.005959| 6.215407| 0.964684| 0.183503| 0.000728| 20| 6.078333| 2.124971| 0.566948| 0.000711| 9.599573| 1||==========================================================================================| | 迭代| |火车损失梯度| | | |一步迭代验证验证 | | | | | | 时间(秒)| |检查损失 | |==========================================================================================| | 21日| 5.947923 | 1.217291 | 0.583867 | 0.000667 | 9.618400 | 2 | | 22 | 5.855505 | 0.671774 | 0.285123 | 0.000656 | 9.734680 | 3 | | 23 | 5.831802 | 1.882061 | 0.657368 | 0.001645 | 10.365968 | 4 | | 24 |5.713261 | 1.004072 | 0.134719 | 0.001154 | 10.314258 | 5 | | 25 | 5.520766 | 0.967032 | 0.290156 | 0.000704 | 10.177322 | 6 | |==========================================================================================|
中的信息TrainingHistory对象的属性Mdl来检查与最小验证均方误差(MSE)对应的迭代。最终返回的模型Mdl在此迭代中训练的模型。
迭代= Mdl.TrainingHistory.Iteration;valLosses = mll . traininghistory . validationloss;[~,minIdx] = min(valLosses);迭代(minIdx)
Ans = 19
评估测试集性能
评估训练模型的性能Mdl在测试集中testTbl通过使用损失而且预测对象的功能。
计算测试集均方误差(MSE)。MSE值越小,性能越好。
mse = loss(Mdl,testTbl,“英里”)
Mse = 7.4101
将预测测试集响应值与真实响应值进行比较。纵轴表示预测每加仑英里数(MPG),横轴表示实际MPG。参考线上的点表示正确的预测。一个好的模型产生的预测分布在这条线附近。
predictedY = predict(Mdl,testTbl);情节(testTbl。英里/加仑,预测edY,“。”)举行在情节(testTbl.MPG testTbl.MPG)从包含(“每加仑英里数(MPG)”) ylabel (“预测每加仑英里数(MPG)”)

使用箱形图按原产国比较预测和真实MPG值的分布。控件创建框状图boxchart函数。每个箱形图显示中值、下四分位数和上四分位数、任何异常值(使用四分位数范围计算)以及非异常值的最小值和最大值。具体来说,每个框内的线是样本中值,圆形标记表示异常值。
对于每个原产国,将红盒图(显示预测MPG值的分布)与蓝盒图(显示真实MPG值的分布)进行比较。预测MPG值与实际MPG值的分布相似,表明预测结果良好。
boxchart (testTbl.Origin testTbl.MPG)在boxchart (testTbl.Origin predictedY)从传奇([“真正的MPG”,“预测MPG”])包含(“原产国”) ylabel (每加仑英里数(MPG))
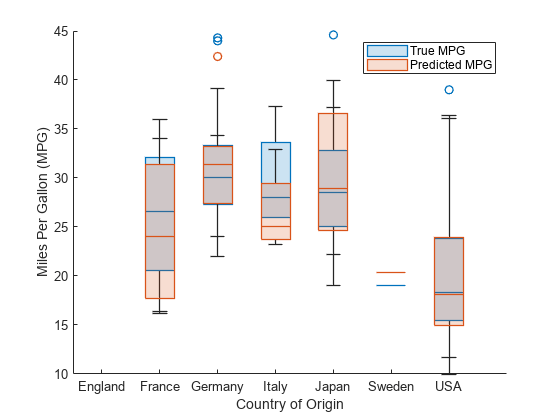
对于大多数国家,预测的和真实的MPG值具有相似的分布。有些差异可能是由于训练和测试集中的汽车数量较少。
比较训练集和测试集中汽车的MPG值范围。
trainSummary = grpstats(trainTbl(:,[“英里”,“起源”]),“起源”,...“范围”)
trainSummary =6×3表来源GroupCount range_MPG _______ __________ _________法国法国2 1.2德国德国12 23.4意大利意大利10日本日本26 26.6瑞典瑞典4 8美国美国86 27
testSummary = grpstats(testTbl(:,[“英里”,“起源”]),“起源”,...“范围”)
testSummary =6×3表来源GroupCount range_MPG _______ __________ _________法国法国4 19.8德国德国13 20.3意大利意大利4 11.3日本日本26 25.6瑞典瑞典10美国美国82 29
对于像法国、意大利和瑞典这样的国家,在训练和测试集中很少有汽车,MPG值的范围在两个集中都有很大差异。
绘制测试集残差。一个好的模型通常有残差大致对称地分散在0附近。残差中清晰的模式表明你可以改进你的模型。
残差= testTbl。MPG -可预测;情节(testTbl。英里/加仑,residuals,“。”)举行在yline (0)从包含(“每加仑英里数(MPG)”) ylabel (“MPG残差”)
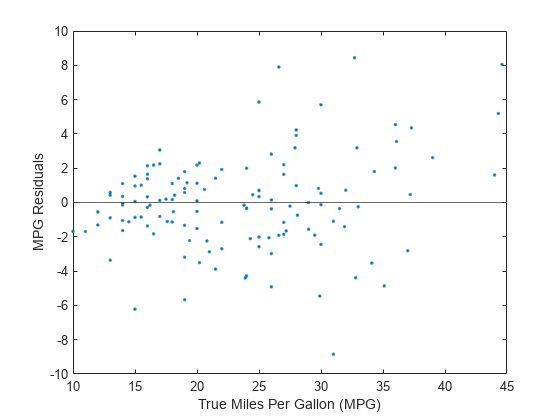
图中显示残差分布良好。
你可以获得关于残差绝对值最大的观测值的更多信息。
[~,residualIdx] = sort(残差,“下”,...“ComparisonMethod”,“abs”);残差(residualIdx)
ans =130×1-8.8469 8.4427 8.0493 7.8996 -6.2220 5.8589 5.7007 -5.6733 -5.4545 5.1899
显示残差最大(即幅度大于8)的三个观测值。
testTbl (residualIdx (1:3),:)
ans =表3×7加速度位移马力型号年份原产地重量MPG ____________ ____________ __________ __________ ____________ ____ 17.6 91 68 82日本1970 31 11.4 168 132 80日本2910 32.7 13.8 91 67 80日本1850 44.6
另请参阅
您也可以从以下列表中选择一个网站: